论文:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications - 2017
作者:Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
团队:Google
slim - mobilenet_v1.py
MobileNet-Caffe
pytorch-mobilenet
MobileNets,有效的平衡了延迟(latency)和精度(accuracy),可用于移动和嵌入式视觉应用中.
MobileNets 基于流水线式的网络结构,采用深度可分离卷积(depthwise sparable convolutions) 构建的权重轻量型深度网络.
1. MobileNet 网络结构
MobileNet 基于 depthwise separable filters.
1.1 深度可分离卷积 Depthwise Separable Convolution
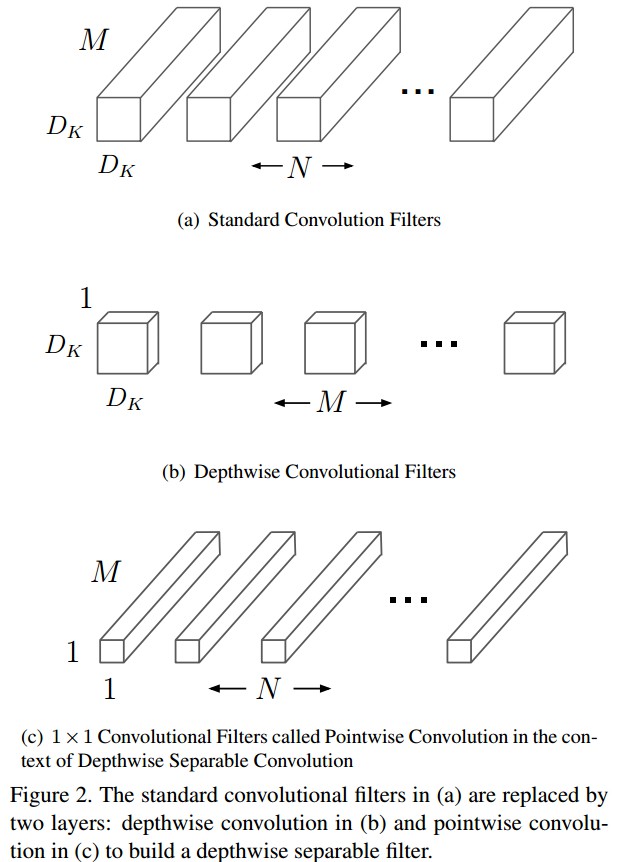
深度可分离卷积,是一种分解的卷积操作,其将标准卷积分解为一个 depthwise 卷积和一个 1x1 pointwise 卷积.
对于 MobileNets,depthwise 卷积分别对每个输入通道(input channel) 应用单个 filter 操作. 然后,pointwise 卷积采用 1x1 卷积来组合 depthwise 卷积的输出.
标准卷积是将所有的 filters 和 inputs 一次性的操作输出. 而,depthwise separable 卷积是分为了两层,一个分离(separable)层进行卷积操作和一个分离层进行组合. 这种方式能够显著的减少计算量和模型大小. 如图:
标准卷积网络层的输入为 ${D_F \times D_F \times M }$ 的特征图,并输出 ${D_G \times D_G \times N}$ 的特征图 $\mathbf{G}$,其中 ${D_F}$ 是方形输入特征图的尺寸(width, height),${M}$ 是输入通道数(输入特征图的深度, input depth),${D_G}$ 是卷积输出的方形特征图的尺寸,${N}$ 是输出通道数(输出特征图的深度, output depth).
标准卷积层的参数化为:${D_K \times D_K \times M \times N}$,其中,${\mathbf{K}}$ 是卷积核,${D_K}$ 是卷积核的维度(一般假设是方形的),${M}$ 和 ${N}$ 分别为输入和输出通道数.
标准卷积的输出特征图的计算为(假设步长为1,padding):
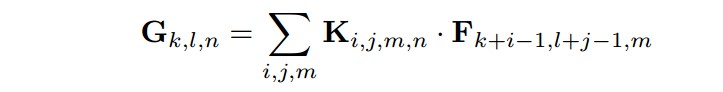
其计算量为:${D_K \times D_K \times M \times N \times D_F \times D_F}$
卷积层的计算量主要取决于输入通道数 M,输出通道数 N,卷积核尺寸 ${D_k \times D_k}$ 和特征图尺寸 ${D_F \times D_F}$.
MobileNet 模型分别对每一项和它们间的相互影响进行处理. 首先采用 depthwise separable 卷积分离输出通道数和卷积核尺寸间的相互影响.
标准卷积操作具有基于卷积核和组合特征的联合作用,以产生新表示的效果. 采用 depthwise separable 卷积操作,可以将卷积核操作和组合操作可以分为两步处理,以减少计算量.
