原文 - Finetuning Torchvision Models
采用 PyTorch 的 torchvision.models 提供的预训练模型在新任务上进行 finetuning 的处理.
预训练的 PyTorch 模型是在 ImageNet 的 1000 类数据集进行的训练.
这里主要介绍 finetuning 和 feature extraction. 类似于迁移学习.
迁移学习主要处理有:
[1] - 初始化预训练模型;
[2] - 修改网络的最终输出网络层,以匹配新数据集中的类别数目;
[3] - 定义训练时的优化算法,即参数更新;
[4] - 运行训练迭代.
1. Inputs
采用的数据集: hymenoptera_data. 其包含 ants蚂蚁 和 bees蜜蜂 两种类别,且以 ImageFolder
dataset 的形式进行组织的.
# 数据集路径.
data_dir = "./datas/hymenoptera_data"
# 可选网络: [resnet, alexnet, vgg, squeezenet, densenet, inception]
model_name = "squeezenet"
# 数据集类别数
num_classes = 2
# 训练时的 batchsize
batch_size = 8
# 训练的迭代 epochs 数
num_epochs = 15
# 是否用于特征提取.
# 如果是 False, 则,finetune 整个模型.
# 如果是 True,则仅更新最后一层的网络层参数.
feature_extract = True2. Helper 函数
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
print("PyTorch Version: ",torch.__version__)
print("Torchvision Version: ",torchvision.__version__)
# PyTorch Version: 1.0.0
# Torchvision Version: 0.2.12.1. 模型训练和评价函数
train_model 函数辅助给定模型的训练和评价.
train_model 函数的输入包括:PyTorch 模型,dataloaders dict,loss 函数,优化器,训练和评价的 epochs 数,以及模型是否为 inception模型的布尔 flag.
参数 is_inception flag 用于 Inception V3 模型,其网络结构采用了辅助输出,且最终的总loss 是辅助输出loss 和最终输出loss 的和.
train_model函数会训练指定 epochs 数,并在每个 epoch 运行一次完整的评价(validation). 在每个 epoch 后,打印训练和评价精度.
train_model 函数还会保持对最佳效果模型的追踪(以评价精度为参考),并在训练后保存最佳效果模型.
如:
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25, is_inception=False):
since = time.time()
val_acc_history = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 每个 epoch 包含 training 和 validation phase.
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
# 计算模型输出及 loss.
# 对于 inception 模型,训练时,其还包括一个辅助 loss;
# 最终的 loss 是辅助 loss 和最终输出 loss 的两者之和.
# 但,测试时,只考虑最终输出的 loss.
if is_inception and phase == 'train':
outputs, aux_outputs = model(inputs)
loss1 = criterion(outputs, labels)
loss2 = criterion(aux_outputs, labels)
loss = loss1 + 0.4*loss2
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
if phase == 'val':
val_acc_history.append(epoch_acc)
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model, val_acc_history2.2. 设置模型参数的 .requires_grad 属性
将模型用于特征提取(feature extraction) 时,需要设置 .requires_grad=False.
默认情况下,在加载预训练模型时,所有参数的 .requires_grad 均为 .requires_grad=True,其有助于从头开始或 finetuning 的模型训练.
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False3. 网络初始化及设置
CNN 网络模型的最后一层网络层一般是 FC 层,其网络层输出节点数与数据集的类别数相一致.
由于预训练模型是基于 1000 类的 ImageNet 数据集的,故FC 层的输出 channels 数为 1000.
finetuning 和 feature-extraction 的区别:
[1] - 特征提取时,只需更新最后一层网络层的参数;即,只更新修改的网络层的参数,而对于未修改的其它网络层不进行参数更新. 故,效率起见,设置 .requires_grad=False.
[2] - 模型 finetuning 时,需要设置全部网络层的 .requires_grad=True(默认).
此外,除了 inception_v3 的网络输入尺寸为 (299, 299),其它模型的网络输入均为 (224, 224).
