在语义分割的模型训练时,由于语义分割数据集的标注与收集难度比较大,因此往往需要借助数据增强策略进行处理.
1. PaddleSeg 数据增强基本流程
PaddleSeg 数据增强

1.1. Resize
resize 步骤是指将输入图像按照某种规则讲图片重新缩放到某一个尺寸.
PaddleSeg 支持以下3种resize方式:

[1] - Unpadding 将输入图像直接resize到某一个固定大小下,送入到网络中间训练,对应参数为AUG.FIX_RESIZE_SIZE. 预测时同样操作.
[2] - Step-Scaling 将输入图像按照某一个比例 resize,这个比例以某一个步长在一定范围内随机变动. 设定最小比例参数为AUG.MIN_SCALE_FACTOR, 最大比例参数AUG.MAX_SCALE_FACTOR,步长参数为AUG.SCALE_STEP_SIZE. 预测时不对输入图像做处理.
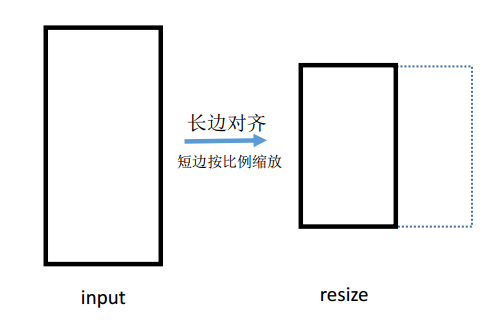
[3] - Range-Scaling 固定长宽比resize,即图像长边对齐到某一个固定大小,短边随同样的比例变化. 设定最小大小参数为AUG.MIN_RESIZE_VALUE,设定最大大小参数为AUG.MAX_RESIZE_VALUE. 预测时需要将长边对齐到AUG.INF_RESIZE_VALUE所指定的大小,其中AUG.INF_RESIZE_VALUE在AUG.MIN_RESIZE_VALUE和AUG.MAX_RESIZE_VALUE范围内.
