Github - PaddleSeg
百度最新开源了一个强大的语义分割库 - PaddleSeg.
PaddleSeg 是基于PaddlePaddle开发的语义分割库,覆盖了DeepLabv3+, U-Net, ICNet三类主流的分割模型. 通过统一的配置,可以更便捷地完成从训练到部署的全流程图像分割应用.
PaddleSeg具备高性能、丰富的数据增强、工业级部署、全流程应用的特点:
[1] - 丰富的数据增强
基于百度视觉技术部的实际业务经验,内置10+种数据增强策略,可结合实际业务场景进行定制组合,提升模型泛化能力和鲁棒性.
[2] - 主流模型覆盖
支持U-Net, DeepLabv3+, ICNet三类主流分割网络,结合预训练模型和可调节的骨干网络,满足不同性能和精度的要求.
[3] - 高性能
PaddleSeg支持多进程IO、多卡并行、跨卡Batch Norm同步等训练加速策略,结合飞桨核心框架的显存优化功能,可以大幅度减少分割模型的显存开销,更快完成分割模型训练.
[4] - 工业级部署
基于Paddle Serving和PaddlePaddle高性能预测引擎,结合百度开放的AI能力,轻松搭建人像分割和车道线分割服务.
PaddleSeg 全景图:

目前,PaddleSeg 已经在百度无人车、AI 开放平台人像分割、小度 P 图和百度地图等多个产品线上应用或实践,在工业质检行业也已经取得了很好的效果.
1. 简单安装
环境要求:
- PaddlePaddle >= 1.5.2
- Python 2.7 or 3.5+
[1] - PaddlePaddle 安装:
PaddlePaddle安装说明
pip install paddlepaddle-gpu[2] - 下载使用 PaddleSeg 代码:
git clone https://github.com/PaddlePaddle/PaddleSeg
cd PaddleSeg/
pip install -r requirements.txt2. 分割模型