Depthwise separable 卷积操作包括两层:depthwise 卷积和 pointwise 卷积.
depthwise 卷积 - 采用单个卷积核分别处理每个输入通道(输入深度)
pointwise 卷积 - 1x1 卷积,用于创建 depthwise 层输出的线性组合.
MobileNets 在 depthwise 卷积和 pointwise 卷积中均采用了 batchnorm 和 ReLU 非线性层.
Depthwise 卷积对每个输入通道采用一个 filter 的处理为:
其中,${\hat{\mathbf{K}}}$ 是 depthwise 卷积核的尺寸,${D_K \times D_K \times M} $;${\hat{\mathbf{K}}}$ 的第 ${m}$ 个 filter 应用到 ${\mathbf{F}}$ 的第 ${m}$ 个通道,以得到输出特征图 ${\hat{\mathbf{G}}}$ 的第 ${m}$ 个通道.
Depthwise 卷积的计算量为:${D_K \times D_K \times M \times D_F \times D_F}$
Depthwise 卷积相对于标准卷积操作而言,效率更高. 但是,其仅对输入通道进行 filters 操作,并没有组合各通道的输出为新特征. 因此,需要添加新网络层,通过 1x1 卷积来计算 depthwise 卷积输出的线性组合,以生成新特征.
Depthwise separable 卷积的计算量为:${D_K \times D_K \times M \times D_F \times D_F + M \times N \times D_F \times D_F}$. (depthwise 卷积和 1x1 pointwise 卷积的计算量之和.)
相对于标准卷积操作,计算量减少了:
${ \frac{D_K \times D_K \times M \times D_F \times D_F + M \times N \times D_F \times D_F}{D_K \times D_K \times M \times N \times D_F \times D_F} = \frac{1}{N} + \frac{1}{D_K^2} }$
MobileNet 采用 3x3 depthwise separable 卷积,其计算量仅有标准卷积的九分之一到八分之一,且精度损失很小.
1.2 MobileNet 网络结构和训练
MobileNet 网络结构如 Table 1.
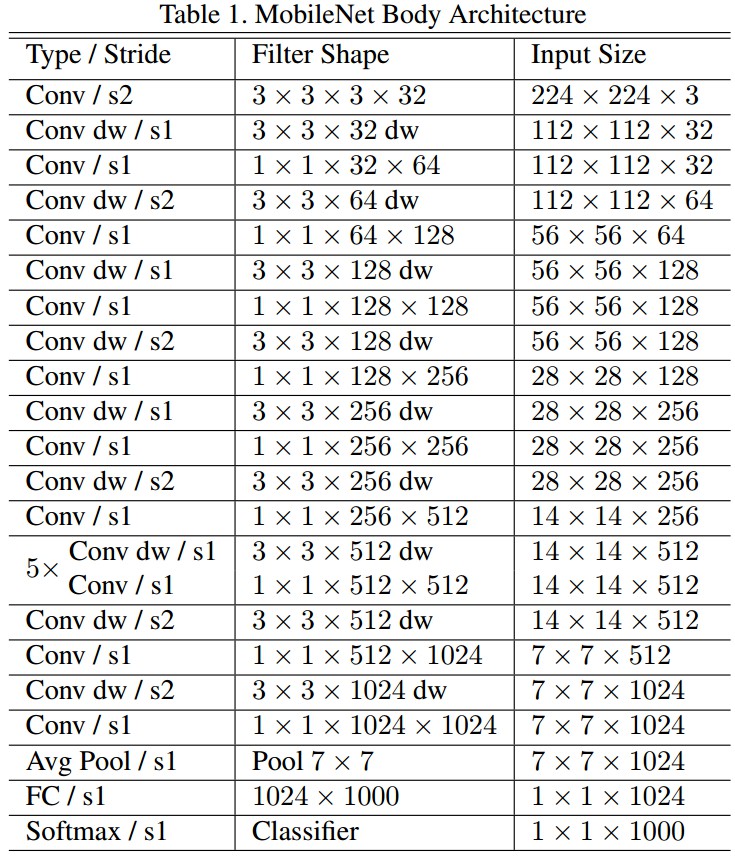
MobileNet 所有层后都接 batchnorm 和 ReLU 非线性激活层,最后送入 softmax 层以输出分类概率.

MobileNet 的下采样是通过 depthwise 卷积的带步长卷积才实现的. 最后的平均池化层将特征图分辨率减少到 1,再送入全连接层.
MobileNet 网络结构中,将 depthwise 卷积和 pointwise 卷积作为独立网络层计算的话,共 28 层.
