原文:A Simple Guide to Semantic Segmentation - 2019.05.03
作者:Bharath Raj
主要是关于语义分割的经典方法和深度学习方法的全面回顾.
语义分割旨在对图片中每个像素指定一个类别. 与图像分类形成鲜明对比,图像分类是对整张图片指定一个类别. 语义分割将同一类别的多个对象(objects) 作为单个实体(entity). 另一方面,实例分割是将同一类别的多个对象(objects) 作为不同的独立对象(或实例instances). 一般情况下,实例分割相比于语义分割是更难处理的.

图1 - 语义分割与实例分割对比例示(From: http://www.robots.ox.ac.uk/~tvg/publications/2017/CRFMeetCNN4SemanticSegmentation.pdf)
本文主要介绍一些基于经典方法和深度学习方法的语义分割技术,并讨论了常用损失函数和应用场景.
1. 语义分割经典方法
在深度学习出现之前,很多图像处理技术被用于将图像分割为多个感兴趣的区域(regions of interest). 以下列出一些流行方法.
1.1. 灰度分割(Gray Level Segmentation)
语义分割的最简单形式是对一个区域设定必须满足的硬编码规则或属性,进而指定特定类别标签. 编码规则可以根据像素的属性来构建,如灰度级强度(gray level intensity). 基于该技术的一种分割方法是 Split and Merge 算法. 该算法是通过递归地将图像分割为子区域,直到可以分配标签;然后再合并具有相同标签的相邻子区域.
这种方法的问题是规则必须是硬编码的. 而且,仅使用灰度级信息是很难表示比如人类等复杂类别的. 因此,需要特征提取和优化技术来正确地学习复杂类别的特征表示.
1.2. 条件随机场(Conditional Random Fields)
图像分割通过训练模型对每个像素指定类别. 但是,如果分割模型不够完美,则可能会得到原本不可能存在的噪声分割结果,如图,dog 像素与 cat 像素混合:
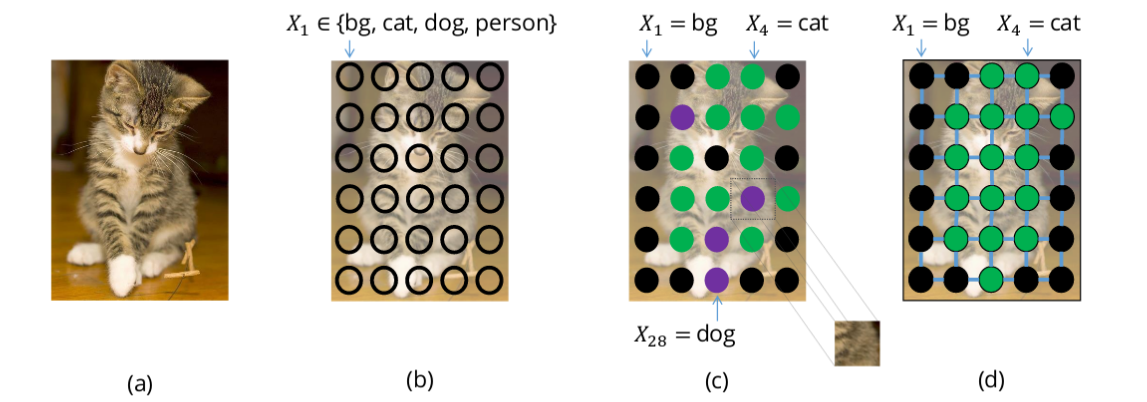
图2 - dog 像素与 cat 像素混合例示(图 c). 期望的分割如图 d. From: http://www.robots.ox.ac.uk/~tvg/publications/2017/CRFMeetCNN4SemanticSegmentation.pdf
这种问题可以通过考虑像素间的先验关系来避免,如对象物体一般是连续的,因此邻近像素更可能具有相同标签. 为了对这种关系进行建模,可以采用条件随机场(Conditional Random Fields, CRFs).
CRFs 是一类用于结构化预测的统计建模方法. 不同于分类算法,CRFs 在进行预测前,会考虑像素的邻近信息(neighboring context),如像素间的关系. 这使得 CRFs 成为语义分割的理想候选者. 这里介绍下 CRFs 在语义分割中的应用.
