Github 项目 - 百度语义分割库PaddleSeg - AIUAI
这里基于 PaddleSeg 语义分割库,以 Oxford-IIIT Pet Dataset 宠物图像数据集和 U-Net 网络模型来实现宠物图像的分割示例.
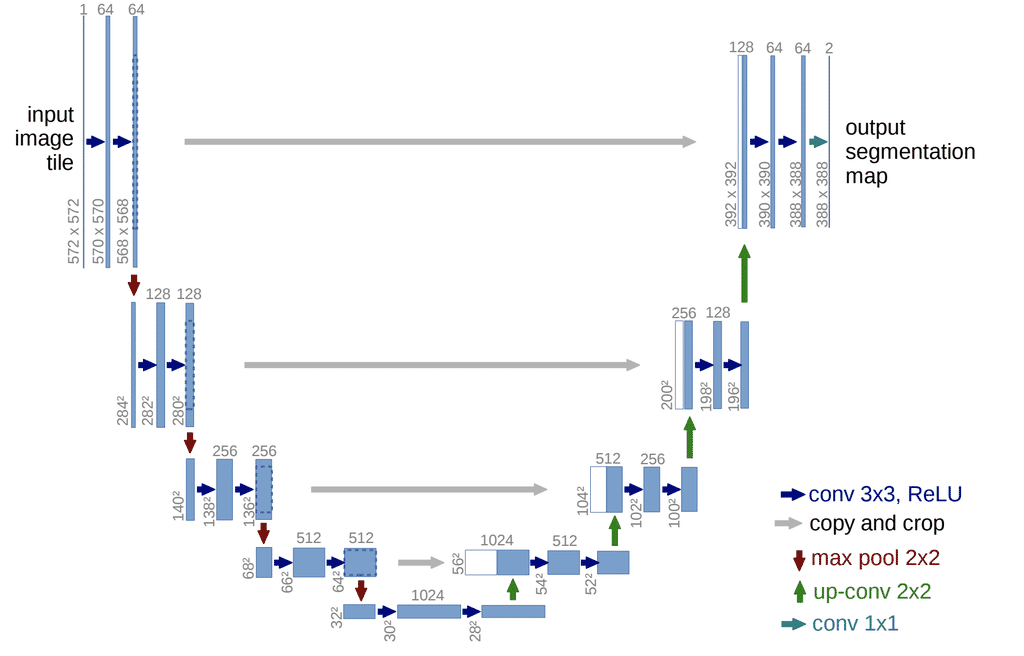
1. U-Net 网络结构
U-Net(U-Net: Convolutional Networks for Biomedical Image Segmentation)起源于医疗图像分割,整个网络是标准的encoder-decoder网络,特点是参数少,计算快,应用性强,对于一般场景适应度很高. U-Net最早于2015年提出,并在ISBI 2015 Cell Tracking Challenge取得了第一. 经过发展,目前有多个变形和应用.
原始U-Net的结构如下图所示,由于网络整体结构类似于大写的英文字母U,故得名U-net. 左侧可视为一个编码器,右侧可视为一个解码器. 编码器有四个子模块,每个子模块包含两个卷积层,每个子模块之后通过max pool进行下采样. 由于卷积使用的是valid模式,故实际输出比输入图像小一些. 具体来说,后一个子模块的分辨率=(前一个子模块的分辨率-4)/2. U-Net使用了Overlap-tile 策略用于补全输入图像的上下信息,使得任意大小的输入图像都可获得无缝分割. 同样解码器也包含四个子模块,分辨率通过上采样操作依次上升,直到与输入图像的分辨率基本一致. 该网络还使用了跳跃连接,以拼接的方式将解码器和编码器中相同分辨率的feature map进行特征融合,帮助解码器更好地恢复目标的细节.
2. Oxford-IIIT Pet Dataset
Oxford-IIIT Pet Dataset 是一个宠物图像数据集,包含37种宠物类别,其中有12种猫的类别和25种狗的类别,每个类别大约有200张图片.

这里采用 PaddleSeg 提供的例示数据集,从原始图像数据集中抽取了200张图片,其中训练集、验证集和测试集的数目为120,40,40.
下载数据集 - dataset/download_pet.py:
cd PaddleSeg_ROOT/
python dataset/download_pet.py数据集将存放在 ./dataset 下,该目录是 PaddleSeg 默认的数据集存储目录.
Oxford-IIIT Pet Dataset中共有3类标签:1代表前景;2代表背景;3代表未分类. PaddleSeg支持0~255共256类标签,其中255类别表示ignore,即在训练阶段不会使用该像素进行学习,默认以0开始标注类别. 而Oxford-IIIT Pet Dataset是以1开始标注,下载的例示数据集中已进行标签转换,使数据集以1开始标注类别,符合PaddleSeg格式.