MobileNet 采用 TensorFlow 进行训练,考虑到小模型的过拟合问题,训练时未过多的使用正则化和数据增强技术.
1.3 宽度因子: 模型更瘦和分辨率因子: 减少表示参数
虽然 base MobileNet 网络结构已经很小,延迟性很少,但在特定领域中可能需要模型更小更快.
对此,提出一个简单的参数 - 宽度因子(width multiplier) ${\alpha}$,用于在每一层均匀的将网络变瘦变小.
对于给定网络层和宽度因子 ${\alpha}$,则输入通道数 ${ M }$ 变为 ${ \alpha M}$,输出通道数 ${N}$ 变为 ${ \alpha N}$.
带宽度因子的 depthwise separable 卷积层的计算量为:${D_K \times D_K \times \alpha M \times D_F \times D_F + \alpha M \times \alpha N \times D_F \times D_F}$.
其中,${\alpha \in (0, 1]}$,典型值为 1,0.75,0.5 和 0.25.
${\alpha = 1}$ 即为 baseline MobileNet;
${\alpha < 1}$ 为 reduced MobileNets.
宽度因子有助于减少计算量,参数量大约减少为 ${\alpha ^2}$.
减少神经网络计算量的第二个超参数 - 分辨率因子(resolution multiplier) ${\rho}$.
对网络的输入图片和网络每一层的特征表示采用分辨率因子,可以有效减少模型参数.
${\rho} \in (0, 1]$,典型值将网络的输入分辨率设置为 224,192,160 或 128.
${\rho = 1}$ 即为 baseline MobileNet;
${\rho < 1}$ 为 reduced MobileNets.
分辨率因子也有助于减少计算量,参数量大约减少为 ${\rho ^2}$.
对此,带宽度因子和分辨率因子的 depthwise separable 卷积的计算量为:${ D_K \times D_K \times \alpha M \times \rho D_F \times \rho D_F + \alpha M \times \alpha N \times \rho D_F \times \rho D_F}$.
例如,Table3 所示:
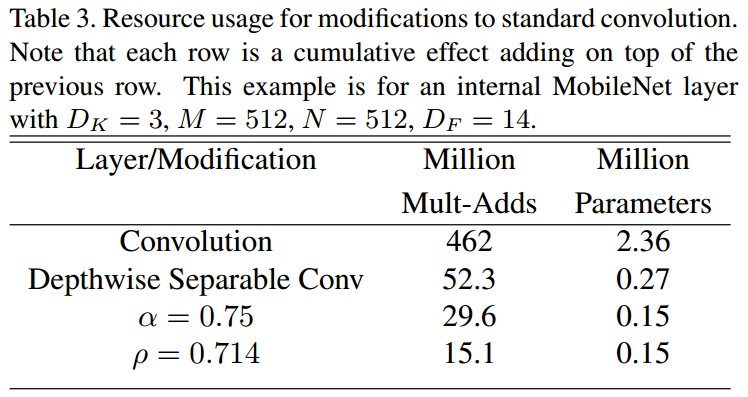
表格中,第一行是采用全卷积层的 Mult-Adds 和参数,其输入特征图为 14x14x512,卷积核 ${K}$ 为 3x3x512x512.
2. MobileNets 网络结构定义
2.1 MobileNets TF-Slim 实现
slim/nets/mobilenet_v1.py
MobileNet v1 网络结构.
可根据应用场景,选择不同的输入尺寸和输出,如识别,定位和分类.