语义分割顾名思义是将图像像素按照表达的语义含义的不同进行分组/分割,图像语义是指对图像内容的理解,例如,能够描绘出什么物体在哪里做了什么事情等,分割是指对图片中的每个像素点进行标注,标注属于哪一类别.
近年来用在无人车驾驶技术中分割街景来避让行人和车辆、医疗影像分析中辅助诊断等.
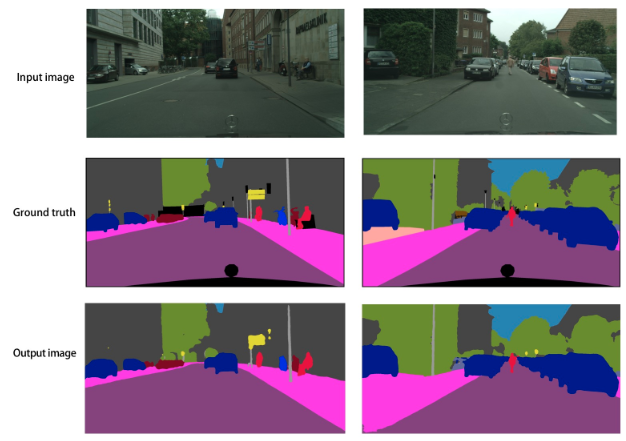
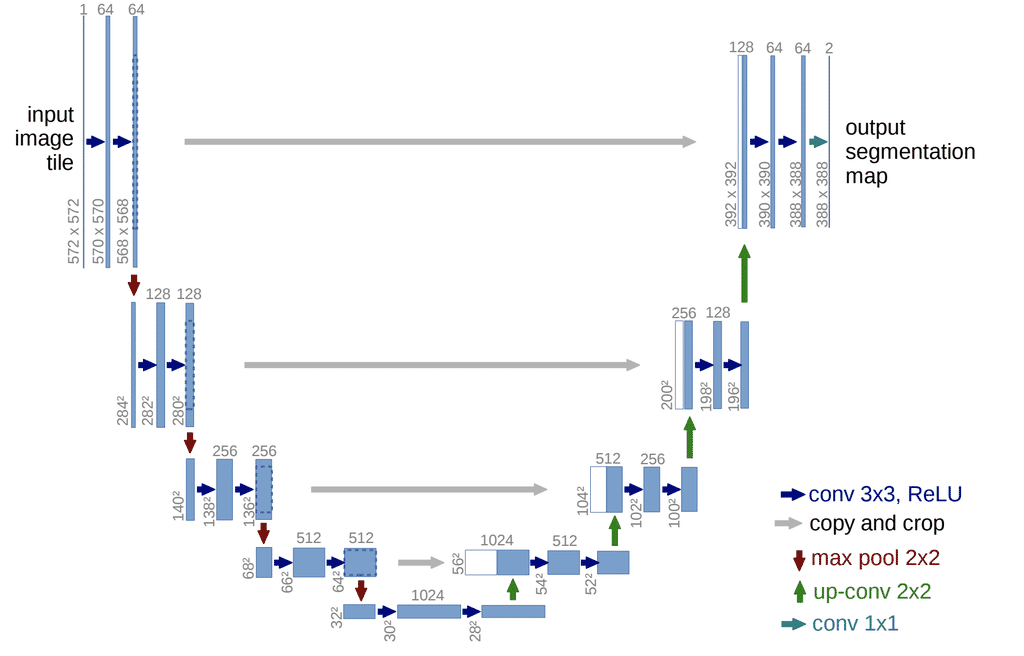
2.1. U-Net
U-Net: Convolutional Networks for Biomedical Image Segmentation
U-Net 起源于医疗图像分割,整个网络是标准的encoder-decoder网络,特点是参数少,计算快,应用性强,对于一般场景适应度很高.
2.2. DeepLabv3+
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
DeepLabv3+ 是DeepLab系列的最后一篇文章,其前作有 DeepLabv1,DeepLabv2, DeepLabv3, 在最新作中,DeepLab的作者通过encoder-decoder进行多尺度信息的融合,同时保留了原来的空洞卷积和ASSP层, 其骨干网络使用了Xception模型,提高了语义分割的健壮性和运行速率,在 PASCAL VOC 2012 dataset取得新的state-of-art performance,89.0mIOU.
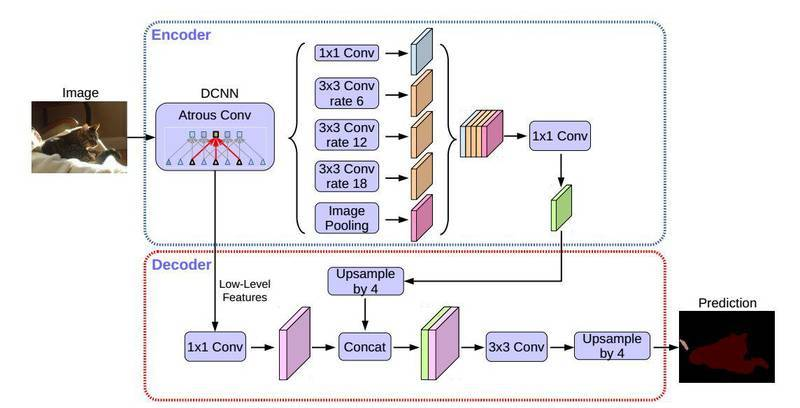
在PaddleSeg当前实现中,支持两种分类Backbone网络的切换
- MobileNetv2: 适用于移动设备的快速网络,如果对分割性能有较高的要求,请使用这一backbone网络.
- Xception: DeepLabv3+原始实现的backbone网络,兼顾了精度和性能,适用于服务端部署.