3. 模型训练
3.1. 预训练模型下载
在COCO数据集上预训练的U-Net模型.
download_pretrained_unet.sh 模型下载脚本:
#!/bin/bash
# Helper function of download and uncompress file
download_and_uncompress() {
local BASE_URL=${1}
local FILENAME=${2}
if [ ! -f "${FILENAME}" ]; then
echo "Downloading ${FILENAME} to $(pwd)"
wget "${BASE_URL}/${FILENAME}" --no-check-certificate
fi
echo "Uncompressing ${FILENAME}"
tar --extract --file "${FILENAME}"
echo "${FILENAME} uncompressed!"
}
# Download test model
if [ ! -d "pretrained_model" ]; then
mkdir pretrained_model
fi
cd pretrained_model/
BASE_URL="https://paddleseg.bj.bcebos.com/models"
FILENAME="unet_coco_init.tgz"
download_and_uncompress $BASE_URL $FILENAME将下载的预训练模型放在 ./pretrained_model/unet_coco_init/ 目录.
3.1. 模型训练
PaddleSeg 中关于模型的配置记录在yaml文件里.
configs 文件夹用于存放各个模型的yaml文件,里面预先已有一些公开数据集的yaml文件.
pretrained_model 文件夹用于存放各个预训练模型.
在Oxford-IIIT Pet数据集上对预训练UNet模型进行fine tunine 时,采用 train.py 模型训练脚本,实际中可能会遇到如下两种情况:
[1] - 如果需要修改大量参数,建议另外再编写一个yaml文件,然后传给--cfg,这种做法适合需要长期、大量进行改动的情况,例如更换数据集. 如:
python ./pdseg/train.py --cfg ./configs/unet_pet.yaml[2] - 如果只是临时对少量参数进行更改,建议在命令行直接对相应参数进行赋值,这种做法适合短期、少量、频繁进行改动的情况. 如:
python ./pdseg/train.py --cfg ./configs/unet_pet.yaml \
--use_gpu \
SOLVER.NUM_EPOCHS 3 \
TRAIN.PRETRAINED_MODEL_DIR "pretrained_model/unet_coco_init/" \
TRAIN.MODEL_SAVE_DIR "snapshots/unet_pet/"常用参数说明:
| 参数 | 含义 |
|---|---|
| --cfg | 指定yaml配置文件路径 |
| --use_gpu | 是否启用gpu |
| --use_mpio | 是否开启多进程 |
| BATCH_SIZE | 批处理大小 |
| TRAIN_CROP_SIZE | 训练时图像裁剪尺寸(宽,高) |
| TRAIN.PRETRAINED_MODEL_DIR | 预训练模型路径 |
| TRAIN.MODEL_SAVE_DIR | 模型保存路径 |
| TRAIN.SYNC_BATCH_NORM | 是否使用多卡间同步BatchNorm均值和方差,默认False |
| MODEL.DEFAULT_NORM_TYPE | BatchNorm类型: bn(batch_norm)、gn(group_norm) |
| SOLVER.LR | 初始学习率 |
| SOLVER.NUM_EPOCHS | 训练epoch数,正整数 |
| SOLVER.LR_POLICY | 学习率下降方法, 选项为poly、piecewise和cosine |
| SOLVER.OPTIMIZER | 优化算法, 选项为sgd和adam |
全部详细的参数说明,可以参考pdseg/utils/config.py文件 或者运行:
python pdseg/train.py --help注意事项:
[1] - PaddleSeg中共有三处可设置模型参数:
- 命令窗口传递的参数.
- configs 目录下的yaml文件.
- pdseg/utils/config.py.
对于相同的参数,传递的优先级为:命令窗口 > yaml文件 > config.py. 即同一个参数,优先级较高的将覆盖掉优先级较低的.
[2] - 若没有 gpu 计算资源,则需要在训练、验证、测试脚本中删除参数 --use_gpu.
[3] - 在多GPU训练的情况下,建议开启TRAIN.SYNC_BATCH_NORM来提高分割精度.
