原文:FashionAI全球挑战赛-服饰属性识别赛后技术分享
作者:孙立波
日期: 2018//06/06
1. 创新方法
阿里天池的 FashionAI 竞赛中的服饰标签属性识别,是对不同衣服属性进行多分类识别的问题,其中服装属性共有八个:
[1] - collar_design 领子设计
[2] - lapel_design 翻领设计
[3] - neck_design 脖颈领设计
[4] - neckline_design 颈线领设计
[5] - coat_length 衣长
[6] - sleeve_length 袖长
[7] - pant_length 裤长
[8] - skirt_length 裙长
如图:
图1. 竞赛属性框架示意图
关于该竞赛,进行了很多尝试和探索,积累的很多有意思的方法,这里进行分享.
主要包括四个方面:
1.1 模特与平铺图像的精确分类(mAP:0.9986)
之所以要做模特与 平铺图像的粗粒度分类,是因为在第二轮复赛的数据集中,新加入了大量的平铺图像,如图:

图2:Length 相关的服装属性的平铺图像
在第一轮的初赛数据集中,只含有模特,且大多数的数据样本为直立的模特,比较容易识别.
采用了基于 InceptionResNetV2 网络的多任务联合训练方法得到的单个模型,就获得了具有竞争性的识别性能.
具体地,将第一轮初赛的训练数据集和所有的初赛测试数据集整合一起,采用八任务的模型训练方法,得到了非常好的 Basic Precision 验证性能:
coat_length_labels 0.8785
collar_design_labels 0.9126
lapel_design_labels 0.9230
neck_design_labels 0.9066
neckline_desing_labels 0.8909
pant_length_labels 0.8988
skirt_length_labels 0.9115
sleeve_length_labels 0.9118将该模型应用到第二轮复赛数据集上观察模型的泛化性能. 如图:
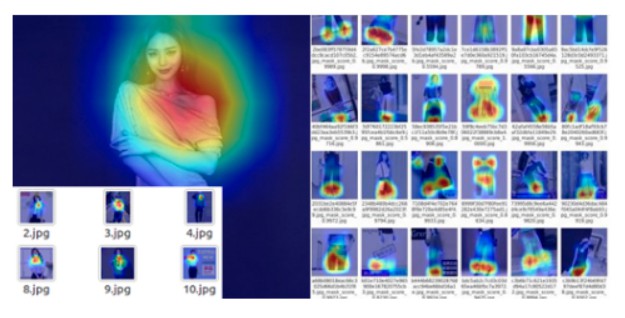
图 3-1 服饰属性标签识别的 heatmap 可视化
对于 design 相关服装属性的多分类任务,模型可以很好的聚焦于模特的相关部位;
对于 length 相关服装属性的多分类任务,模型一般关注与模特的相互位置关系,如 pant_length(裤长),模型更关注于模特的腰部或脚部等位置;
但对于服装平铺图,模型预测的响应区域则无规律的,即也表明了 模特图像与平铺图像的不一致性.
进一步的,当将该模型应用到第二轮复赛的训练数据集上进行训练时,却发现训练效果很差. 尤其是对于 Length 相关的服饰属性类别识别方面,性能损耗非常大. 通过观察 Length 相关属性的数据样本,发现,训练集中含有大量的坐卧、仰躺等复杂模特姿态和平铺图像. 如图. 复杂模特姿态与平铺图像数据分布的不一致性,等因素,均是模型泛化能力较差的原因.

图 3-2 Length 服装属性的样本多样性
如图 4-1 和 4-2,是初赛和复赛的数据集的数据统计属性. 可知,图 4-1 中每个属性的总体抽样数据分布特性(如,各属性下各类别的样本均衡性),基本上初赛和复赛的数据特性保持一致. 但,图 4-2 柱状统计图中,复赛的 Length 属性存在更多的 m标记样本. 这也是导致 Length 相关属性难以分类识别的重要原因.

图 4-1 初赛和复赛训练集的数据分布柱状图(上,初赛数据;下,复赛数据. [截图很模糊])

图 4-2 初赛和复赛训练集中m 标记的数据分布柱状图(上,初赛数据;下,复赛数据)
进一步分析,发现,m 标记的数据样本大部分来自于 Length 相关属性的平铺图像样本中, 如图 5-1 和 5-2. 这是由训练的模型与平铺图像的多任务二分类器得到的结论.