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
model_ft = None
input_size = 0
if model_name == "resnet":
"""
Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
"""
Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
"""
VGG11_bn
"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
"""
Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
"""
Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
"""
Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
# Handle the auxilary net
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# Handle the primary net
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size
# 模型初始化
model_ft, input_size = initialize_model(model_name,
num_classes,
feature_extract,
use_pretrained=True)
# 打印实例化后的模型
print(model_ft)如,model_name == "squeezenet":
SqueezeNet(
(features): Sequential(
(0): Conv2d(3, 96, kernel_size=(7, 7), stride=(2, 2))
(1): ReLU(inplace)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(3): Fire(
(squeeze): Conv2d(96, 16, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(16, 64, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(16, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(4): Fire(
(squeeze): Conv2d(128, 16, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(16, 64, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(16, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(5): Fire(
(squeeze): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(32, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(6): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(7): Fire(
(squeeze): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(32, 128, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(32, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(8): Fire(
(squeeze): Conv2d(256, 48, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(48, 192, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(48, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(9): Fire(
(squeeze): Conv2d(384, 48, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(48, 192, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(48, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(10): Fire(
(squeeze): Conv2d(384, 64, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
(11): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=True)
(12): Fire(
(squeeze): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))
(squeeze_activation): ReLU(inplace)
(expand1x1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(expand1x1_activation): ReLU(inplace)
(expand3x3): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(expand3x3_activation): ReLU(inplace)
)
)
(classifier): Sequential(
(0): Dropout(p=0.5)
(1): Conv2d(512, 2, kernel_size=(1, 1), stride=(1, 1))
(2): ReLU(inplace)
(3): AdaptiveAvgPool2d(output_size=(1, 1))
)
)4. 数据加载
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(input_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(input_size),
transforms.CenterCrop(input_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
print("Initializing Datasets and Dataloaders...")
# Create training and validation datasets
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
# Create training and validation dataloaders
dataloaders_dict = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=4) for x in ['train', 'val']}
# CPU/GPU 设定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")5. 优化器设置
# 模型放于 GPU
model_ft = model_ft.to(device)
# 收集待优化/待更新的参数.
# 如果是 finetuning,则更新全部网络参数;
# 如果是 feature extraction,则只更新 requires_grad=True 的参数.
params_to_update = model_ft.parameters()
print("Params to learn:")
if feature_extract:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)
# 所有参数均是待优化参数.
optimizer_ft = optim.SGD(params_to_update, lr=0.001, momentum=0.9)6. 模型训练和评价
# 设置 loss 函数
criterion = nn.CrossEntropyLoss()
# Train and evaluate
model_ft, hist = train_model(model_ft,
dataloaders_dict,
criterion,
optimizer_ft,
num_epochs=num_epochs,
is_inception=(model_name=="inception"))训练过程,如:
Epoch 0/14
----------
train Loss: 0.5821 Acc: 0.7131
val Loss: 0.4427 Acc: 0.8235
Epoch 1/14
----------
train Loss: 0.3180 Acc: 0.8852
val Loss: 0.3598 Acc: 0.8889
Epoch 2/14
----------
train Loss: 0.2433 Acc: 0.9139
val Loss: 0.3539 Acc: 0.9085
Epoch 3/14
----------
train Loss: 0.2661 Acc: 0.8852
val Loss: 0.3290 Acc: 0.9085
Epoch 4/14
----------
train Loss: 0.1970 Acc: 0.9344
val Loss: 0.3685 Acc: 0.9216
Epoch 5/14
----------
train Loss: 0.1849 Acc: 0.9180
val Loss: 0.3655 Acc: 0.9020
Epoch 6/14
----------
train Loss: 0.1696 Acc: 0.9303
val Loss: 0.3450 Acc: 0.9216
Epoch 7/14
----------
train Loss: 0.1757 Acc: 0.9139
val Loss: 0.3288 Acc: 0.9346
Epoch 8/14
----------
train Loss: 0.1402 Acc: 0.9385
val Loss: 0.3277 Acc: 0.9216
Epoch 9/14
----------
train Loss: 0.1484 Acc: 0.9426
val Loss: 0.3435 Acc: 0.9085
Epoch 10/14
----------
train Loss: 0.1154 Acc: 0.9590
val Loss: 0.3369 Acc: 0.9150
Epoch 11/14
----------
train Loss: 0.1190 Acc: 0.9549
val Loss: 0.3386 Acc: 0.9085
Epoch 12/14
----------
train Loss: 0.1292 Acc: 0.9303
val Loss: 0.3305 Acc: 0.9085
Epoch 13/14
----------
train Loss: 0.1207 Acc: 0.9385
val Loss: 0.3359 Acc: 0.9281
Epoch 14/14
----------
train Loss: 0.1203 Acc: 0.9508
val Loss: 0.3638 Acc: 0.9216
Training complete in 0m 19s
Best val Acc: 0.9346417. 是否迁移学习的模型对比
对比分析从头开始训练的模型与迁移学习的模型的效果.
finetuning 和 feature extraction 的效果表现,很大程度上取决于数据集的大小. 但,通常情况下,迁移学习训练的模型要优于从头开始训练的模型.