图像中的每个像素都是与有限的可能状态集相关. 在语义分割中,target 类别标签就是可能状态集. 将一个状态(或,label u) 分配给的单个像素 x 的成本(cost) 被称为一元成本(unary cost). 为了对像素间的关系进行建模, 还进一步考虑将一对标签(labels (u, v)) 分配给一对像素 (x, y),其被成为成对成本(pairwise cost). 可以采用直接相邻的像素对作为像素对(Grid CRF);也可以采用图像中所有的像素构建像素对(Denser CRF). 如图:

图3 - Dense CRF 和 Grid CRF 例示. From: https://slideplayer.com/slide/784090/3/images/2/Dense+CRF+construction.jpg
图像中所有 unary cost 和 pairwise cost 的相加和作为 CRF 的能量函数(或损失函数,loss). 求解最小化即可得到较好的分割输出.
2. 语义分割深度学习方法
深度学习极大地简化了语义分割的流程(pipeline),并得到了较高质量的分割结果. 这里,讨论几种流行的深度学习模型结构和损失函数.
2.1. 模型结构
2.1.1. FCN
语义分割的最简单和流行的网络结构是全卷积网络(FCN). 在论文 FCN for Semantic Segmentation 中,作者采用 FCN 网络首先通过一系列的卷积操作将输入图像下采样到更小的尺寸(同时得到更多的通道). 这一系列的卷积操作一般称为编码器(encoder). 得到的编码输出,通过双线性插值(bilinear interpolation)或一系列转置卷积操作(transpose-convolutions) 上采样,进而得到最终的分割结果. 这一系列的转置卷积操作一般称为解码器(decoder).

图 4 - FCN 中的下采样和上采样. From: https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf
尽管这种 FCN 的基本结构有效,但其仍有很多不足. 其中一个就是由于转置卷积(或反卷积) 操作的输出的不均匀重叠而导致的棋盘效应(checkerboard artifacts)的存在. 如图:
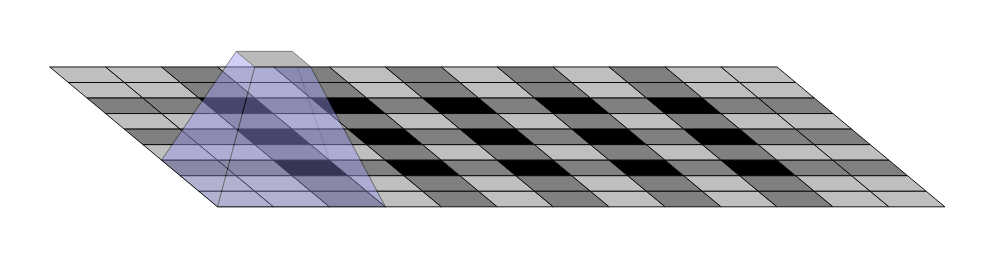
图 5 - 棋盘效应的例示. From: https://distill.pub/2016/deconv-checkerboard/
基于基本 FCN 模型,已经出现很多提升分割质量的解决方案. 下面会介绍几种被证明比较有效的流行方法.
2.1.2. U-Net
U-Net 是 FCN 结构的升级. U-Net 包含几个从卷积模块的输出到相同层级的对应转置卷积模块的输入之间的跳跃链接.(It has skip connections from the output of convolution blocks to the corresponding input of the transposed-convolution block at the same level.)