Range-Scaling示意图如下:
1.2. Flip
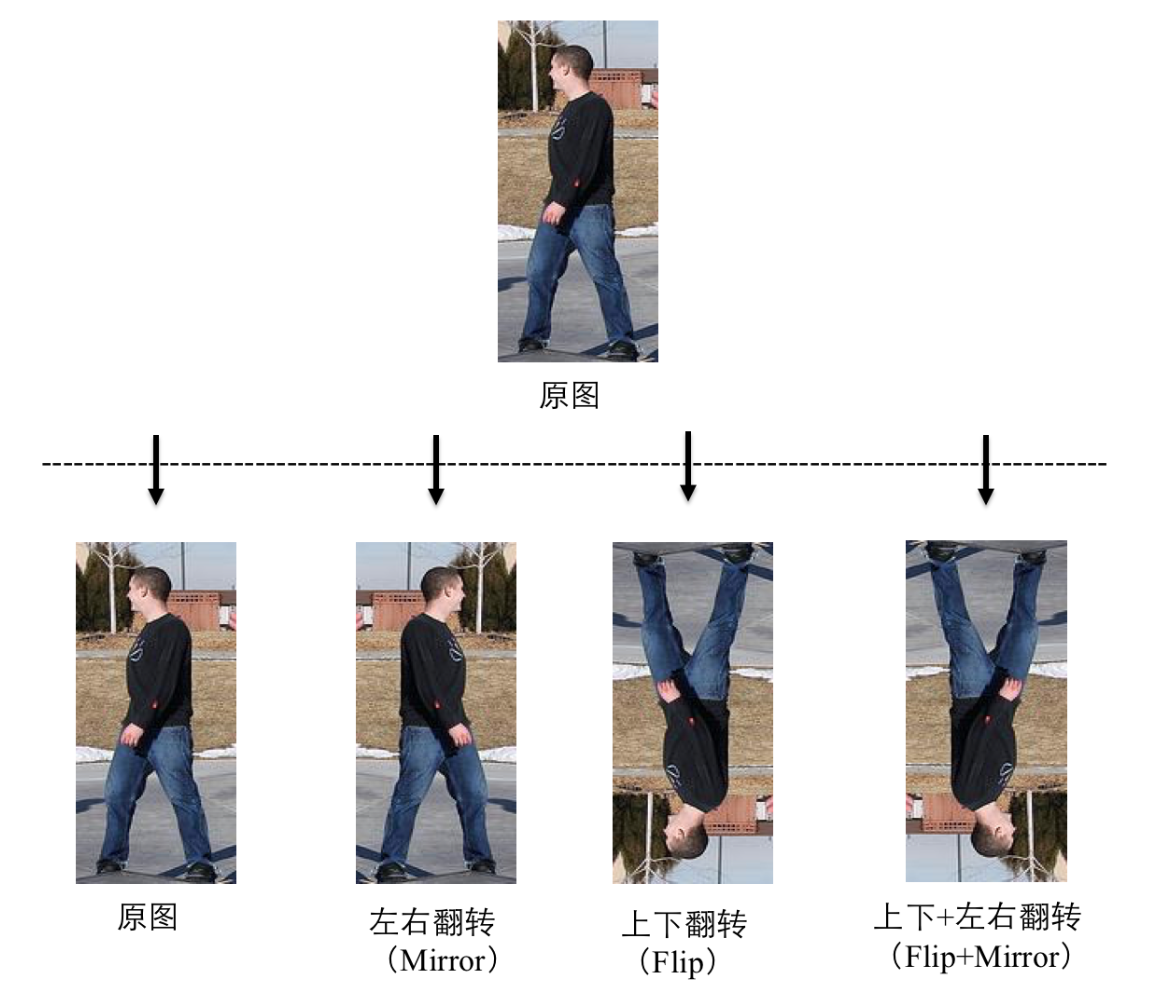
PaddleSeg支持以下2种翻转方式:
[1] - 左右翻转(Mirror) :AUG.MIRROR,为True时该功能开启,为False时该功能关闭.
[2] - 上下翻转(Flip) :AUG.FLIP,为True时该功能开启,AUG.FLIP_RATIO 控制是否上下翻转的概率. 为False时该项功能关闭.
二者可独立运作,也可组合使用. 故图像翻转一共有如下4种可能的情况:
1.3. Rich Crop
Rich Crop 是 PaddleSeg 结合实际业务经验开放的一套数据增强策略,面向标注数据少,测试数据情况繁杂的分割业务场景使用的数据增强策略. 流程如下图所示:
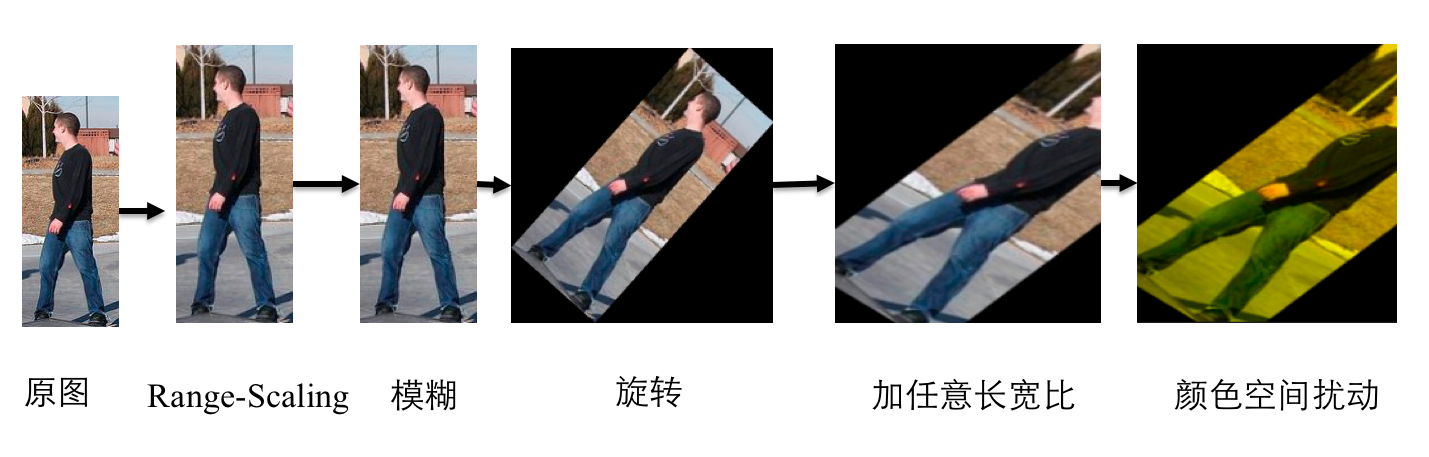
Rich crop 是指对图像进行多种变换,保证在训练过程中数据的丰富多样性,PaddleSeg支持以下几种变换. AUG.RICH_CROP.ENABLE为False时会直接跳过该步骤.