100% Mobilenet V1 (base) with input size 224x224:
See mobilenet_v1()
Layer params macs
--------------------------------------------------------------------------------
MobilenetV1/Conv2d_0/Conv2D: 864 10,838,016
MobilenetV1/Conv2d_1_depthwise/depthwise: 288 3,612,672
MobilenetV1/Conv2d_1_pointwise/Conv2D: 2,048 25,690,112
MobilenetV1/Conv2d_2_depthwise/depthwise: 576 1,806,336
MobilenetV1/Conv2d_2_pointwise/Conv2D: 8,192 25,690,112
MobilenetV1/Conv2d_3_depthwise/depthwise: 1,152 3,612,672
MobilenetV1/Conv2d_3_pointwise/Conv2D: 16,384 51,380,224
MobilenetV1/Conv2d_4_depthwise/depthwise: 1,152 903,168
MobilenetV1/Conv2d_4_pointwise/Conv2D: 32,768 25,690,112
MobilenetV1/Conv2d_5_depthwise/depthwise: 2,304 1,806,336
MobilenetV1/Conv2d_5_pointwise/Conv2D: 65,536 51,380,224
MobilenetV1/Conv2d_6_depthwise/depthwise: 2,304 451,584
MobilenetV1/Conv2d_6_pointwise/Conv2D: 131,072 25,690,112
MobilenetV1/Conv2d_7_depthwise/depthwise: 4,608 903,168
MobilenetV1/Conv2d_7_pointwise/Conv2D: 262,144 51,380,224
MobilenetV1/Conv2d_8_depthwise/depthwise: 4,608 903,168
MobilenetV1/Conv2d_8_pointwise/Conv2D: 262,144 51,380,224
MobilenetV1/Conv2d_9_depthwise/depthwise: 4,608 903,168
MobilenetV1/Conv2d_9_pointwise/Conv2D: 262,144 51,380,224
MobilenetV1/Conv2d_10_depthwise/depthwise: 4,608 903,168
MobilenetV1/Conv2d_10_pointwise/Conv2D: 262,144 51,380,224
MobilenetV1/Conv2d_11_depthwise/depthwise: 4,608 903,168
MobilenetV1/Conv2d_11_pointwise/Conv2D: 262,144 51,380,224
MobilenetV1/Conv2d_12_depthwise/depthwise: 4,608 225,792
MobilenetV1/Conv2d_12_pointwise/Conv2D: 524,288 25,690,112
MobilenetV1/Conv2d_13_depthwise/depthwise: 9,216 451,584
MobilenetV1/Conv2d_13_pointwise/Conv2D: 1,048,576 51,380,224
--------------------------------------------------------------------------------
Total: 3,185,088 567,716,352
75% Mobilenet V1 (base) with input size 128x128:
See mobilenet_v1_075()
Layer params macs
--------------------------------------------------------------------------------
MobilenetV1/Conv2d_0/Conv2D: 648 2,654,208
MobilenetV1/Conv2d_1_depthwise/depthwise: 216 884,736
MobilenetV1/Conv2d_1_pointwise/Conv2D: 1,152 4,718,592
MobilenetV1/Conv2d_2_depthwise/depthwise: 432 442,368
MobilenetV1/Conv2d_2_pointwise/Conv2D: 4,608 4,718,592
MobilenetV1/Conv2d_3_depthwise/depthwise: 864 884,736
MobilenetV1/Conv2d_3_pointwise/Conv2D: 9,216 9,437,184
MobilenetV1/Conv2d_4_depthwise/depthwise: 864 221,184
MobilenetV1/Conv2d_4_pointwise/Conv2D: 18,432 4,718,592
MobilenetV1/Conv2d_5_depthwise/depthwise: 1,728 442,368
MobilenetV1/Conv2d_5_pointwise/Conv2D: 36,864 9,437,184
MobilenetV1/Conv2d_6_depthwise/depthwise: 1,728 110,592
MobilenetV1/Conv2d_6_pointwise/Conv2D: 73,728 4,718,592
MobilenetV1/Conv2d_7_depthwise/depthwise: 3,456 221,184
MobilenetV1/Conv2d_7_pointwise/Conv2D: 147,456 9,437,184
MobilenetV1/Conv2d_8_depthwise/depthwise: 3,456 221,184
MobilenetV1/Conv2d_8_pointwise/Conv2D: 147,456 9,437,184
MobilenetV1/Conv2d_9_depthwise/depthwise: 3,456 221,184
MobilenetV1/Conv2d_9_pointwise/Conv2D: 147,456 9,437,184
MobilenetV1/Conv2d_10_depthwise/depthwise: 3,456 221,184
MobilenetV1/Conv2d_10_pointwise/Conv2D: 147,456 9,437,184
MobilenetV1/Conv2d_11_depthwise/depthwise: 3,456 221,184
MobilenetV1/Conv2d_11_pointwise/Conv2D: 147,456 9,437,184
MobilenetV1/Conv2d_12_depthwise/depthwise: 3,456 55,296
MobilenetV1/Conv2d_12_pointwise/Conv2D: 294,912 4,718,592
MobilenetV1/Conv2d_13_depthwise/depthwise: 6,912 110,592
MobilenetV1/Conv2d_13_pointwise/Conv2D: 589,824 9,437,184
--------------------------------------------------------------------------------
Total: 1,800,144 106,002,432 # Tensorflow mandates these.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from collections import namedtuple