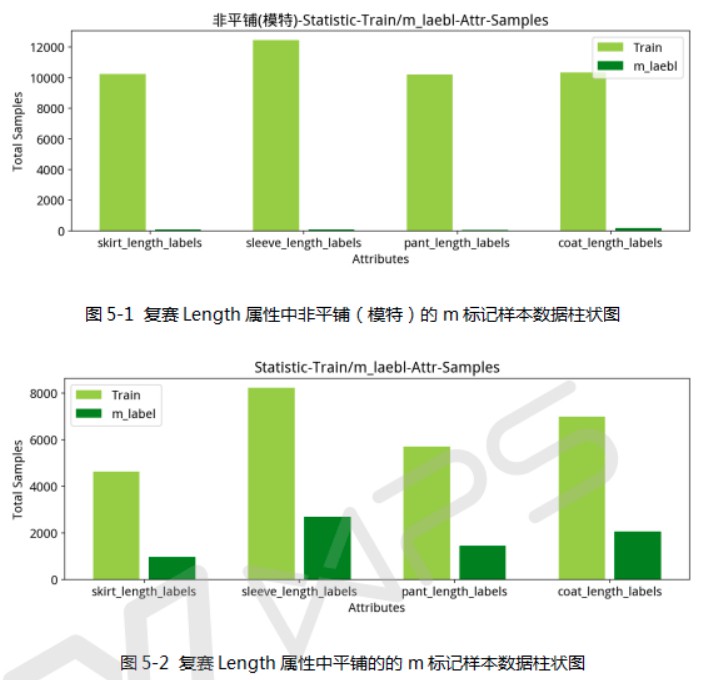
下文中,将 Length 的模特图像也统称为 Length 非平铺数据或 Length 非平铺图像,以与 Length 相关属性的平铺图像进行更好的对比和区别.
由图 5-1 和 5-2 可知,平铺和非平铺图像样本的比例接近于 1:1, 且 m标记样本大部分来自于平铺数据. 而,m标记样本越多的服装属性,在之后的实验说明中,发现其模型识别的准确率,相对于 m 标记样本较少的 Length 属性,性能会较差. 因此,改进 m 标记维度的类别分类性能的提升是模型准确率提升的关键.
至此,数据分析后,下面详细介绍高精度多任务二分类模型训练及网络结构设计.
1.1.1 网络结构设计
Length 相关的四个属性: coat_length, pant_length, skirt_length 和 sleeve_length,设计了基于 ResNet50 的四任务二分类网络.
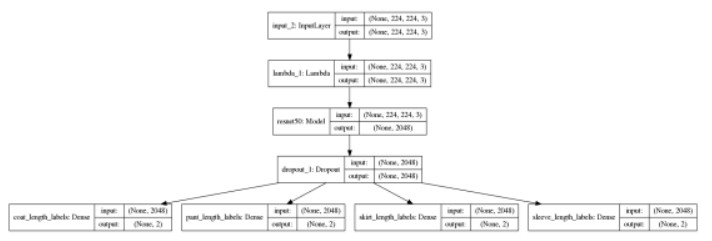
图 6 基于 ResNet50 的四任务二分类网络
1.1.2 训练策略
[1] - 第一次筛选 - 无人工筛选
参考论文:[Look into Person: Joint Body Parsing & Pose Estimation Network and A New Benchmark - TPAMI2018]()
如图 7,该论文提出的 LIP-JPPNet 可以很好的解析人体部位和识别服饰.

图 7 LIP-JPPNet Human Parsing
基于 JPPNet,设置了强约束条件,保证筛选出的 Length 的平铺图像都是正确的.
具体的筛选条件是:
根据以下的类别,对每张测试图片中含有 Hair/Face/LeftArm/RightArm/LeftLeg/RightLeg/LeftShoe/RightShoe 其中之一部位的判定为非平铺(模特)图片;反之,则为平铺图片.

最终,在复赛训练数据集上筛选出的平铺图片数量如图. 鉴于模型的局限性,此时归为非平铺图像的数据集中仍包含大量难以识别的平铺图片.