[1] - blur 图像加模糊,使用开关AUG.RICH_CROP.BLUR,为False时该功能关闭. AUG.RICH_CROP.BLUR_RATIO控制加入模糊的概率.
[2] - rotation 图像旋转,AUG.RICH_CROP.MAX_ROTATION控制最大旋转角度. 旋转产生的多余的区域的填充值为均值.
[3] - aspect 图像长宽比调整,从图像中crop一定区域出来之后在某一长宽比内进行resize. 控制参数AUG.RICH_CROP.MIN_AREA_RATIO和AUG.RICH_CROP.ASPECT_RATIO.
[4] - color jitter 图像颜色调整,控制参数AUG.RICH_CROP.BRIGHTNESS_JITTER_RATIO、AUG.RICH_CROP.SATURATION_JITTER_RATIO、AUG.RICH_CROP.CONTRAST_JITTER_RATIO.
1.4. Random Crop
该步骤主要是通过crop的方式使得输入到网络中的图像在某一个固定大小,控制该大小的参数为TRAIN_CROP_SIZE,类型为tuple,格式为(width, height). 当输入图像大小小于CROP_SIZE的时候会对输入图像进行padding,padding值为均值.
输入图片格式
原图
- 图片格式:RGB三通道图片和RGBA四通道图片两种类型的图片进行训练,但是在一次训练过程只能存在一种格式.
- 图片转换:灰度图片经过预处理后之后会转变成三通道图片
- 图片参数设置:当图片为三通道图片时IMAGE_TYPE设置为rgb, 对应MEAN和STD也必须是一个长度为3的list,当图片为四通道图片时IMAGE_TYPE设置为rgba,对应的MEAN和STD必须是一个长度为4的list.
标注图
- 图片格式:标注图片必须为png格式的单通道多值图,元素值代表的是这个元素所属于的类别.
- 图片转换:在datalayer层对label图片进行的任何resize,以及旋转的操作,都必须采用最近邻的插值方式.
- 图片ignore:设置TRAIN.IGNORE_INDEX 参数可以选择性忽略掉属于某一个类别的所有像素点. 这个参数一般设置为255
2. PaddlseSeg 数据增强定义
Github 项目 - PaddleSeg 模型训练 - 数据增强
## 数据增强配置 ##
# 图像镜像左右翻转
cfg.AUG.MIRROR = True
# 图像上下翻转开关,True/False
cfg.AUG.FLIP = False
# 图像启动上下翻转的概率,0-1
cfg.AUG.FLIP_RATIO = 0.5
# 图像resize的固定尺寸(宽,高),非负
cfg.AUG.FIX_RESIZE_SIZE = tuple()
# 图像resize的方式有三种:
# unpadding(固定尺寸),stepscaling(按比例resize),rangescaling(长边对齐)
cfg.AUG.AUG_METHOD = 'rangescaling'
# 图像resize方式为stepscaling,resize最小尺度,非负
cfg.AUG.MIN_SCALE_FACTOR = 0.5
# 图像resize方式为stepscaling,resize最大尺度,不小于MIN_SCALE_FACTOR
cfg.AUG.MAX_SCALE_FACTOR = 2.0
# 图像resize方式为stepscaling,resize尺度范围间隔,非负
cfg.AUG.SCALE_STEP_SIZE = 0.25
# 图像resize方式为rangescaling,训练时长边resize的范围最小值,非负
cfg.AUG.MIN_RESIZE_VALUE = 400
# 图像resize方式为rangescaling,训练时长边resize的范围最大值,
# 不小于MIN_RESIZE_VALUE
cfg.AUG.MAX_RESIZE_VALUE = 600
# 图像resize方式为rangescaling, 测试验证可视化模式下长边resize的长度,
# 在MIN_RESIZE_VALUE到MAX_RESIZE_VALUE范围内
cfg.AUG.INF_RESIZE_VALUE = 500
# RichCrop数据增广开关,用于提升模型鲁棒性
cfg.AUG.RICH_CROP.ENABLE = False
# 图像旋转最大角度,0-90
cfg.AUG.RICH_CROP.MAX_ROTATION = 15
# 裁取图像与原始图像面积比,0-1
cfg.AUG.RICH_CROP.MIN_AREA_RATIO = 0.5
# 裁取图像宽高比范围,非负
cfg.AUG.RICH_CROP.ASPECT_RATIO = 0.33
# 亮度调节范围,0-1
cfg.AUG.RICH_CROP.BRIGHTNESS_JITTER_RATIO = 0.5
# 饱和度调节范围,0-1
cfg.AUG.RICH_CROP.SATURATION_JITTER_RATIO = 0.5
# 对比度调节范围,0-1
cfg.AUG.RICH_CROP.CONTRAST_JITTER_RATIO = 0.5
# 图像模糊开关,True/False
cfg.AUG.RICH_CROP.BLUR = False
# 图像启动模糊百分比,0-1
cfg.AUG.RICH_CROP.BLUR_RATIO = 0.13. PaddlseSeg 数据增强配置
在 configs/xxx.yaml 中的使用配置,如 deeplabv3p_xception65.yaml:
AUG:
AUG_METHOD: "unpadding" # choice unpadding rangescaling and stepscaling
FIX_RESIZE_SIZE: (800, 800) # (width, height), for unpadding
INF_RESIZE_VALUE: 800 # for rangescaling
MAX_RESIZE_VALUE: 1200 # for rangescaling