import functools
import tensorflow as tf
slim = tf.contrib.slim
# Conv and DepthSepConv namedtuple define layers of the MobileNet architecture
# Conv defines 3x3 convolution layers
# DepthSepConv defines 3x3 depthwise convolution followed by 1x1 convolution.
# stride is the stride of the convolution
# depth is the number of channels or filters in a layer
Conv = namedtuple('Conv', ['kernel', 'stride', 'depth'])
DepthSepConv = namedtuple('DepthSepConv', ['kernel', 'stride', 'depth'])
# _CONV_DEFS specifies the MobileNet body
_CONV_DEFS = [
Conv(kernel=[3, 3], stride=2, depth=32),
DepthSepConv(kernel=[3, 3], stride=1, depth=64),
DepthSepConv(kernel=[3, 3], stride=2, depth=128),
DepthSepConv(kernel=[3, 3], stride=1, depth=128),
DepthSepConv(kernel=[3, 3], stride=2, depth=256),
DepthSepConv(kernel=[3, 3], stride=1, depth=256),
DepthSepConv(kernel=[3, 3], stride=2, depth=512),
DepthSepConv(kernel=[3, 3], stride=1, depth=512),
DepthSepConv(kernel=[3, 3], stride=1, depth=512),
DepthSepConv(kernel=[3, 3], stride=1, depth=512),
DepthSepConv(kernel=[3, 3], stride=1, depth=512),
DepthSepConv(kernel=[3, 3], stride=1, depth=512),
DepthSepConv(kernel=[3, 3], stride=2, depth=1024),
DepthSepConv(kernel=[3, 3], stride=1, depth=1024)
]
def _fixed_padding(inputs, kernel_size, rate=1):
"""Pads the input along the spatial dimensions independently of input size.
Pads the input such that if it was used in a convolution with 'VALID' padding,
the output would have the same dimensions as if the unpadded input was used
in a convolution with 'SAME' padding.
Args:
inputs: A tensor of size [batch, height_in, width_in, channels].
kernel_size: The kernel to be used in the conv2d or max_pool2d operation.
rate: An integer, rate for atrous convolution.
Returns:
output: A tensor of size [batch, height_out, width_out, channels] with the
input, either intact (if kernel_size == 1) or padded (if kernel_size > 1).
"""
kernel_size_effective = [kernel_size[0] + (kernel_size[0] - 1) * (rate - 1),
kernel_size[0] + (kernel_size[0] - 1) * (rate - 1)]
pad_total = [kernel_size_effective[0] - 1, kernel_size_effective[1] - 1]
pad_beg = [pad_total[0] // 2, pad_total[1] // 2]
pad_end = [pad_total[0] - pad_beg[0], pad_total[1] - pad_beg[1]]
padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg[0], pad_end[0]],
[pad_beg[1], pad_end[1]], [0, 0]])
return padded_inputs
def mobilenet_v1_base(inputs,
final_endpoint='Conv2d_13_pointwise',
min_depth=8,
depth_multiplier=1.0,
conv_defs=None,
output_stride=None,
use_explicit_padding=False,
scope=None):
"""
Mobilenet v1.
Constructs a Mobilenet v1 network from inputs to the given final endpoint.
Args:
inputs: a tensor of shape [batch_size, height, width, channels].
final_endpoint: specifies the endpoint to construct the network up to. It
can be one of ['Conv2d_0', 'Conv2d_1_pointwise', 'Conv2d_2_pointwise',
'Conv2d_3_pointwise', 'Conv2d_4_pointwise', 'Conv2d_5'_pointwise,
'Conv2d_6_pointwise', 'Conv2d_7_pointwise', 'Conv2d_8_pointwise',
'Conv2d_9_pointwise', 'Conv2d_10_pointwise', 'Conv2d_11_pointwise',
'Conv2d_12_pointwise', 'Conv2d_13_pointwise'].
min_depth: Minimum depth value (number of channels) for all convolution ops.
Enforced when depth_multiplier < 1, and not an active constraint when
depth_multiplier >= 1.
depth_multiplier: Float multiplier for the depth (number of channels)
for all convolution ops. The value must be greater than zero. Typical
usage will be to set this value in (0, 1) to reduce the number of
parameters or computation cost of the model.
conv_defs: A list of ConvDef namedtuples specifying the net architecture.
output_stride: An integer that specifies the requested ratio of input to
output spatial resolution. If not None, then we invoke atrous convolution
if necessary to prevent the network from reducing the spatial resolution
of the activation maps. Allowed values are 8 (accurate fully convolutional
mode), 16 (fast fully convolutional mode), 32 (classification mode).
use_explicit_padding: Use 'VALID' padding for convolutions, but prepad
inputs so that the output dimensions are the same as if 'SAME' padding
were used.
scope: Optional variable_scope.
Returns:
tensor_out: output tensor corresponding to the final_endpoint.
end_points: a set of activations for external use, for example summaries or
losses.