[2] - 第二次筛选
采用 Mask R-CNN 和 JPPNet 联合进行第二次筛选.
对于归为非平铺图像的数据集上,继续筛选平铺图片.
筛选策略为:
如果图片属于pant length 属性或 skirt length 属性,由于 JPPNet 会有大量错检,且没有 Mask R-CNN 检测全面,因此,仅使用 Mask R-CNN 做筛选(即,有无 person 了别,阈值=0.4,强约束.)
如果图片属于 coat length 属性或 sleeve length 属性,则采用 Mask R-CNN 和 JPPNet 做联合筛选.
得到的平铺图片数量如图:

PS: 需要人工去除精选数据中 10 个模特样本.
[3] - 第一次训练
在二次精选后的 Length 平铺数据集和初赛的模特数据集上训练 四任务的二分类网络. 采用 SGD 优化器(opt=SGD(1e-3, momentum=0.9, nesterov=True, decay=0.001/40)),得到的验证准确率为:
coat_length_labels 0.9972
pant_length_labels 0.9942
skirt_length_labels 0.9962
sleeve_length_labels 0.9987
mAP 0.9966当采用训练的模型用于二次筛选后的归为非平铺数据集上进行平铺与非平铺二分类时,发现,平铺图片大部分都能被分出来(即,归为非平铺图像的数据中几乎没有平铺图片);但归为平铺数据中会含有少量的模特,其中包含很多复杂姿态或被物体遮挡的模特.
为了得到更准确的分类器,筛选出平铺样本中的困难样本,进行再次训练.
[4] - 第二次训练: 硬样本挖掘 + 样本均衡采样
采用初赛的测试集 + 复赛分出来的非平铺数据作为训练用的非平铺数据集,然后使用最新得到的平铺数据作为平铺数据集,进行四任务的联合训练,得到一个初始的高性能分类模型,进一步筛选出复赛数据中归为平铺数据的难分类样本;然后,不再使用初赛的数据集,只利用复赛数据集,对每个属性的各类别的样本进行了样本数量上的均衡采样,且保证之前筛选出的难样本留到采样到的数据集中,再进行用上次模型的权重参数初始化该次模型的训练权重参数,再次进行更有效的四任务的二分类训练. 采用多分类的交叉熵损失函数,SGD+Adam 进行训练.
SGD(1e-3, momentum=0.9, nesterov=True, decay=0.01/40)/epoch=3
Adam(1e-6)/epoch=1
得到的验证准确率为:
coat_length_labels 0.9960
pant_length_labels 0.9987
skirt_length_labels 1.0
sleeve_length_labels 0.9995
mAP 0.99861.1.3 总结
通过该网络结构设计和训练策略,得到了一个非平铺(模特)与平铺图像的精确分类模型.
该模型作为一种数据预处理的手段,能够很好的对复赛 Lenght 数据集上的平铺与非平铺图像进行分类,以便于后续的多任务多通道网络设计与训练.
PS: 另外,基于同样的策略,还训练了基于 InceptionResNet 的四任务分类模型,对于复赛的 test_b 数据集,ResNet 模型无需人工筛选,只有 9-10 张错误分类的图片;而 InceptionResNet 模型有 60 张错分图片. 故,最终选择了更优的 ResNet 多任务二分类模型用于测试数据集.
2. 基于同域渐变自适应思想的训练策略
[Learning Deep Feature Representations with Domain Guided Dropout for Person-identification - 2016]()
考虑到 design 相关的服装属性不含有平铺图像,而 Length 含有大量的平铺图像. 因此,直觉上,为 design 的四个服装属性设计一个四任务属性识别的多分类网络.
同样地,采用相同的网络结构(只有最后输出的全连接层不同),设计 design 四个服装属性的多分类网络.
以 design 四任务服装属性的多分类网络的设计与训练为例.