MIN_RESIZE_VALUE: 600 # for rangescaling
MAX_SCALE_FACTOR: 1.25 # for stepscaling
MIN_SCALE_FACTOR: 0.75 # for stepscaling
SCALE_STEP_SIZE: 0.25 # for stepscaling
MIRROR: True4. PaddleSeg 数据增强实现
pdseg/data_aug.py
#!--*-- coding: utf8 --*--
from __future__ import print_function
import cv2
import numpy as np
from utils.config import cfg
from models.model_builder import ModelPhase
def resize(img, grt=None, mode=ModelPhase.TRAIN):
"""
改变图像及标签图像尺寸
AUG.AUG_METHOD为unpadding,所有模式均直接resize到AUG.FIX_RESIZE_SIZE的尺寸
AUG.AUG_METHOD为stepscaling, 按比例resize,训练时比例范围AUG.MIN_SCALE_FACTOR到AUG.MAX_SCALE_FACTOR,间隔为AUG.SCALE_STEP_SIZE,其他模式返回原图
AUG.AUG_METHOD为rangescaling,长边对齐,短边按比例变化,训练时长边对齐范围AUG.MIN_RESIZE_VALUE到AUG.MAX_RESIZE_VALUE,其他模式长边对齐AUG.INF_RESIZE_VALUE
Args:
img(numpy.ndarray): 输入图像
grt(numpy.ndarray): 标签图像,默认为None
mode(string): 模式, 默认训练模式,即ModelPhase.TRAIN
Returns:
resize后的图像和标签图
"""
if cfg.AUG.AUG_METHOD == 'unpadding':
target_size = cfg.AUG.FIX_RESIZE_SIZE
img = cv2.resize(img, target_size, interpolation=cv2.INTER_LINEAR)
if grt is not None:
grt = cv2.resize(grt, target_size, interpolation=cv2.INTER_NEAREST)
elif cfg.AUG.AUG_METHOD == 'stepscaling':
if mode == ModelPhase.TRAIN:
min_scale_factor = cfg.AUG.MIN_SCALE_FACTOR
max_scale_factor = cfg.AUG.MAX_SCALE_FACTOR
step_size = cfg.AUG.SCALE_STEP_SIZE
scale_factor = get_random_scale(
min_scale_factor, max_scale_factor, step_size)
img, grt = randomly_scale_image_and_label(
img, grt, scale=scale_factor)
elif cfg.AUG.AUG_METHOD == 'rangescaling':
min_resize_value = cfg.AUG.MIN_RESIZE_VALUE
max_resize_value = cfg.AUG.MAX_RESIZE_VALUE
if mode == ModelPhase.TRAIN:
if min_resize_value == max_resize_value:
random_size = min_resize_value
else:
random_size = int(
np.random.uniform(min_resize_value, max_resize_value) + 0.5)
else:
random_size = cfg.AUG.INF_RESIZE_VALUE
value = max(img.shape[0], img.shape[1])
scale = float(random_size) / float(value)
img = cv2.resize(img, (0, 0),
fx=scale, fy=scale,
interpolation=cv2.INTER_LINEAR)
if grt is not None:
grt = cv2.resize(
grt, (0, 0),
fx=scale,
fy=scale,
interpolation=cv2.INTER_NEAREST)
else:
raise Exception("Unexpect data augmention method: {}".format(
cfg.AUG.AUG_METHOD))
return img, grt
def get_random_scale(min_scale_factor, max_scale_factor, step_size):
"""
在一定范围内得到随机值,范围为min_scale_factor到max_scale_factor,间隔为step_size
Args:
min_scale_factor(float): 随机尺度下限,大于0
max_scale_factor(float): 随机尺度上限,不小于下限值
step_size(float): 尺度间隔,非负, 等于为0时直接返回min_scale_factor到max_scale_factor范围内任一值
Returns:
随机尺度值
"""
if min_scale_factor < 0 or min_scale_factor > max_scale_factor:
raise ValueError('Unexpected value of min_scale_factor.')