Raises:
ValueError: if final_endpoint is not set to one of the predefined values,
or depth_multiplier <= 0, or the target output_stride is not
allowed.
"""
depth = lambda d: max(int(d * depth_multiplier), min_depth)
end_points = {}
# Used to find thinned depths for each layer.
if depth_multiplier <= 0:
raise ValueError('depth_multiplier is not greater than zero.')
if conv_defs is None:
conv_defs = _CONV_DEFS
if output_stride is not None and output_stride not in [8, 16, 32]:
raise ValueError('Only allowed output_stride values are 8, 16, 32.')
padding = 'SAME'
if use_explicit_padding:
padding = 'VALID'
with tf.variable_scope(scope, 'MobilenetV1', [inputs]):
with slim.arg_scope([slim.conv2d, slim.separable_conv2d], padding=padding):
# The current_stride variable keeps track of the output stride of the
# activations, i.e., the running product of convolution strides up to the
# current network layer. This allows us to invoke atrous convolution
# whenever applying the next convolution would result in the activations
# having output stride larger than the target output_stride.
current_stride = 1
# The atrous convolution rate parameter.
rate = 1
net = inputs
for i, conv_def in enumerate(conv_defs):
end_point_base = 'Conv2d_%d' % i
if output_stride is not None and current_stride == output_stride:
# If we have reached the target output_stride, then we need to employ
# atrous convolution with stride=1 and multiply the atrous rate by the
# current unit's stride for use in subsequent layers.
layer_stride = 1
layer_rate = rate
rate *= conv_def.stride
else:
layer_stride = conv_def.stride
layer_rate = 1
current_stride *= conv_def.stride
if isinstance(conv_def, Conv):
end_point = end_point_base
if use_explicit_padding:
net = _fixed_padding(net, conv_def.kernel)
net = slim.conv2d(net, depth(conv_def.depth), conv_def.kernel,
stride=conv_def.stride,
normalizer_fn=slim.batch_norm,
scope=end_point)
end_points[end_point] = net
if end_point == final_endpoint:
return net, end_points
elif isinstance(conv_def, DepthSepConv):
end_point = end_point_base + '_depthwise'
# By passing filters=None
# separable_conv2d produces only a depthwise convolution layer
if use_explicit_padding:
net = _fixed_padding(net, conv_def.kernel, layer_rate)
net = slim.separable_conv2d(net, None, conv_def.kernel,
depth_multiplier=1,
stride=layer_stride,
rate=layer_rate,
normalizer_fn=slim.batch_norm,
scope=end_point)
end_points[end_point] = net
if end_point == final_endpoint:
return net, end_points
end_point = end_point_base + '_pointwise'
net = slim.conv2d(net, depth(conv_def.depth), [1, 1],
stride=1,
normalizer_fn=slim.batch_norm,
scope=end_point)
end_points[end_point] = net
if end_point == final_endpoint:
return net, end_points
else:
raise ValueError('Unknown convolution type %s for layer %d'
% (conv_def.ltype, i))
raise ValueError('Unknown final endpoint %s' % final_endpoint)
def mobilenet_v1(inputs,
num_classes=1000,
dropout_keep_prob=0.999,
is_training=True,
min_depth=8,
depth_multiplier=1.0,
conv_defs=None,
prediction_fn=tf.contrib.layers.softmax,
spatial_squeeze=True,
reuse=None,
scope='MobilenetV1',
global_pool=False):
"""Mobilenet v1 model for classification.
Args:
inputs: a tensor of shape [batch_size, height, width, channels].
num_classes: number of predicted classes. If 0 or None, the logits layer
is omitted and the input features to the logits layer (before dropout)
are returned instead.
dropout_keep_prob: the percentage of activation values that are retained.
is_training: whether is training or not.
min_depth: Minimum depth value (number of channels) for all convolution ops.
Enforced when depth_multiplier < 1, and not an active constraint when
depth_multiplier >= 1.
depth_multiplier: Float multiplier for the depth (number of channels)
for all convolution ops. The value must be greater than zero. Typical
usage will be to set this value in (0, 1) to reduce the number of
parameters or computation cost of the model.
conv_defs: A list of ConvDef namedtuples specifying the net architecture.
prediction_fn: a function to get predictions out of logits.
spatial_squeeze: if True, logits is of shape is [B, C], if false logits is
of shape [B, 1, 1, C], where B is batch_size and C is number of classes.
reuse: whether or not the network and its variables should be reused. To be
able to reuse 'scope' must be given.
scope: Optional variable_scope.
global_pool: Optional boolean flag to control the avgpooling before the
logits layer. If false or unset, pooling is done with a fixed window
that reduces default-sized inputs to 1x1, while larger inputs lead to
larger outputs. If true, any input size is pooled down to 1x1.