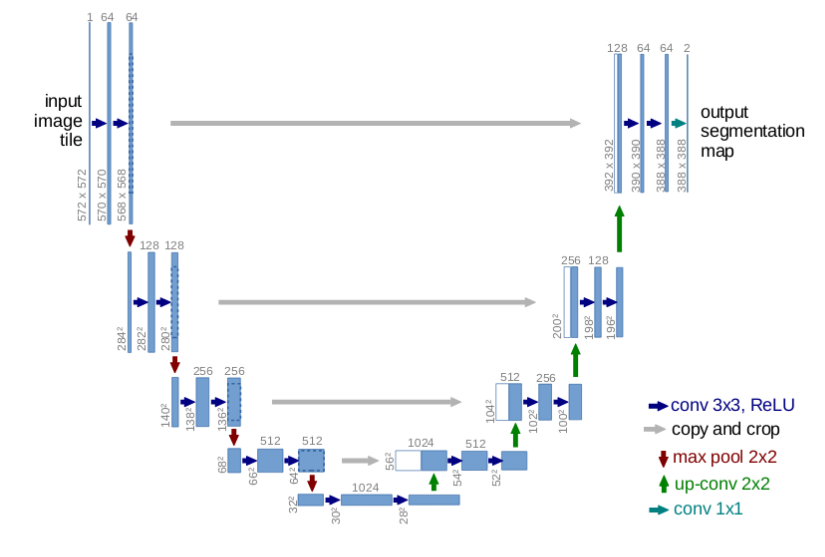
图 6 - U-Net. From: https://arxiv.org/pdf/1505.04597.pdf
U-Net 的跳跃链接使得梯度更好的流通,同时提供了图像尺寸的多尺度的信息. 更大尺度(更上的网络层)的信息有助于提升模型的分类能力;更小尺度(更深的网络层)的信息有助于提升模型的分割/定位能力.
2.1.3. Tiramisu Model
Tiramisu Model 类似于 U-Net,除了其使用了 Dense Blocks 进行卷积和转置卷积操作,类似于在论文 DenseNet 中所采用的. 一个 Dense Blocks 包含多个卷积层,其中所有靠前网络层的特征图都用作后面网络层的输入. 据此设计的网络具有较高的参数效率,且可以更好的访问先前网络层的特征.
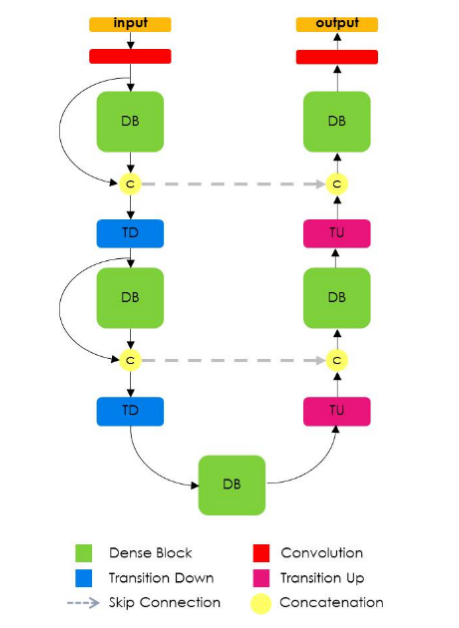
图 7 - Tiramisu Network. From: https://arxiv.org/abs/1611.09326
Tiramisu Model 的一个副作用是,由于多个 ML 框架的连接操作(concatenation operations)的特点,导致其内存效率不高(运行需要基于大型 GPU).
2.1.4. MustiScale 方法
一些深度学习模型引入了整合多个尺度的信息的方法. 例如,PSPNet(Pyramid Scene Parsing Network) 采用四种不同 kernel sizes 和 strides 的池化操作(max 或 average) 对 CNN 网络(如 ResNet)输出的特征图进行处理;然后再对所有的池化操作的输出特征图以及 CNN 网络的输出特征图,进行上采样到相同尺寸;再根据 channel axis 进行链接. 最后,针对链接后的特征图进行卷积操作,以生成最终的预测结果.
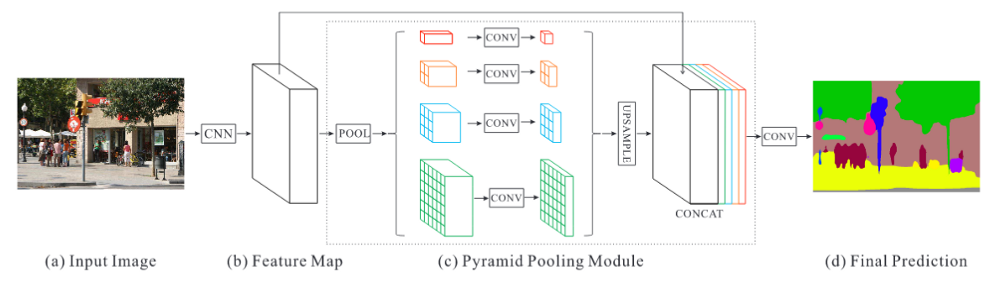
图 8 - PSPNet. From: https://arxiv.org/pdf/1612.01105.pdf
Atrous (Dilated) Convolutions 提出了一种有效的组合多尺度特征的方法,而且不大量增加参数量. 通过调整 dilation rate,相同的 fliter 其权重值展开更多的空间,使得其能够学习更多的全局内容信息.