if min_scale_factor == max_scale_factor:
return min_scale_factor
if step_size == 0:
return np.random.uniform(min_scale_factor, max_scale_factor)
num_steps = int((max_scale_factor - min_scale_factor) / step_size + 1)
scale_factors = np.linspace(min_scale_factor, max_scale_factor,
num_steps).tolist()
np.random.shuffle(scale_factors)
return scale_factors[0]
def randomly_scale_image_and_label(image, label=None, scale=1.0):
"""
按比例resize图像和标签图, 如果scale为1,返回原图
Args:
image(numpy.ndarray): 输入图像
label(numpy.ndarray): 标签图,默认None
sclae(float): 图片resize的比例,非负,默认1.0
Returns:
resize后的图像和标签图
"""
if scale == 1.0:
return image, label
height = image.shape[0]
width = image.shape[1]
new_height = int(height * scale + 0.5)
new_width = int(width * scale + 0.5)
new_image = cv2.resize(
image, (new_width, new_height), interpolation=cv2.INTER_LINEAR)
if label is not None:
height = label.shape[0]
width = label.shape[1]
new_height = int(height * scale + 0.5)
new_width = int(width * scale + 0.5)
new_label = cv2.resize(
label, (new_width, new_height), interpolation=cv2.INTER_NEAREST)
return new_image, new_label
def random_rotation(crop_img, crop_seg, rich_crop_max_rotation, mean_value):
"""
随机旋转图像和标签图
Args:
crop_img(numpy.ndarray): 输入图像
crop_seg(numpy.ndarray): 标签图
rich_crop_max_rotation(int):旋转最大角度,0-90
mean_value(list):均值, 对图片旋转产生的多余区域使用均值填充
Returns:
旋转后的图像和标签图
"""
ignore_index = cfg.DATASET.IGNORE_INDEX
if rich_crop_max_rotation > 0:
(h, w) = crop_img.shape[:2]
do_rotation = np.random.uniform(-rich_crop_max_rotation,
rich_crop_max_rotation)
pc = (w // 2, h // 2)
r = cv2.getRotationMatrix2D(pc, do_rotation, 1.0)
cos = np.abs(r[0, 0])
sin = np.abs(r[0, 1])
nw = int((h * sin) + (w * cos))
nh = int((h * cos) + (w * sin))
(cx, cy) = pc
r[0, 2] += (nw / 2) - cx
r[1, 2] += (nh / 2) - cy
dsize = (nw, nh)
crop_img = cv2.warpAffine(
crop_img,
r,
dsize=dsize,
flags=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_CONSTANT,
borderValue=mean_value)
crop_seg = cv2.warpAffine(
crop_seg,
r,
dsize=dsize,
flags=cv2.INTER_NEAREST,
borderMode=cv2.BORDER_CONSTANT,
borderValue=(ignore_index, ignore_index, ignore_index))
return crop_img, crop_seg
def rand_scale_aspect(crop_img,
crop_seg,
rich_crop_min_scale=0,
rich_crop_aspect_ratio=0):
"""
从输入图像和标签图像中裁取随机宽高比的图像,并reszie回原始尺寸
Args:
crop_img(numpy.ndarray): 输入图像
crop_seg(numpy.ndarray): 标签图像
rich_crop_min_scale(float):裁取图像占原始图像的面积比,0-1,默认0返回原图
rich_crop_aspect_ratio(float): 裁取图像的宽高比范围,非负,默认0返回原图
Returns:
裁剪并resize回原始尺寸的图像和标签图像
"""
if rich_crop_min_scale == 0 or rich_crop_aspect_ratio == 0:
return crop_img, crop_seg
else:
img_height = crop_img.shape[0]
img_width = crop_img.shape[1]
for i in range(0, 10):
area = img_height * img_width
target_area = area * np.random.uniform(rich_crop_min_scale, 1.0)
aspectRatio = np.random.uniform(rich_crop_aspect_ratio,
1.0 / rich_crop_aspect_ratio)
dw = int(np.sqrt(target_area * 1.0 * aspectRatio))
dh = int(np.sqrt(target_area * 1.0 / aspectRatio))
if (np.random.randint(10) < 5):
tmp = dw
dw = dh
dh = tmp
if (dh < img_height and dw < img_width):
h1 = np.random.randint(0, img_height - dh)
w1 = np.random.randint(0, img_width - dw)
crop_img = crop_img[h1:(h1 + dh), w1:(w1 + dw), :]
crop_seg = crop_seg[h1:(h1 + dh), w1:(w1 + dw)]
crop_img = cv2.resize(
crop_img, (img_width, img_height),
interpolation=cv2.INTER_LINEAR)
crop_seg = cv2.resize(