这里采用的模型训练脚本如:
CUDA_VISIBLE_DEVICES=0 python ./pdseg/train.py \
--cfg ./configs/unet_pet.yaml \
--use_gpu \
TRAIN.PRETRAINED_MODEL_DIR "pretrained_model/unet_coco_init/" 输出如:

4. 模型评估
eval.py 为模型的评估脚本. 其使用如:
python ./pdseg/eval.py --cfg configs/unet_pet.yaml \
--use_gpu \
TEST.TEST_MODEL "./work/unet_pet_500/500/" \
EVAL_CROP_SIZE "(512, 512)"参数说明:
| 参数 | 含义 |
|---|---|
| TEST.TEST_MODEL | 指定要进行评估的模型,一般与训练时模型保存路径TRAIN.MODEL_SAVE_DIR保持一致 |
| EVAL_CROP_SIZE | 验证、预测时图像裁剪尺寸(宽,高) |
参数说明:
| 参数 | 含义 |
|---|---|
| TEST.TEST_MODEL | 指定要进行评估的模型,一般与训练时模型保存路径TRAIN.MODEL_SAVE_DIR保持一致 |
| EVAL_CROP_SIZE | 验证、预测时图像裁剪尺寸(宽,高) |
注意事项: EVAL_CROP_SIZE的设置要求分如下情况:
- 当
AUG.AUG_METHOD为unpadding时,EVAL_CROP_SIZE的宽高应不小于AUG.FIX_RESIZE_SIZE的宽高. - 当
AUG.AUG_METHOD为stepscaling时,EVAL_CROP_SIZE的宽高应不小于原图中最大的宽高. - 当
AUG.AUG_METHOD为rangscaling时,EVAL_CROP_SIZE的宽高应不小于缩放后图像中最大的宽高.
对于U-Net,需要特别留心EVAL_CROP_SIZE的设置,若设置过大,容易超出显存.
输出如:
load test model: ./work/unet_pet_500/500/
[EVAL]step=1 loss=1.10202 acc=0.8002 IoU=0.5991 step/sec=0.76 | ETA 00:00:13
[EVAL]step=2 loss=1.29934 acc=0.7881 IoU=0.5809 step/sec=2.95 | ETA 00:00:03
[EVAL]step=3 loss=0.67134 acc=0.8158 IoU=0.6202 step/sec=2.94 | ETA 00:00:02
[EVAL]step=4 loss=0.66226 acc=0.8288 IoU=0.6320 step/sec=3.00 | ETA 00:00:02
[EVAL]step=5 loss=0.73204 acc=0.8364 IoU=0.6370 step/sec=2.98 | ETA 00:00:02
[EVAL]step=6 loss=1.23880 acc=0.8290 IoU=0.6312 step/sec=2.98 | ETA 00:00:01
[EVAL]step=7 loss=2.01369 acc=0.8160 IoU=0.6161 step/sec=2.99 | ETA 00:00:01
[EVAL]step=8 loss=0.87948 acc=0.8187 IoU=0.6230 step/sec=3.04 | ETA 00:00:00
[EVAL]step=9 loss=0.68913 acc=0.8234 IoU=0.6312 step/sec=2.97 | ETA 00:00:00
[EVAL]step=10 loss=1.95106 acc=0.8166 IoU=0.6224 step/sec=3.00 | ETA 00:00:00
[EVAL]#image=40 acc=0.8166 IoU=0.6224
[EVAL]Category IoU: [0.6707 0.7910 0.4057]
[EVAL]Category Acc: [0.8198 0.8818 0.5554]
[EVAL]Kappa:0.68284.1. 模型评估指标
评估指标说明:
| 指标 | 含义 |
|---|---|
| acc | Mean Accuracy(平均准确率) |
| IoU | Mean Intersection over Union (MIoU,平均交并比) |
| Category IoU | 每个类别的IoU指标 |
| Category Acc | 每个类别的Accuracy指标 |
| Kappa | Kappa系数是一个用于一致性检验的指标,可以衡量分类或分割的效果. 取值范围为[-1,1],越趋近于1,说明分类或分割的效果越好. |
5. 模型预测与可视化
vis.py 为模型预测和可视化脚本. 其使用如:
python ./pdseg/vis.py --cfg configs/unet_pet.yaml \
--vis_dir visual/unet_pet \
--use_gpu \
TEST.TEST_MODEL ./work/unet_pet_500/500/ \
EVAL_CROP_SIZE "(512, 512)"参数说明:
| 参数 | 含义 |
|---|---|
| --vis_dir | 指定预测结果图片存放位置 |
| EVAL_CROP_SIZE | 验证、预测时图像裁剪尺寸(宽,高) |
显示最终的分割效果:
import matplotlib.pyplot as plt
# 定义显示函数
def display(img_dir):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'Predicted Mask']
for i in range(len(title)):
plt.subplot(1, len(img_dir), i+1)
plt.title(title[i])
img = plt.imread(img_dir[i])
plt.imshow(img)
plt.axis('off')
plt.show()
# 显示分割效果
# 注:这里仅显示其中一张图片的效果.
image_dir = "dataset/mini_pet/images/Abyssinian_24.jpg"
mask_dir = "visual/unet_pet/visual_results/Abyssinian_24.png"
imgs = [image_dir, mask_dir]
display(imgs)如图:
