基于 PyTorch 和 102 种 flowers 数据集,图像分类器的实现.
目标: 理解图像分类器的实现过程,但并未提供逐步的实现说明.
[1] - 加载预训练神经网络模型;
阐述采用预训练模型的优势,所重用的部分预训练模型和未重用的部分网络;
根据应用场景,定制预训练网络的指导.
1. 加载预训练模型
重用是一种相当好的策略,尤其是对于众所周知且有完善认知标准的问题.
1.1. 重用预训练模型
这里,目标是,采用 torchvision.models 中的预训练模型,并替换网络最后一层分类器层.
Pytorch - torchvison.models 模型结构定义 - AIUAI
思想是很合理的,但也有容易混淆的地方,因为,加载预训练模型并不能节省分类器训练的工作(loading a pre-trained network does not save us the effort of training our classifier.)
“So you might wonder, what’s the point of using a pre-trained network?”
对于人来说,当我们看到一张图像时,可以辨别线条(lines) 和形状(shapes). 由此,可以将从未看到过的图像内容与之前看到的内容相联系.
这也是想要分类器能够实现类似的作用,但,图像并不是一小块数据. 其往往是由很多独立的像素组成,每个像素包含 R,G,B 三个通道.

由左向右依次为:原图,R图,G图,B图.
如果需要分类器能够处理图像数据,需要将所有的图像信息进行处理,以使得图像分类器能够理解. 这也就是预训练模型能够发挥作用之处.
预训练模型一般是由特征提取器和分类器组成,特征提取器用于提取每张图像的可用信息;分类器用于理解特征层输提供的输入.
在 ImageNet 上训练的特征提取器具有良好的表现,对此,仍继续采用. 为了避免在分类器训练时特征层发生变化,需要将特征层进行"冻结(freeze)",如:
for param in model.parameters():
param.requires_grad = False对于分类器,以 VGG16 为例,默认的分类器如:
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace)
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace)
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)首先,不能确保默认分类器能够适用于新的应用场景. 默认分类器层的输出节点数目、激活函数和 dropout 值等,均需要根据特定应用场景进行选择.
默认分类器的最后一层包含 1000 个元素的输出. 而对于这里的 flowers 分类器,仅有 102 个不同类别. 因此,分类器必须要替换为 102 个输出节点.
此外,在 VGG16 默认分类器中,其网络层输入有 25088 个元素,其是在预训练模型中特征提取器的输出尺寸. 自定义的分类器的输入尺寸必须与特征层的输出数相匹配.
1.2. 总结
[1] - 预训练模型是一种非常有效的方式,采用“重用”众所周知的图像预处理模型,其使得只用关注与特定应用场景.
[2] - 分类器的输出大小必须与特定应用场景中数据集的类别数目相一致.
[3] - 特征层的输出数与自定义的分类器的输入数也必须相一致.
2. 分类器训练
分类器模型训练的第一项工作是,将图像送入分类器. 可以采用 torchvision.datasets.ImageFolder 函数.
预训练模型的图像输入尺寸是以特定格式组织的. 因此,需要先进行图像变换处理,如resize, crop 和 normalize.
具体地,
首先,将图像 resize 到 224x224 尺寸,然后采用均值 mean=[0.485, 0.456, 0.406] 和方差 std=[0.229, 0.224, 0.225] 进行图像标准化. 并将图像像素值中心化为0,标准差缩放为 1.
接着,将处理后的图像,采用 torch.utils.data.DataLoader进行 batch 化. 数据集划分为 train, validation 和 test三个子集,因此,各创建一个 dataloader.
然后,即可开始训练分类器.
这里会遇到最大的挑战:精度Accuracy.
确保模型能够识别图像已经不是挑战问题,但模型具有较高的泛化能力,以便于能够识别模型从未见过的图像中 flower 类型.
对此,需要避免出现模型过拟合overfitting: 训练模型生成的分析与特定数据集过于紧密或完全对应,但,可能难以拟合其它数据或给出可靠的预测结果.
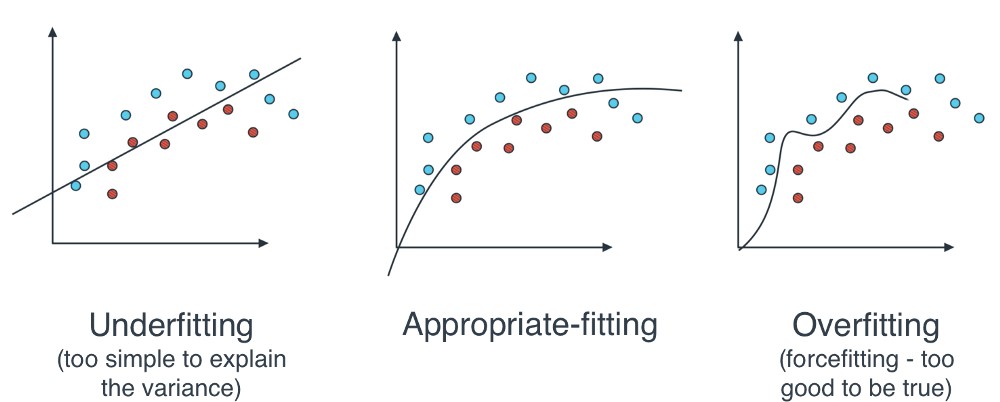
数据拟合类型.