crop_seg, (img_width, img_height),
interpolation=cv2.INTER_NEAREST)
break
return crop_img, crop_seg
def saturation_jitter(cv_img, jitter_range):
"""
调节图像饱和度
Args:
cv_img(numpy.ndarray): 输入图像
jitter_range(float): 调节程度,0-1
Returns:
饱和度调整后的图像
"""
greyMat = cv2.cvtColor(cv_img, cv2.COLOR_BGR2GRAY)
greyMat = greyMat[:, :, None] * np.ones(3, dtype=int)[None, None, :]
cv_img = cv_img.astype(np.float32)
cv_img = cv_img * (1 - jitter_range) + jitter_range * greyMat
cv_img = np.where(cv_img > 255, 255, cv_img)
cv_img = cv_img.astype(np.uint8)
return cv_img
def brightness_jitter(cv_img, jitter_range):
"""
调节图像亮度
Args:
cv_img(numpy.ndarray): 输入图像
jitter_range(float): 调节程度,0-1
Returns:
亮度调整后的图像
"""
cv_img = cv_img.astype(np.float32)
cv_img = cv_img * (1.0 - jitter_range)
cv_img = np.where(cv_img > 255, 255, cv_img)
cv_img = cv_img.astype(np.uint8)
return cv_img
def contrast_jitter(cv_img, jitter_range):
"""
调节图像对比度
Args:
cv_img(numpy.ndarray): 输入图像
jitter_range(float): 调节程度,0-1
Returns:
对比度调整后的图像
"""
greyMat = cv2.cvtColor(cv_img, cv2.COLOR_BGR2GRAY)
mean = np.mean(greyMat)
cv_img = cv_img.astype(np.float32)
cv_img = cv_img * (1 - jitter_range) + jitter_range * mean
cv_img = np.where(cv_img > 255, 255, cv_img)
cv_img = cv_img.astype(np.uint8)
return cv_img
def random_jitter(cv_img, saturation_range, brightness_range, contrast_range):
"""
图像亮度、饱和度、对比度调节,在调整范围内随机获得调节比例,并随机顺序叠加三种效果
Args:
cv_img(numpy.ndarray): 输入图像
saturation_range(float): 饱和对调节范围,0-1
brightness_range(float): 亮度调节范围,0-1
contrast_range(float): 对比度调节范围,0-1
Returns:
亮度、饱和度、对比度调整后图像
"""
saturation_ratio = np.random.uniform(-saturation_range, saturation_range)
brightness_ratio = np.random.uniform(-brightness_range, brightness_range)
contrast_ratio = np.random.uniform(-contrast_range, contrast_range)
order = [1, 2, 3]
np.random.shuffle(order)
for i in range(3):
if order[i] == 0:
cv_img = saturation_jitter(cv_img, saturation_ratio)
if order[i] == 1:
cv_img = brightness_jitter(cv_img, brightness_ratio)
if order[i] == 2:
cv_img = contrast_jitter(cv_img, contrast_ratio)
return cv_img
def hsv_color_jitter(crop_img,
brightness_jitter_ratio=0,
saturation_jitter_ratio=0,
contrast_jitter_ratio=0):
"""
图像亮度、饱和度、对比度调节
Args:
crop_img(numpy.ndarray): 输入图像
brightness_jitter_ratio(float): 亮度调节度最大值,1-0,默认0
saturation_jitter_ratio(float): 饱和度调节度最大值,1-0,默认0
contrast_jitter_ratio(float): 对比度调节度最大值,1-0,默认0
Returns:
亮度、饱和度、对比度调节后图像
"""
if brightness_jitter_ratio > 0 or \
saturation_jitter_ratio > 0 or \
contrast_jitter_ratio > 0:
crop_img = random_jitter(crop_img, saturation_jitter_ratio,
brightness_jitter_ratio, contrast_jitter_ratio)
return crop_img
def rand_crop(crop_img, crop_seg, mode=ModelPhase.TRAIN):
"""
随机裁剪图片和标签图, 若crop尺寸大于原始尺寸,分别使用均值和ignore值填充再进行crop,
crop尺寸与原始尺寸一致,返回原图,crop尺寸小于原始尺寸直接crop
Args:
crop_img(numpy.ndarray): 输入图像
crop_seg(numpy.ndarray): 标签图
mode(string): 模式, 默认训练模式,验证或预测、可视化模式时crop尺寸需大于原始图片尺寸
Returns:
裁剪后的图片和标签图
"""
img_height = crop_img.shape[0]
img_width = crop_img.shape[1]
if ModelPhase.is_train(mode):
crop_width = cfg.TRAIN_CROP_SIZE[0]
crop_height = cfg.TRAIN_CROP_SIZE[1]
else:
crop_width = cfg.EVAL_CROP_SIZE[0]
crop_height = cfg.EVAL_CROP_SIZE[1]
if not ModelPhase.is_train(mode):
if (crop_height < img_height or crop_width < img_width):
raise Exception(
"Crop size({},{}) must large than img size({},{}) when in EvalPhase."