Design 相关服装属性:
[1] - collar_design 领子设计
[2] - lapel_design 翻领设计
[3] - neck_design 脖颈领设计
[4] - neckline_design 颈线领设计
网络结构如图:
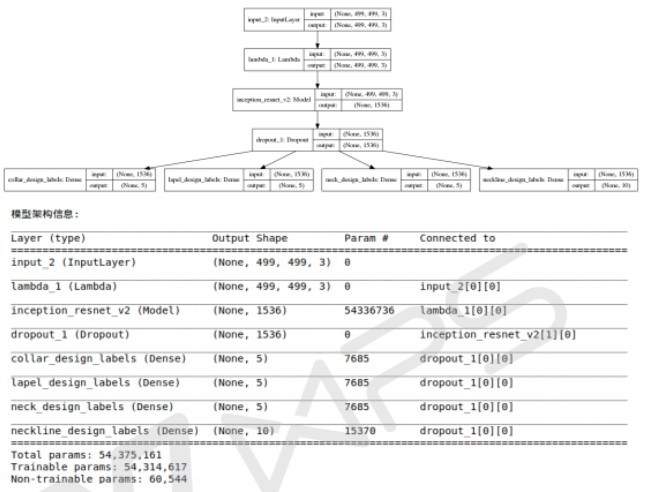
图8 design-model 网络结构描述
2.1 训练策略
基于域迁移自适应思想,设计了一种训练策略,使得模型的识别率提升了近 2 个百分点.
以下迭代训练中,统一采用统一网络架构,数据增强为水平镜像,20度内随机旋转.
具体训练策略如下:
[1] - design model 在 FashionAI 的初赛数据集 + 测试数据集上训练,训练图片尺寸为 499x499,优化器及迭代次数设置:
SGD(1e-2, momentum=0.9, nesterov=True, decay=0.01/40)/epochs=3
Adam(1e-4)/epochs=2
Adam(1e-5)/epochs=3
Adam(1e-6)/epochs=2
Adam(1e-7)/epochs=1
验证性能:
collar_design_labels 0.8944
lapel_design_labels 0.9268
neck_design_labels 0.8860
neckline_design_labels 0.8968[2] - design-model 采用 [1] 中训练模型的权重作为初始化权重,在 FashionAI 的复赛数据集 + 测试数据集上训练,训练图片尺寸为 499x499,优化器及迭代次数设置:
SGD(1e-4, momentum=0.9, nesterov=True, decay=0.01/40)/epochs=1
Adam(1e-5)/epochs=3
Adam(1e-6)/epochs=2
Adam(1e-7)/epochs=1
验证性能:
collar_design_labels 0.8913
lapel_design_labels 0.8579
neck_design_labels 0.8456
neckline_design_labels 0.8629[3] - design-model 采用 [2] 中训练模型的权重作为初始化权重,在 FashionAI 的复赛数据集上训练,训练图片尺寸为 499x499,优化器及迭代次数设置:
SGD(1e-4, momentum=0.9, nesterov=True, decay=0.01/40)/epochs=1
Adam(1e-5)/epochs=2
Adam(1e-6)/epochs=1
Adam(1e-7)/epochs=1
验证性能:
collar_design_labels 0.9084
lapel_design_labels 0.8699
neck_design_labels 0.8505
neckline_design_labels 0.87532.2 总结
该训练策略上的创新,是直觉上的.
通过实验验证了方法的有效性,使多任务模型在测试集上得到了更好的性能表现. 整体上,在复赛的 test_a 数据集上评测结果表明,性能提升非常明显,score 由之前的 0.9233 提升到了 0.9412.
3. 基于 Length 属性多分类识别的多任务双通道网络设计与实现
为了更好的识别 Length 相关的服装属性类别,考虑了 Length 属性分类模型的复杂性.
首先训练了一个高精度的平铺和非平铺图像的二分类预处理模型;然后,训练了基于多任务属性分类模型和基于多任务属性分类的平铺图片识别模型.
另外,考虑到 Length 相关属性中存在 模特 和 平铺图像域的不一致性和负载型,以及 Length 相关属性数据集中存在大量的 m标记样本问题,基于前述训练的两个多任务模型,设计了双通道的 Length 属性特征提取网络,从而增强了各属性的特征表达,取得了更佳的识别效果.
具体地,
针对 Length 非平铺数据,采用了上述提到的渐变自适应的训练策略,并和 design-model 采用了同一网络结构,训练得到的模型具有更好的分类性能.