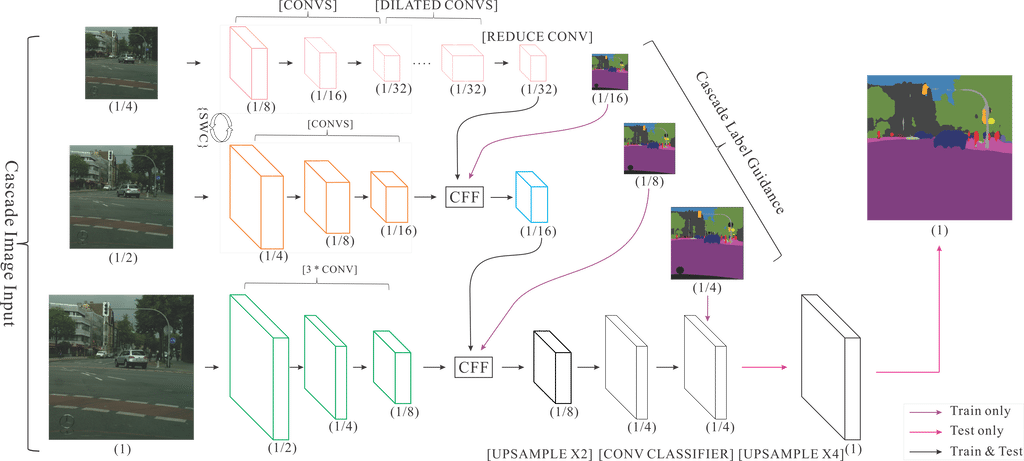
2.3. ICNet
ICNet for Real-Time Semantic Segmentation on High-Resolution Images
Image Cascade Network(ICNet)主要用于图像实时语义分割. 相较于其它压缩计算的方法,ICNet即考虑了速度,也考虑了准确性. ICNet的主要思想是将输入图像变换为不同的分辨率,然后用不同计算复杂度的子网络计算不同分辨率的输入,然后将结果合并. ICNet由三个子网络组成,计算复杂度高的网络处理低分辨率输入,计算复杂度低的网络处理分辨率高的网络,通过这种方式在高分辨率图像的准确性和低复杂度网络的效率之间获得平衡.
整个网络结构如下:
3. PaddleSeg特殊网络结构
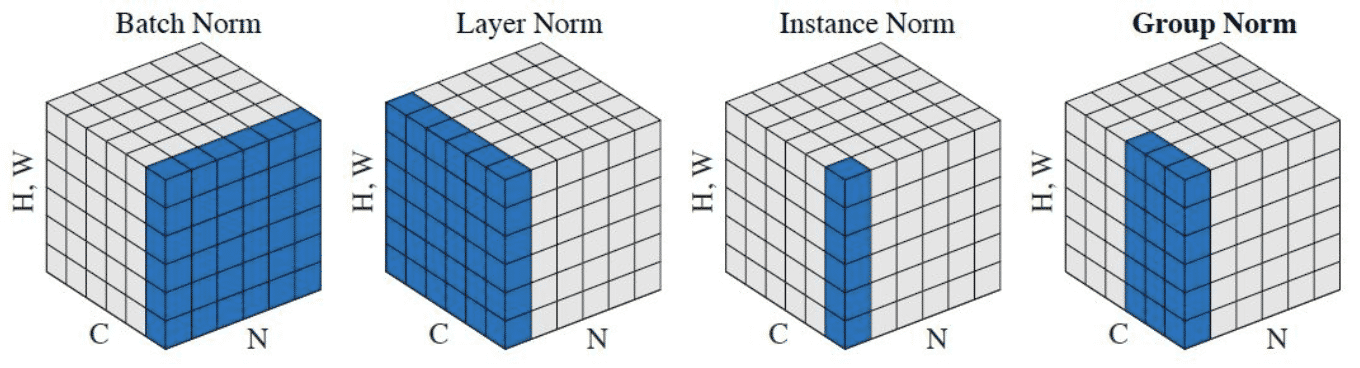
3.1. Group Norm
Group Norm 参考论文:https://arxiv.org/abs/1803.08494
GN 把通道分为组,并计算每一组之内的均值和方差,以进行归一化. GN 的计算与批量大小无关,其精度也在各种批量大小下保持稳定. 适应于网络参数很重的模型,比如deeplabv3+这种,可以在一个小batch下取得一个较好的训练效果.
3.2. Synchronized Batch Norm
Synchronized Batch Norm跨GPU批归一化策略最早在 MegDet: A Large Mini-Batch Object Detector 论文中提出,在Bag of Freebies for Training Object Detection Neural Networks论文中以Yolov3验证了这一策略的有效性,PaddleCV/yolov3 实现了这一系列策略并比Darknet框架版本在COCO17数据上mAP高5.9.