.format(crop_width, crop_height, img_width, img_height))
if img_height == crop_height and img_width == crop_width:
return crop_img, crop_seg
else:
pad_height = max(crop_height - img_height, 0)
pad_width = max(crop_width - img_width, 0)
if (pad_height > 0 or pad_width > 0):
crop_img = cv2.copyMakeBorder(
crop_img,
0,
pad_height,
0,
pad_width,
cv2.BORDER_CONSTANT,
value=cfg.DATASET.PADDING_VALUE)
if crop_seg is not None:
crop_seg = cv2.copyMakeBorder(
crop_seg,
0,
pad_height,
0,
pad_width,
cv2.BORDER_CONSTANT,
value=cfg.DATASET.IGNORE_INDEX)
img_height = crop_img.shape[0]
img_width = crop_img.shape[1]
if crop_height > 0 and crop_width > 0:
h_off = np.random.randint(img_height - crop_height + 1)
w_off = np.random.randint(img_width - crop_width + 1)
crop_img = crop_img[h_off:(crop_height + h_off), w_off:(
w_off + crop_width), :]
if crop_seg is not None:
crop_seg = crop_seg[h_off:(crop_height + h_off), w_off:(
w_off + crop_width)]
return crop_img, crop_seg5. PaddleSeg 训练的数据增强
pdseg/reader.py
class SegDataset(object):
......
def load_image(self, line, src_dir, mode=ModelPhase.TRAIN):
# original image cv2.imread flag setting
cv2_imread_flag = cv2.IMREAD_COLOR
if cfg.DATASET.IMAGE_TYPE == "rgba":
# If use RBGA 4 channel ImageType, use IMREAD_UNCHANGED flags to
# reserver alpha channel
cv2_imread_flag = cv2.IMREAD_UNCHANGED
parts = line.strip().split(cfg.DATASET.SEPARATOR)
if len(parts) != 2:
if mode == ModelPhase.TRAIN or mode == ModelPhase.EVAL:
raise Exception("File list format incorrect! It should be"
" image_name{}label_name\\n".format(
cfg.DATASET.SEPARATOR))
img_name, grt_name = parts[0], None
else:
img_name, grt_name = parts[0], parts[1]
img_path = os.path.join(src_dir, img_name)
img = cv2_imread(img_path, cv2_imread_flag)
if grt_name is not None:
grt_path = os.path.join(src_dir, grt_name)
grt = cv2_imread(grt_path, cv2.IMREAD_GRAYSCALE)
else:
grt = None
if img is None:
raise Exception(
"Empty image, src_dir: {}, img: {} & lab: {}".format(
src_dir, img_path, grt_path))
img_height = img.shape[0]
img_width = img.shape[1]
if grt is not None:
grt_height = grt.shape[0]
grt_width = grt.shape[1]
if img_height != grt_height or img_width != grt_width:
raise Exception(
"source img and label img must has the same size")
else:
if mode == ModelPhase.TRAIN or mode == ModelPhase.EVAL:
raise Exception(
"Empty image, src_dir: {}, img: {} & lab: {}".format(
src_dir, img_path, grt_path))
if len(img.shape) < 3:
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
img_channels = img.shape[2]
if img_channels < 3:
raise Exception("PaddleSeg only supports gray, rgb or rgba image")
if img_channels != cfg.DATASET.DATA_DIM:
raise Exception(
"Input image channel({}) is not match cfg.DATASET.DATA_DIM({}), img_name={}"
.format(img_channels, cfg.DATASET.DATADIM, img_name))
if img_channels != len(cfg.MEAN):
raise Exception(