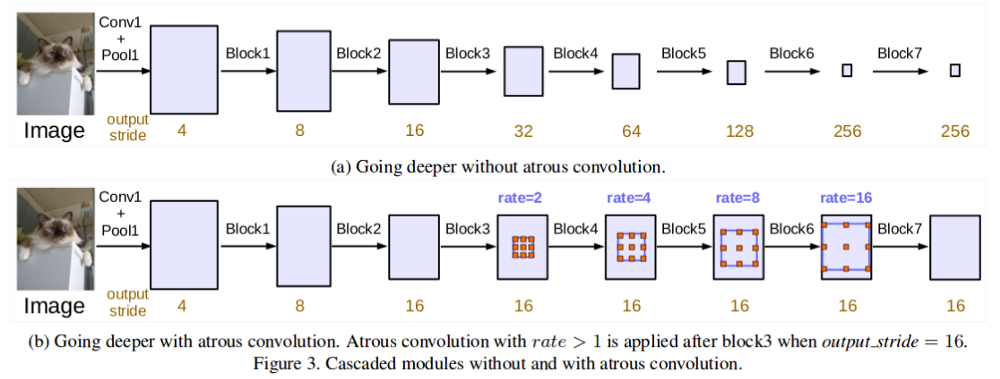
图 9 - Cascaded Atrous Convolutions. From: https://arxiv.org/pdf/1706.05587.pdf
论文 DeepLabv3 采用不同 dilation rates 的 Atrous Convolutions 来捕获多个尺度的信息,而并不或导致图像尺寸的显著损失. DeepLabv3 论文里探索了以级联方式的 Atrous Convolutions (如图 9)以及并行方式的 Atrous Spatial Pyramid Pooling(如图 10).
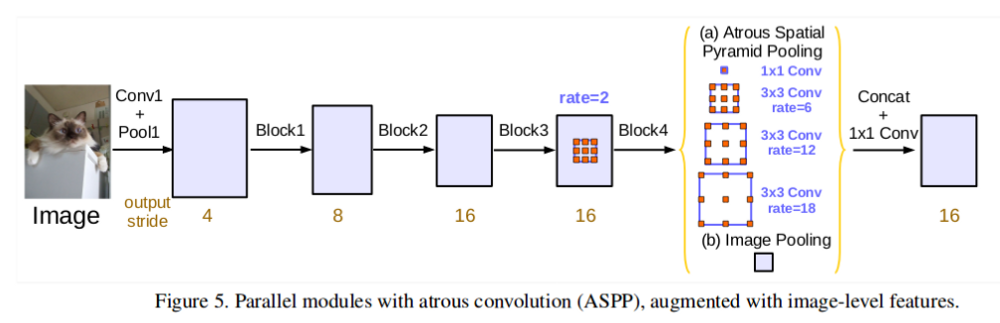
图 10 - Parallel Atrous Convolutions. From: https://arxiv.org/pdf/1706.05587.pdf
2.1.5. Hybrid CNN-CRF 方法
一些深度学习模型采用 CNNs 作为特征提取器,然后将特征作为 DenseCRF 的 unary cost 输入. 这种融合 CNN-CRF 的方法采用了 CRFs 对像素间关系建模的能力,得到了不错的分割结果.
