转自: Keras如何做multi-task learning? - 知乎
作者:杨培文
1. Keras - Multi-task/Multi-label
类似于 FashionAI 天池竞赛 - 服饰属性识别赛后技术分享,知乎上的一个很好的回答.
FashionAI 服饰属性标签识别,就涉及到 Multi-task 问题. 一件服装可能需要识别袖子长度,也可能是需要识别裙子长度,还有可能识别裤子长度,如图:
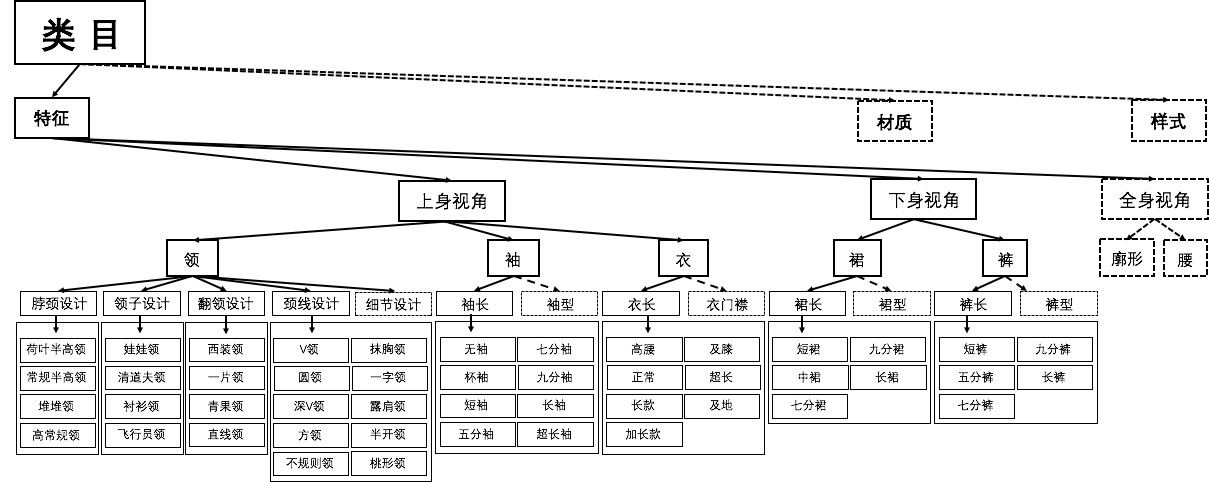
网络需要有多个输出,每个输出都是一个 Softmax 分类器.
FashionAI 即有以下几个分类,每个分类有不同的类别数:
label_count = {
'coat_length': 8,
'collar_design': 5,
'lapel_design': 5,
'neck_design': 5,
'neckline_design': 10,
'pant_length': 6,
'skirt_length': 6,
'sleeve_length': 9}FashionAI 中各类中包含的样本数:
'coat_length': 11320,
'collar_design': 8393,
'lapel_design': 7034,
'neck_design': 5696,
'neckline_design': 17148,
'pant_length': 7460,
'skirt_length': 9223,
'sleeve_length': 13299})对此,可以搭建如下的 Keras 多分类器模型:
base_model = InceptionResNetV2(weights='imagenet',
input_shape=(width, width, 3),
include_top=False,
pooling='avg')
input_tensor = Input((width, width, 3))
x = input_tensor
x = Lambda(inception_resNet_v2.preprocess_input)(x)
x = base_model(x)
x = Dropout(0.5)(x)
x = [Dense(count, activation='softmax', name=name)(x) for name, count in label_count.items()]
model = Model(input_tensor, x)搭建的多分类器模型的关键一行代码为:
x = [Dense(count, activation='softmax', name=name)(x) for name, count in label_count.items()]其遍历了 label_count 中的分类名称和对应的分类数量,分别搭建不同输出神经元数量的分类器,并为每个全连接层设置了对应的名称,以便于训练时观察每个分类的训练情况.
该模型可视化输出如图:

其实际上就是在与训练模型 InceptionResNetV2 输出的特征后接了多个分类器.