"img name {}, img chns {} mean size {}, size unequal".format(
img_name, img_channels, len(cfg.MEAN)))
if img_channels != len(cfg.STD):
raise Exception(
"img name {}, img chns {} std size {}, size unequal".format(
img_name, img_channels, len(cfg.STD)))
return img, grt, img_name, grt_name
def normalize_image(self, img):
""" 像素归一化后减均值除方差 """
img = img.transpose((2, 0, 1)).astype('float32') / 255.0
img_mean = np.array(cfg.MEAN).reshape((len(cfg.MEAN), 1, 1))
img_std = np.array(cfg.STD).reshape((len(cfg.STD), 1, 1))
img -= img_mean
img /= img_std
return img
def process_image(self, line, data_dir, mode):
""" process_image """
img, grt, img_name, grt_name = self.load_image(
line, data_dir, mode=mode)
if mode == ModelPhase.TRAIN: #模型训练
img, grt = aug.resize(img, grt, mode)
if cfg.AUG.RICH_CROP.ENABLE:
if cfg.AUG.RICH_CROP.BLUR:
if cfg.AUG.RICH_CROP.BLUR_RATIO <= 0:
n = 0
elif cfg.AUG.RICH_CROP.BLUR_RATIO >= 1:
n = 1
else:
n = int(1.0 / cfg.AUG.RICH_CROP.BLUR_RATIO)
if n > 0:
if np.random.randint(0, n) == 0:
radius = np.random.randint(3, 10)
if radius % 2 != 1:
radius = radius + 1
if radius > 9:
radius = 9
img = cv2.GaussianBlur(img, (radius, radius), 0, 0)
img, grt = aug.random_rotation(
img,
grt,
rich_crop_max_rotation=cfg.AUG.RICH_CROP.MAX_ROTATION,
mean_value=cfg.DATASET.PADDING_VALUE)
img, grt = aug.rand_scale_aspect(
img,
grt,
rich_crop_min_scale=cfg.AUG.RICH_CROP.MIN_AREA_RATIO,
rich_crop_aspect_ratio=cfg.AUG.RICH_CROP.ASPECT_RATIO)
img = aug.hsv_color_jitter(
img,
brightness_jitter_ratio=cfg.AUG.RICH_CROP.
BRIGHTNESS_JITTER_RATIO,
saturation_jitter_ratio=cfg.AUG.RICH_CROP.
SATURATION_JITTER_RATIO,
contrast_jitter_ratio=cfg.AUG.RICH_CROP.
CONTRAST_JITTER_RATIO)
if cfg.AUG.FLIP:
if cfg.AUG.FLIP_RATIO <= 0:
n = 0
elif cfg.AUG.FLIP_RATIO >= 1:
n = 1
else:
n = int(1.0 / cfg.AUG.FLIP_RATIO)
if n > 0:
if np.random.randint(0, n) == 0:
img = img[::-1, :, :]
grt = grt[::-1, :]
if cfg.AUG.MIRROR:
if np.random.randint(0, 2) == 1:
img = img[:, ::-1, :]
grt = grt[:, ::-1]
img, grt = aug.rand_crop(img, grt, mode=mode)
elif ModelPhase.is_eval(mode):#模型评估
img, grt = aug.resize(img, grt, mode=mode)
img, grt = aug.rand_crop(img, grt, mode=mode)
elif ModelPhase.is_visual(mode):#模型可视化
org_shape = [img.shape[0], img.shape[1]]
img, grt = aug.resize(img, grt, mode=mode)
valid_shape = [img.shape[0], img.shape[1]]
img, grt = aug.rand_crop(img, grt, mode=mode)
else:
raise ValueError("Dataset mode={} Error!".format(mode))
# Normalize image
img = self.normalize_image(img)
if ModelPhase.is_train(mode) or ModelPhase.is_eval(mode):
grt = np.expand_dims(np.array(grt).astype('int32'), axis=0)
ignore = (grt != cfg.DATASET.IGNORE_INDEX).astype('int32')
if ModelPhase.is_train(mode):
return (img, grt, ignore)
elif ModelPhase.is_eval(mode):
return (img, grt, ignore)
elif ModelPhase.is_visual(mode):
return (img, grt, img_name, valid_shape, org_shape)