2.1. 过拟合处理方法
2.1.1. 隐藏层 Hidden Layers
容易陷入误区的是,隐藏层参数越过或越大能够提高分类器的精度,实际上并非如此.
隐藏层数量或尺寸的增加,可以使得分类器包含更多不必要的参数. 如,将 flowers 的噪声数据也进行了加权. 其会导致过拟合问题和精度降低. 而且,会导致分类器花费更多的训练和预测时间.
对此,推荐从少量的隐藏层开始,根据需要逐渐增加.
对于 flowers 分类器,只需一个隐藏层,在第一个训练周期即可得到超过 70% 的精度.
2.1.2. 数据增强
模型训练时采用了很多数据,其很不错. 但如果有更多的数据,效果甚至会更好.
data augmentation - Data Augmentation | How to use Deep Learning when you have Limited Data — Part 2
对于训练图像数据集,可以进行随机图像变换处理,如,旋转,平移,缩放等. 因此,每个训练 epoch 中,每个图像的不同处理结果被送入网络.
提高训练数据的多样性,有助于降低过拟合,及提升分类器的泛化能力,进而提高整体模型精度.
2.1.3. 打乱顺序 shuffle
为了避免引入偏差,在训练分类器时,需要将图像的顺序进行随机化.
例如,如果开始送入分类器的图片只有 petunia(矮牵牛)图像,则,其张量将更偏向于 "Petunia". 而实际上,此时,分类器只知道 "Petunias". 因此,即使继续训练其它类型的数据,初始偏差也会一直存在.
对此,需要在 dataloader 中打乱图像顺序. 在 PyTorch 只需添加 shuffle=True:
trainloader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True)2.1.4. Dropout
某些情况下,分类器中的节点数可能对精度产生更多的影响,导致其它节点不能进行合适的训练.
此外,分类器节点可能产生相互依赖性(co-dependencies) ,并导致过拟合.
Dropout 是解决该问题的一种有效手段,其在训练时,随机的丢弃某些节点. 因此,在每个阶段,不同的节点子集进行训练,以此减少过拟合.
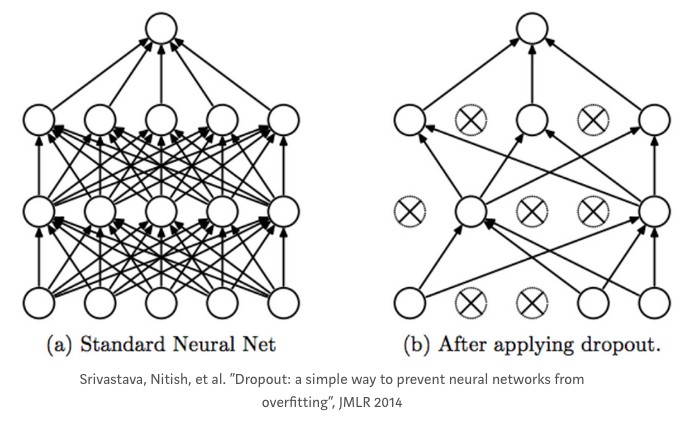
2.2. 学习率
除了过拟合问题,学习率可能是模型训练中最重要的参数.
如果学习率过大,可能不能得到损失函数最小值,难以收敛.
如果学习率过小,分类器的训练会非常慢.
学习率的典型值:0.01, 0.001, 0.0001 等.
2.3. 激活函数的选择
网络最后一层的激活函数的选择,不同的激活函数会对于模型精度有很大的差异.
例如,根据 PyTorch-Loss 函数,如果设置网络采用 negative log likelihood loss(NLLLoss),其推荐在最后一层采用 LogSoftmax 激活函数.
2.4. 总结
理解模型训练过程,有助于得到能够泛化能力更好的模型,并在预测新图片类型时,得到更好的精度.
在这里,介绍了关于过拟合对于模型泛化能力的影响,以及过拟合的处理方法. 此外,还提到了学习率的重要性,以及典型值. 最后,还说明了最后一层合适的激活函数的重要性.
具体的图像分类器模型训练及迁移学习可参考:
Pytorch - torchvison.models 迁移学习与 Finetuning - AIUAI