Returns:
net: a 2D Tensor with the logits (pre-softmax activations) if num_classes
is a non-zero integer, or the non-dropped-out input to the logits layer
if num_classes is 0 or None.
end_points: a dictionary from components of the network to the corresponding
activation.
Raises:
ValueError: Input rank is invalid.
"""
input_shape = inputs.get_shape().as_list()
if len(input_shape) != 4:
raise ValueError('Invalid input tensor rank, expected 4, was: %d' %
len(input_shape))
with tf.variable_scope(scope, 'MobilenetV1', [inputs], reuse=reuse) as scope:
with slim.arg_scope([slim.batch_norm, slim.dropout],
is_training=is_training):
net, end_points = mobilenet_v1_base(inputs, scope=scope,
min_depth=min_depth,
depth_multiplier=depth_multiplier,
conv_defs=conv_defs)
with tf.variable_scope('Logits'):
if global_pool:
# Global average pooling.
net = tf.reduce_mean(net, [1, 2], keep_dims=True, name='global_pool')
end_points['global_pool'] = net
else:
# Pooling with a fixed kernel size.
kernel_size = _reduced_kernel_size_for_small_input(net, [7, 7])
net = slim.avg_pool2d(net, kernel_size, padding='VALID',
scope='AvgPool_1a')
end_points['AvgPool_1a'] = net
if not num_classes:
return net, end_points
# 1 x 1 x 1024
net = slim.dropout(net, keep_prob=dropout_keep_prob, scope='Dropout_1b')
logits = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, scope='Conv2d_1c_1x1')
if spatial_squeeze:
logits = tf.squeeze(logits, [1, 2], name='SpatialSqueeze')
end_points['Logits'] = logits
if prediction_fn:
end_points['Predictions'] = prediction_fn(logits, scope='Predictions')
return logits, end_points
mobilenet_v1.default_image_size = 224
def wrapped_partial(func, *args, **kwargs):
partial_func = functools.partial(func, *args, **kwargs)
functools.update_wrapper(partial_func, func)
return partial_func
mobilenet_v1_075 = wrapped_partial(mobilenet_v1, depth_multiplier=0.75)
mobilenet_v1_050 = wrapped_partial(mobilenet_v1, depth_multiplier=0.50)
mobilenet_v1_025 = wrapped_partial(mobilenet_v1, depth_multiplier=0.25)
def _reduced_kernel_size_for_small_input(input_tensor, kernel_size):
"""Define kernel size which is automatically reduced for small input.
If the shape of the input images is unknown at graph construction time this
function assumes that the input images are large enough.
Args:
input_tensor: input tensor of size [batch_size, height, width, channels].
kernel_size: desired kernel size of length 2: [kernel_height, kernel_width]
Returns:
a tensor with the kernel size.
"""
shape = input_tensor.get_shape().as_list()
if shape[1] is None or shape[2] is None:
kernel_size_out = kernel_size
else:
kernel_size_out = [min(shape[1], kernel_size[0]),
min(shape[2], kernel_size[1])]
return kernel_size_out
def mobilenet_v1_arg_scope(
is_training=True,
weight_decay=0.00004,
stddev=0.09,
regularize_depthwise=False,
batch_norm_decay=0.9997,
batch_norm_epsilon=0.001,
batch_norm_updates_collections=tf.GraphKeys.UPDATE_OPS):
"""Defines the default MobilenetV1 arg scope.
Args:
is_training: Whether or not we're training the model. If this is set to
None, the parameter is not added to the batch_norm arg_scope.
weight_decay: The weight decay to use for regularizing the model.
stddev: The standard deviation of the trunctated normal weight initializer.
regularize_depthwise: Whether or not apply regularization on depthwise.
batch_norm_decay: Decay for batch norm moving average.
batch_norm_epsilon: Small float added to variance to avoid dividing by zero
in batch norm.
batch_norm_updates_collections: Collection for the update ops for
batch norm.
Returns:
An `arg_scope` to use for the mobilenet v1 model.