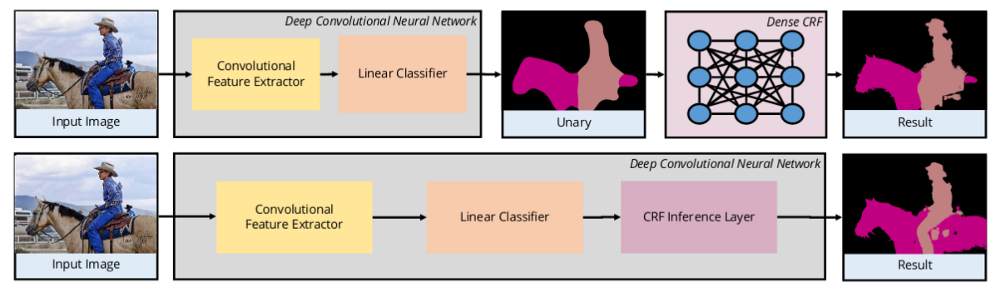
图 11 - 基于 CNN 和 CRF 融合的方法. From: http://www.robots.ox.ac.uk/~tvg/publications/2017/CRFMeetCNN4SemanticSegmentation.pdf
某些深度学习方法将 CRF 整合进了网络自身,如 CRF-as-RNN. 其中,DenseCRF 被建模为 Recrrent Neural Network. 这就实现了 end-to-end 的模型训练. 如图 11.
2.2. 损失函数
与常规分类器不同,语义分割必须选择不同的损失函数. 下面会介绍语义分割中几种常用的损失函数.
2.2.1. Pixel-wise Softmax with Cross Entropy
语义分割的 GT Labels 与原始图片具有相同的尺寸. GT label 可以表示为如下的 one-hot 编码形式:
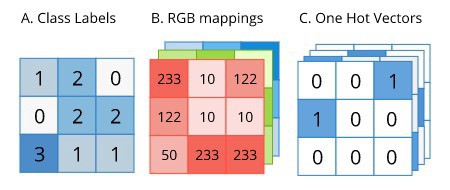
图 12 - 语义分割的 one-hot 形式. From: http://ronny.rest/media/tutorials/segmentation/ZZZ_IMAGES_DIR/label_formats.jpeg
由于 GT label 是 one-hot 形式,其可以直接用作 groundtruth(target) 进行交叉熵计算. 不过,在交叉熵计算前,必须对预测的输出采用 softmax 操作进行逐像素操作,因为每个像素可以属于目标类别中的任何一个.
2.2.2. Focal Loss
Focal Loss 是在论文 RetinaNet 提出,是标准交叉熵损失的升级版,用于极端的类别不均衡的情况.
如图 13 中(蓝色曲线) 所画出的标准交叉熵损失函数的结果. 即使模型对于一个像素的类别具有很高的置信度(如 80%),但仍有比较明显的损失值(这里大概是 0.3). 而 Focal Loss(橙色曲线,gamma=2)在模型对类别比较高的置信时,不会对模型进行这么大的惩罚(如,对于 80% 的置信度,loss 几乎是 0).

图 13 - 标准 cross entropy loss(蓝色曲线) 和不同 gamma 值的 Focal Loss 例示.From: https://arxiv.org/pdf/1708.02002.pdf
这里通过一个直观的例子来说明 Focal loss 中的重要性. 假设有 10000 个像素,仅属于两个类别:背景类(one-hot 形式中的值为 0) 和目标类(one-hot 形式中值为 1). 假设图像中 97% 的是背景,3% 的是目标. 假设模型认为该像素 80% 的属于背景,但是只有 30% 的认为是属于目标类.
当采用交叉熵时,背景像素的损失值为: (97% of 10000) x 0.3 = 2850; 目标像素的损失值为: (3% of 10000)x1.2=360. 很明显,由于 loss 值大的类别占主导地位,模型学习目标类别的机会很小.
而采用 Focal loss 时,由于背景类的损失值为: (97% of 10000) x 0 = 0, 使得模型更好的去学习目标类别,而非背景类.
2.2.3. Dice Loss
医学图像分割之 Dice Loss - AIUAI
Dice Loss 是另一种用于处理类别不均衡的语义分割问题的流行损失函数.
正如论文 V-Net 所提出的,Dice Loss 用于计算预测类与 GT 类的重叠程度.