PaddleSeg基于PaddlePaddle框架的sync_batch_norm策略,可以支持通过多卡实现大batch size的分割模型训练,可以得到更高的mIoU精度.
4. ModelZoo
https://github.com/PaddlePaddle/PaddleSeg/blob/master/docs/model_zoo.md
4.1. ImageNet预训练模型
所有Imagenet预训练模型来自于PaddlePaddle图像分类库,更多细节参见 PaddleCV/image_classification.
| 模型 | 数据集合 | Depth multiplier | 下载地址 | Accuray Top1/5 Error |
|---|---|---|---|---|
| MobieNetV2_1.0x | ImageNet | 1.0x | MobileNetV2_1.0x | 72.15%/90.65% |
| MobieNetV2_0.25x | ImageNet | 0.25x | MobileNetV2_0.25x | 53.21%/76.52% |
| MobieNetV2_0.5x | ImageNet | 0.5x | MobileNetV2_0.5x | 65.03%/85.72% |
| MobieNetV2_1.5x | ImageNet | 1.5x | MobileNetV2_1.5x | 74.12%/91.67% |
| MobieNetV2_2.0x | ImageNet | 2.0x | MobileNetV2_2.0x | 75.23%/92.58% |
可以结合实际场景的精度和预测性能要求,选取不同 Depth multiplier 参数的MobileNet模型.
| 模型 | 数据集合 | 下载地址 | Accuray Top1/5 Error |
|---|---|---|---|
| Xception41 | ImageNet | Xception41_pretrained.tgz | 79.5%/94.38% |
| Xception65 | ImageNet | Xception65_pretrained.tgz | 80.32%/94.47% |
| Xception71 | ImageNet | coming soon | -- |
4.2. COCO预训练模型
数据集为COCO实例分割数据集合转换成的语义分割数据集合
| 模型 | 数据集合 | 下载地址 | Output Strid | multi-scale test | mIoU |
|---|---|---|---|---|---|
| DeepLabv3+/MobileNetv2/bn | COCO | deeplab_mobilenet_x1_0_coco.tgz | 16 | -- | -- |
| DeeplabV3+/Xception65/bn | COCO | xception65_coco.tgz | 16 | -- | -- |
| U-Net/bn | COCO | unet_coco.tgz | 16 | -- | -- |
4.3. Cityscapes预训练模型
train数据集合为Cityscapes训练集合,测试为Cityscapes的验证集合
| 模型 | 数据集合 | 下载地址 | Output Stride | mutli-scale test | mIoU on val |
|---|---|---|---|---|---|
| DeepLabv3+/MobileNetv2/bn | Cityscapes | mobilenet_cityscapes.tgz | 16 | false | 0.698 |
| DeepLabv3+/Xception65/gn | Cityscapes | deeplabv3p_xception65_gn_cityscapes.tgz | 16 | false | 0.7824 |
| DeepLabv3+/Xception65/bn | Cityscapes | deeplabv3p_xception65_bn_cityscapes_.tgz | 16 | false | 0.7930 |
| ICNet/bn | Cityscapes | icnet_cityscapes.tgz | 16 | false | 0.6831 |
5. 与其它框架的对比
对比与其它框架,PaddleSeg 的多卡训练速度比对标产品快两倍,工业级部署能力,时间节省明显.
在速度方面,PaddleSeg 也提供了多进程的 I/O、优秀的显存优化策略,性能方面得以大大提升. PaddleSeg 的单卡训练速度是对标产品的 2.3 倍,多卡训练速度是对标产品的 3.1 倍.
与对标产品相比,PaddleSeg 在训练速度、GPU 利用率、显存开销和 Max Batch Size 等方面都有着非常显著的优势. 详细的对比数据如下图:
测试环境与模型:
● GPU: Nvidia Tesla V100 16G * 8
● CPU: Intel(R) Xeon(R) Gold 6148
● Model: DeepLabv3+ with Xception65 backbone

1 条评论
分享一个数据集 https://www.payititi.com/opendatasets/show/28/ 该数据集包含50,000张图像,这些图像带有带有19个语义人体部位标签的精细逐像素注释和具有16个关键点的2D人体姿势。