3.1 标签平滑
针对 Length 平铺数据,考虑 m标记样本对模型训练造成的影响,采用了广义的标签平滑,对 y和 m临近位进行了标签平滑:
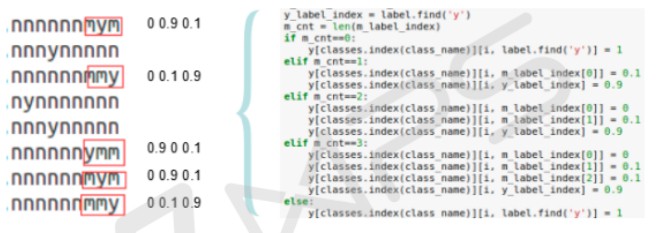
图 9 标签平滑策略示意图
如图 9 所示,以 sleeve length 服装属性的分类为例,m标记样本往往是人为主观标记的,且存在于 label 的后四位中.
当 m_cnt=0,即 label 中有 0 个 m 标记时,则让 label 的 y位置索引对应的标签向量赋值为 1;
当 m_cnt=1,即 label 中有 1 个 m 标记时,则让 label 的 m位置索引对应的标签向量赋值为 0.1, y位置索引对应的标签向量赋值为 0.9;
当 m_cnt=2,即 label 中有 2 个 m 标记时,则让 label 的倒数第一个 m位置索引对应的标签向量赋值为 0.1, y位置索引对应的标签向量赋值为 0.9;
当 m_cnt=3,即 label 中有 3 个 m 标记时,则让 label 的倒数两个 m位置索引对应的标签向量赋值为 0.1, y位置索引对应的标签向量赋值为 0.9.
3.2 网络结构
网络结构如下:
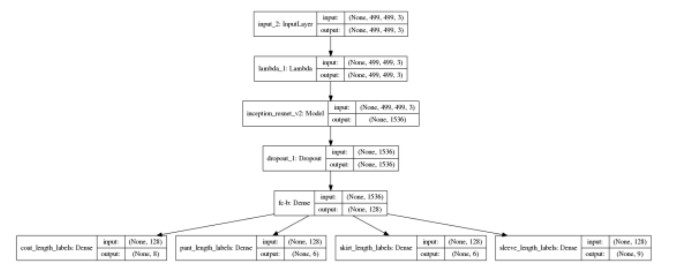
图 10 Length 服装属性的平铺图像的多任务分类模型
训练图片尺寸为 499x499,数据增强为水平镜像,20度内随机旋转. 优化器及迭代次数设置:
SGD(1e-2, momentum=0.9, nesterov=True, decay=0.01/40)/epochs=1
SGD(1e-3, momentum=0.9, nesterov=True, decay=0.01/40)/epochs=1
Adam(1e-5)/epochs=4
Adam(1e-6)/epochs=3
验证性能:
coat_length_labels 0.7331
pant_length_labels 0.7861
skirt_length_labels 0.7155
sleeve_length_labels 0.7180由于 coat 和 sleeve 中含有大量的 m 标记样本,往往这两个服装属性的多分类性能会比较差.
通过标签平滑和网络训练策略,明显的提升了这两个服装属性的分类效果,其中,coat 属性的识别准确率提升了近 5 个百分点.
为了进一步提升 Length 属性的分类性能,又对上述两个但模型进行整合,设计了一种基于 InceptionResNetV2 的双通道网络结构,如图:
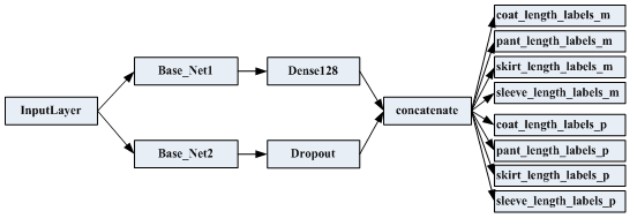
图 11 双通道网络
该网络训练的初始权重基于上述的 Length 平铺与非平铺多任务模型,这两个单模型分别记为 base1 和 base2. 在此基础上进行 finetune,同样采用了标签平滑.