Dice Coefficient(D) 表示如:
$$ D = \frac{2 \sum_i^N p_i g_i}{\sum_i^N p_i^2 + \sum_i^N g_i^2} $$
目标是,最大化预测结果与 GT 的重叠程度(如,最大化 Dice Coefficient). 因此,一般采用最小化 $1 - D$ 来实现,因为大部分 ML 库提供的仅是最小化优化.
$$ \frac{\partial D}{\partial p_j} = 2 [ \frac{g_j (\sum_i^N p_i^2 + \sum_i^N g_i^2) - 2p_j(\sum_i^N p_i g_j)}{(\sum_i^N p_i^2 + \sum_i^N g_i^2)^2}] $$
即使 Dice Loss 能够处理类别不均衡的样本,但上面的求微分公式中包含二次项. 当这些值比较小时,可能会得到较大的梯度,导致训练不稳定.
3. 语义分割应用
语义分割具有很多实际应用场景. 下面给出几种.
3.1. 自动驾驶
语义分割用于识别车道、车辆、行人和其它感兴趣的目标. 分割结果有助于进行明智的判断,以正确的控制车辆.

图 14 - 自动驾驶中的语义分割. From: https://wiki.tum.de/download/attachments/23561833/sms.png?version=1&modificationDate=1483619907233&api=v2
自动驾驶中要求必须是实时的. 一种解决方案是将 GPU 整合进车辆. 为了提升效果,可以采用轻量(参数少)神经网络,或者边缘计算( edge).
3.2. 医学图像分割
语义分割可以用于识别医学扫描图像中的显著元素,尤其对于识别肿瘤等异常特别有用. 算法的准确性和低召回率度是非常重要的.
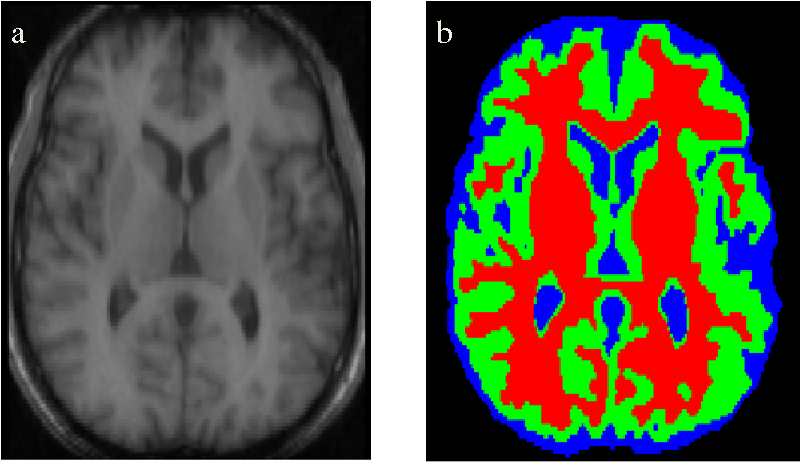
图 15 - 医学扫描图像的分割. From: https://ai2-s2-public.s3.amazonaws.com/figures/2017-08-08/1b699b098ec7a5e539afd8370d71a82d41e3370d/3-Figure1-1.png
还可以自动进行一些不太重要的操作,如从 3D 语义分割扫描结果中估计器官的体积.
3.3. 场景理解
语义分割往往是构成更复杂任务的基础,如,场景理解(Scene Understanding) 和视觉问答(Visual Question and Answer, VQA). 场景图和标题往往是场景理解算法的输出结果.
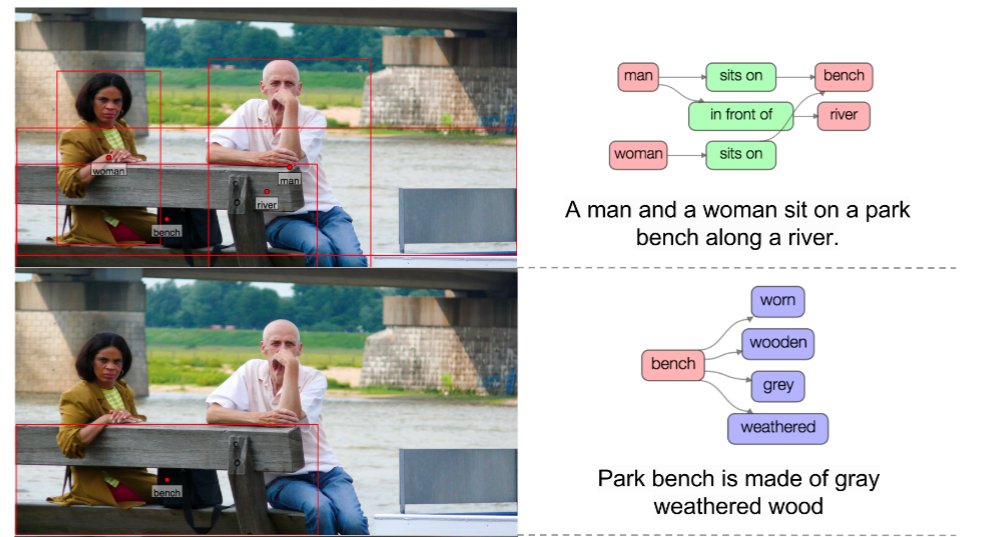
图 16 - 场景理解例示. From: https://arxiv.org/pdf/1606.04797.pdf
3.4. 时尚产业
语义分割可以用于时尚产业,提取图片中服装,并提供来自零售商店的相似款推荐. 更高级的算法是,重新设计图片中的特定服装.