对应的 label 则按照真实 label 设定,如果对应分类不存在,设置全为 0 即可. 比如有裤子就没有裙子,则裙子对应的 label 就全是 0.
n = len(df)
y = [np.zeros((n, label_count[x])) for x in label_count.keys()]只需要把真实类别对应的位置设为 1,其他地方设置为 0 即可.
模型训练时,如果有很多全 0 的类别,可能会影响准确率的计算. 可以在训练完以后,自行计算准确率,也可以自定义一个 metric 函数.
该模型在测试集上取得了 0.9701 分数,证明了方案的可行性.
# 定义的准确率评估函数
# 仅计算 y_true 不为 0 的样本的准确率.
def acc(y_true, y_pred):
index = tf.reduce_any(y_true > 0.5, axis=-1)
res = tf.equal(tf.argmax(y_true, axis=-1),
tf.argmax(y_pred, axis=-1))
index = tf.cast(index, tf.float32)
res = tf.cast(res, tf.float32)
return tf.reduce_sum(res * index) / (tf.reduce_sum(index) + 1e-7)2. 训练实现
ypwhs/nasnet_fine_tuning_8clf_0.8850_0.9740.ipynb
#!--*-- coding:utf-8 --*--
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
n_gpus = len(os.environ['CUDA_VISIBLE_DEVICES'].split(','))
model_name = 'nasnet_fine_tuning_8clf_2'
import matplotlib.pyplot as plt
import random
import os
import cv2
from tqdm import tqdm
from glob import glob
import multiprocessing
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from collections import Counter
import keras.backend as K
import tensorflow as tf
from keras.layers import *
from keras.models import *
from keras.optimizers import *
from keras.applications import *
from keras.regularizers import l2
from keras.preprocessing.image import *
from keras.utils import multi_gpu_model
from IPython.display import display, Image
ali_attributes_dir = '/path/to/ali_attributes_datas/'
df = pd.read_csv(os.path.join(ali_attributes_dir, 'Annotations/label.csv'), header=None)
df.columns = ['filename', 'label_name', 'label']
df = df.sample(frac=1).reset_index(drop=True) # shuffle
df.label_name = df.label_name.str.replace('_labels', '')
display(df.head())
c = Counter(df.label_name)
label_count = dict([(x, len(df[df.label_name == x].label.values[0])) for x in c.keys()])
label_names = list(label_count.keys())
display(label_count)
fnames = df['filename'].values
width = 331
# n = len(df)
n = 100
y = [np.zeros((n, label_count[x])) for x in label_count.keys()]
for i in range(n):
label_name = df.label_name[i]
label = df.label[i]
y[label_names.index(label_name)][i, label.find('y')] = 1
# 多线程数据记载,X - datas
def f(index):
return index, cv2.resize(cv2.imread(os.path.join(ali_attributes_dir, fnames[index])), (width, width))
X = np.zeros((n, width, width, 3), dtype=np.uint8)
with multiprocessing.Pool(4) as pool:
with tqdm(pool.imap_unordered(f, range(n)), total=n) as pbar:
for i, img in pbar:
X[i] = img[:,:,::-1]
# train/valid 划分
n_train = int(n*0.8)
X_train = X[:n_train]
X_valid = X[n_train:]
y_train = [x[:n_train] for x in y]
y_valid = [x[n_train:] for x in y]
# DataGenerator 定义
class Generator():
def __init__(self, X, y, batch_size=32, aug=False):
def generator():
idg = ImageDataGenerator(horizontal_flip=True,
rotation_range=20,
zoom_range=0.2)
while True:
for i in range(0, len(X), batch_size):
X_batch = X[i:i+batch_size].copy()
y_barch = [x[i:i+batch_size] for x in y]
if aug:
for j in range(len(X_batch)):
X_batch[j] = idg.random_transform(X_batch[j])
yield X_batch, y_barch
self.generator = generator()
self.steps = len(X) // batch_size + 1
gen_train = Generator(X_train, y_train, batch_size=1, aug=True)
#
def acc(y_true, y_pred):
index = tf.reduce_any(y_true > 0.5, axis=-1)