另外,训练过程中,先冻结 base1 和 base2 的网络层,然后在复赛数据集上进行 finetune 训练,采用的优化器和迭代次数是 :
SGD(1e-4, momentum=0.9, nesterov=True, decay=0.01/40)/epochs=1
Adam(1e-5)/epochs=2
Adam(1e-6)/epochs=1
最终的验证 acc 性能是:
coat_length_labels 0.7535
pant_length_labels 0.8773
skirt_length_labels 0.8283
sleeve_length_labels 0.80253.3 总结
设计了一个双通道的特征提取和识别网络,其具有更优的识别性能. 在复赛测试数据集 test_b 上的验证结果表明,结合 design 相关服装属性,使用描述的训练策略得到的模型,单模型 Score 达到了 0.9467,Basic Precision=0.8448.
4. 其它创新点及改进
4.1 标签扩展
除了标签平滑方法,针对 m 标记比较多的 coat length 和 sleeve length 属性,还提出了一种标签扩展方法,即:对每个 label 标签向量的后两位进行扩展,当字符串 label 的 y 索引在倒数后两位时,对应原标签向量的后两位扩展的方式为:
$yn \rightarrow 1000; ym \rightarrow0100; my \rightarrow0010; ny \rightarrow 0001$
当字符串 label 的 y 字符不在倒数后两位时,直接给对应的 label 向量的 y 索引位置赋值为 1. 部分代码如下:
for i in range(n):
class_name = df['class'][i]
addlabel = int(df['addlabel'][i])
label = df['label'][i]
tmp1 = df['label'][i][:-2]
tmp2 = df['label'][i][-2:]
new_idx = classes.index(class_name) # + offset
if class_name in ['coat_length_labels_pingpu', 'sleeve_length_labels']:
if tmp1.find('y'):
y[new_idx][i, label.find('y')]=1
else:
idx = label.find('y')
if tmp2.find('y') == 0 andd tmp.find('m') == -1:
y[new_idx][i, idx] =1
elif tmp2.find('y') == 0 andd tmp.find('m') == 1:
y[new_idx][i, idx+1] =1
if tmp2.find('y') == 1 andd tmp.find('m') == 0:
y[new_idx][i, idx+1] =1
if tmp2.find('y') == 1 andd tmp.find('m') == -1:
y[new_idx][i, idx+2] =1
else:
y[classes.index(class_name)][i, label.find('y')] = 1标签扩展的网络设计如下:
base_model = InceptionResNetV2(weights='imagenet',
input_shape=(width, width, 3),
include_top=False,
pooling='avg')
# InceptionResNetV2.Xception
input_tensor = Input((width, width, 3))
x = input_tensor
x = Lambda(keras.applications.inception_v3.preprocess_input)(x)
x = base_model(x)
x = Dropout(0.5)(x)
x = Dense(128,
activation='relu',
kernel_initializer=initializers.he_uniform(seed=2018),
name='fc-b')(x)
x = [Dense(label_count['coat_length_labels'],
activation='softmax',
name='coat_length_labels' + 'slb')(x),
Dense(label_count['pant_length_labels'],
activation='softmax',
name='pant_length_labels' + 'slb')(x),
Dense(label_count['skirt_length_labels'],
activation='softmax',
name='skirt_length_labels' + 'slb')(x),
Dense(label_count['sleeve_length_labels'],
activation='softmax',
name='sleeve_length_labels' + 'slb')(x) ]验证 acc 性能:
coat_length_labels 0.7189
pant_length_labels 0.7610
skirt_length_labels 0.7039
sleeve_length_labels 0.7180实验结果与之前未采用标签扩展策略的相比,coat 和 sleeve 服装属性的识别准确率有了明显的提升.
4.2 裁剪策略
单模型进行预测时,对输入模型的每张图片会进行 10crops 裁剪处理和图片微角度的随机旋转,具体的裁剪方式是,由四角裁剪和中心裁剪经过镜像操作得到每张图片对应的 10 个 crops,然后对其做 20度范围内的随机旋转,分别进行预测,并最终取均值为该图片最终的预测概率.
以 1.2 中的 design-model 为例,测试三种裁剪策略,并在训练集上测试,说明裁剪 + 旋转策略的有效性.

实验结果表明,有效的裁剪策略,可以使预测输出的 acc 准确率提升 1-2 个百分点.
2. AI+时尚的技术变革
作者的总结,这里直接截图了.

3. 大赛总结