# 从头开始训练的网络模型.
scratch_model,_ = initialize_model(model_name,
num_classes,
feature_extract=False,
use_pretrained=False)
scratch_model = scratch_model.to(device)
scratch_optimizer = optim.SGD(scratch_model.parameters(), lr=0.001, momentum=0.9)
scratch_criterion = nn.CrossEntropyLoss()
_,scratch_hist = train_model(scratch_model, dataloaders_dict, scratch_criterion, scratch_optimizer, num_epochs=num_epochs, is_inception=(model_name=="inception"))
# 对于迁移学习模型和从头开始训练的模型,
# 画出验证精度的训练曲线 vs. 训练 epochs 数.
ohist = []
shist = []
ohist = [h.cpu().numpy() for h in hist]
shist = [h.cpu().numpy() for h in scratch_hist]
plt.title("Validation Accuracy vs. Number of Training Epochs")
plt.xlabel("Training Epochs")
plt.ylabel("Validation Accuracy")
plt.plot(range(1,num_epochs+1),ohist,label="Pretrained")
plt.plot(range(1,num_epochs+1),shist,label="Scratch")
plt.ylim((0,1.))
plt.xticks(np.arange(1, num_epochs+1, 1.0))
plt.legend()
plt.show()从头开始训练的模型,训练过程,如:
Epoch 0/14
----------
train Loss: 0.6967 Acc: 0.5205
val Loss: 0.6931 Acc: 0.5425
Epoch 1/14
----------
train Loss: 0.6965 Acc: 0.4754
val Loss: 0.6932 Acc: 0.4575
Epoch 2/14
----------
train Loss: 0.6919 Acc: 0.5041
val Loss: 0.6930 Acc: 0.4575
Epoch 3/14
----------
train Loss: 0.6912 Acc: 0.5410
val Loss: 0.6930 Acc: 0.4575
Epoch 4/14
----------
train Loss: 0.6837 Acc: 0.4959
val Loss: 0.6928 Acc: 0.4575
Epoch 5/14
----------
train Loss: 0.6880 Acc: 0.5697
val Loss: 0.6904 Acc: 0.4575
Epoch 6/14
----------
train Loss: 0.6669 Acc: 0.5943
val Loss: 0.8087 Acc: 0.4771
Epoch 7/14
----------
train Loss: 0.6818 Acc: 0.5820
val Loss: 0.6935 Acc: 0.4575
Epoch 8/14
----------
train Loss: 0.6811 Acc: 0.5615
val Loss: 0.6913 Acc: 0.4771
Epoch 9/14
----------
train Loss: 0.6649 Acc: 0.5861
val Loss: 0.6977 Acc: 0.5817
Epoch 10/14
----------
train Loss: 0.6598 Acc: 0.6025
val Loss: 0.6658 Acc: 0.6013
Epoch 11/14
----------
train Loss: 0.6717 Acc: 0.6107
val Loss: 0.6621 Acc: 0.6078
Epoch 12/14
----------
train Loss: 0.6641 Acc: 0.5943
val Loss: 0.6547 Acc: 0.6405
Epoch 13/14
----------
train Loss: 0.6611 Acc: 0.6189
val Loss: 0.6572 Acc: 0.5882
Epoch 14/14
----------
train Loss: 0.6206 Acc: 0.6352
val Loss: 0.6724 Acc: 0.6275
Training complete in 0m 29s
Best val Acc: 0.640523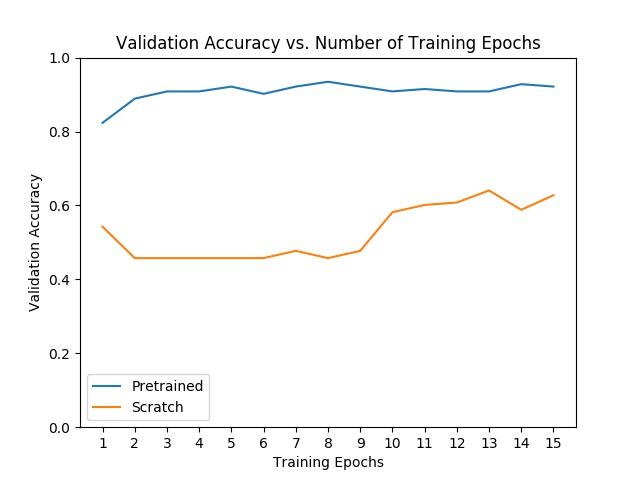
8. 思考
[1] - 在更复杂数据集上运行模型训练,分析迁移学习的效果.
[2] - 在新类型数据集进行迁移学习,如 NLP,音频等.
[3] - 模型训练后,可以导出为 ONNX 模型,或采用混合前端提高运行速度和优化效果(trace it using the hybrid frontend for more speed and optimization opportunities.)