res = tf.equal(tf.argmax(y_true, axis=-1), tf.argmax(y_pred, axis=-1))
index = tf.cast(index, tf.float32)
res = tf.cast(res, tf.float32)
return tf.reduce_sum(res * index) / (tf.reduce_sum(index) + 1e-7)
# NASNet 网络
base_model = NASNetLarge(weights='imagenet', input_shape=(width, width, 3), include_top=False, pooling='avg')
input_tensor = Input((width, width, 3))
x = input_tensor
x = Lambda(nasnet.preprocess_input)(x)
x = base_model(x)
x = Dropout(0.5)(x)
x = [Dense(count, activation='softmax', name=name)(x) for name, count in label_count.items()]
model = Model(input_tensor, x)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])
# 模型可视化
plot_model(model, show_shapes=True, to_file='model_simple.png')
SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))
# 单 GPU 模型训练
model.compile(optimizer=Adam(1e-4), loss='categorical_crossentropy', metrics=[acc])
model.fit_generator(gen_train.generator, steps_per_epoch=gen_train.steps, epochs=2, validation_data=(X_valid, y_valid))
# 多 GPUs 模型训练
model2 = multi_gpu_model(model, n_gpus)
# opt = SGD(1e-3, momentum=0.9, nesterov=True, decay=1e-5)
model2.compile(optimizer=Adam(1e-4), loss='categorical_crossentropy', metrics=[acc])
model2.fit_generator(gen_train.generator, steps_per_epoch=gen_train.steps, epochs=2, validation_data=(X_valid, y_valid))
model2.compile(optimizer=Adam(1e-5), loss='categorical_crossentropy', metrics=[acc])
model2.fit_generator(gen_train.generator, steps_per_epoch=gen_train.steps, epochs=3, validation_data=(X_valid, y_valid))
model2.compile(optimizer=Adam(1e-6), loss='categorical_crossentropy', metrics=[acc])
model2.fit_generator(gen_train.generator, steps_per_epoch=gen_train.steps, epochs=1, validation_data=(X_valid, y_valid))
# 模型保存 .h5 文件
model.save('model_%s.h5' % model_name)
#计算验证集准确率
y_pred = model2.predict(X_valid, batch_size=128, verbose=1)
a = np.array([x.any(axis=-1) for x in y_valid]).T.astype('uint8')
b = [np.where((a == np.eye(8)[x]).all(axis=-1))[0] for x in range(8)]
for c in range(8):
y_pred2 = y_pred[c][b[c]].argmax(axis=-1)
y_true2 = y_valid[c][b[c]].argmax(axis=-1)
print(label_names[c], (y_pred2 == y_true2).mean())
counts = Counter(df.label_name)
s = 0
n = 0
for c in range(8):
y_pred2 = y_pred[c][b[c]].argmax(axis=-1)
y_true2 = y_valid[c][b[c]].argmax(axis=-1)
s += counts[label_names[c]] * (y_pred2 == y_true2).mean()
n += counts[label_names[c]]
print(s / n)
# 在测试集上预测结果
df_test = pd.read_csv(os.path.join(ali_attributes_dir, 'Tests/question.csv'), header=None)
df_test.columns = ['filename', 'label_name', 'label']
fnames_test = df_test.filename
n_test = len(df_test)
df_test.head()
def f(index):
return index, cv2.resize(cv2.imread(os.path.join(ali_attributes_dir, fnames_test[index])), (width, width))
X_test = np.zeros((n_test, width, width, 3), dtype=np.uint8)
with multiprocessing.Pool(12) as pool:
with tqdm(pool.imap_unordered(f, range(n_test)), total=n_test) as pbar:
for i, img in pbar:
X_test[i] = img[:,:,::-1]
y_pred = model2.predict(X_test, batch_size=128, verbose=1)
for i in range(n_test):
problem_name = df_test.label_name[i].replace('_labels', '')
problem_index = label_names.index(problem_name)
probs = y_pred[problem_index][i]
df_test.label[i] = ';'.join(np.char.mod('%.8f', probs))