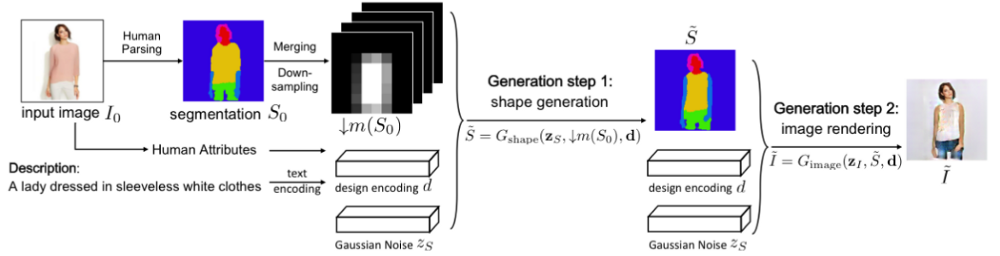 图 17 - 语义分割用作基于文本输入来纠正人类的中间步骤. From: https://arxiv.org/abs/1710.07346
图 17 - 语义分割用作基于文本输入来纠正人类的中间步骤. From: https://arxiv.org/abs/1710.07346
3.5. 卫星(空中)图像处理
语义分割可以用于从卫星图像中识别陆地类型. 典型的如识别陆地水体,以提供更准确的地图信息. 其它更高级的用途,如绘制道路、识别作物类型、识别免费停车位等.
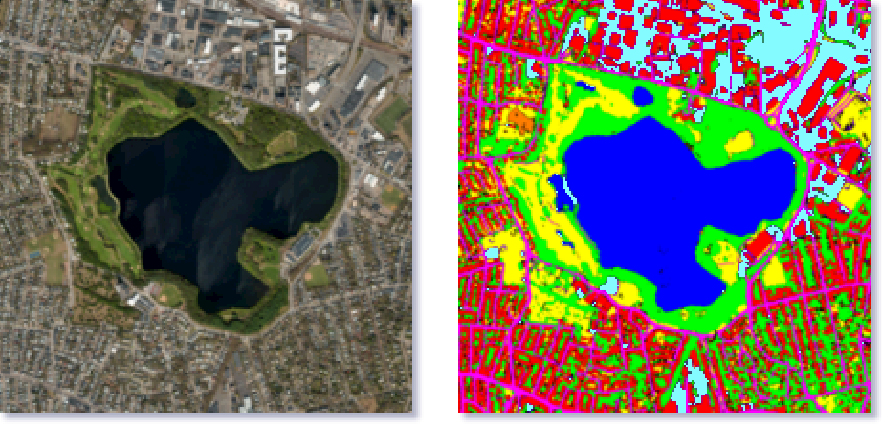
图 18 - 卫星/空中图像的语义分割. From: https://ai2-s2-public.s3.amazonaws.com/figures/2017-08-08/59cbe15b43e6ca172fce40786be68340f50be541/12-Figure1.1-1.png
4. 总结
深度学习极大地增强和简化了语义分割算法,并为在现实生活场景的广泛应用铺平了道路. 这里列出的内容并不详尽,因为研究人员仍在持续不断努力提升算法准确性和实时性. 这里只介绍了一些流行算法及其部分应用场景.