"""
batch_norm_params = {
'center': True,
'scale': True,
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'updates_collections': batch_norm_updates_collections,
}
if is_training is not None:
batch_norm_params['is_training'] = is_training
# Set weight_decay for weights in Conv and DepthSepConv layers.
weights_init = tf.truncated_normal_initializer(stddev=stddev)
regularizer = tf.contrib.layers.l2_regularizer(weight_decay)
if regularize_depthwise:
depthwise_regularizer = regularizer
else:
depthwise_regularizer = None
with slim.arg_scope([slim.conv2d, slim.separable_conv2d],
weights_initializer=weights_init,
activation_fn=tf.nn.relu6, normalizer_fn=slim.batch_norm):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
with slim.arg_scope([slim.conv2d], weights_regularizer=regularizer):
with slim.arg_scope([slim.separable_conv2d],
weights_regularizer=depthwise_regularizer) as sc:
return sc> [MobileNets 的预训练模型](https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md#pre-trained-models)
2.2 MobileNets Pytorch 实现
import time
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
import torchvision.models as models
from torch.autograd import Variable
class MobileNet(nn.Module):
def __init__(self):
super(MobileNet, self).__init__()
def conv_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)
def conv_dw(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True),
)
self.model = nn.Sequential(
conv_bn( 3, 32, 2),
conv_dw( 32, 64, 1),
conv_dw( 64, 128, 2),
conv_dw(128, 128, 1),
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
nn.AvgPool2d(7),
)
self.fc = nn.Linear(1024, 1000)
def forward(self, x):
x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
def speed(model, name):
t0 = time.time()
input = torch.rand(1,3,224,224).cuda()
input = Variable(input, volatile = True)
t1 = time.time()
model(input)
t2 = time.time()
model(input)
t3 = time.time()
print('%10s : %f' % (name, t3 - t2))
if __name__ == '__main__':
#cudnn.benchmark = True # This will make network slow ??
mobilenet = MobileNet().cuda()
speed(mobilenet, 'mobilenet')3. Experiments
3.1 模型选择

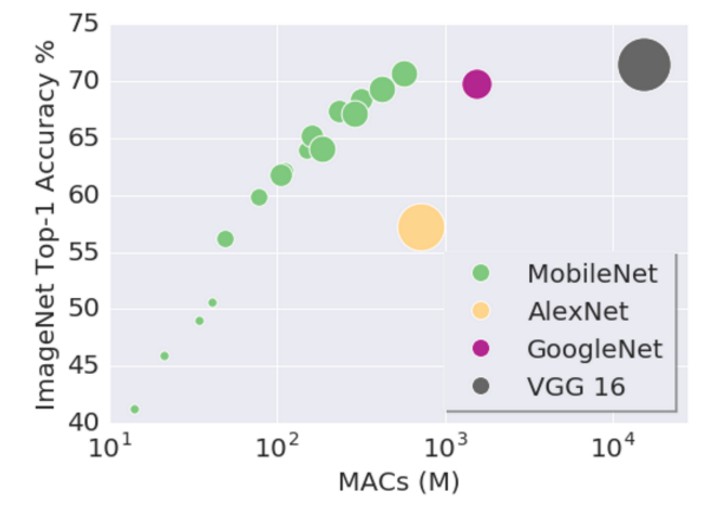
在 ImageNet 上,精度牺牲了 1%,但参数量和计算量明显减少.
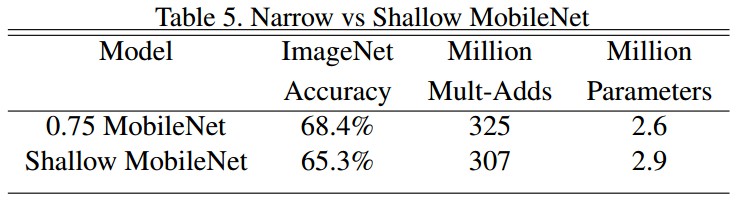
相似的计算量和参数量时,使 MobileNets 变瘦(thin),比模型浅(shallower) 的精度高了 3%.
3.2 在精细物体识别上的结果
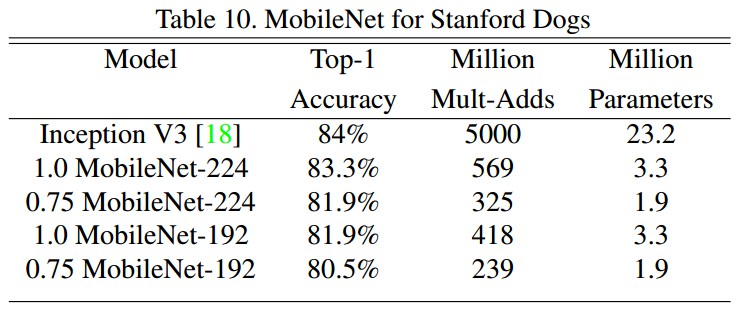
3.3 大尺度地理定位
PlaNet 的任务场景,判断照片拍摄地的分类问题.

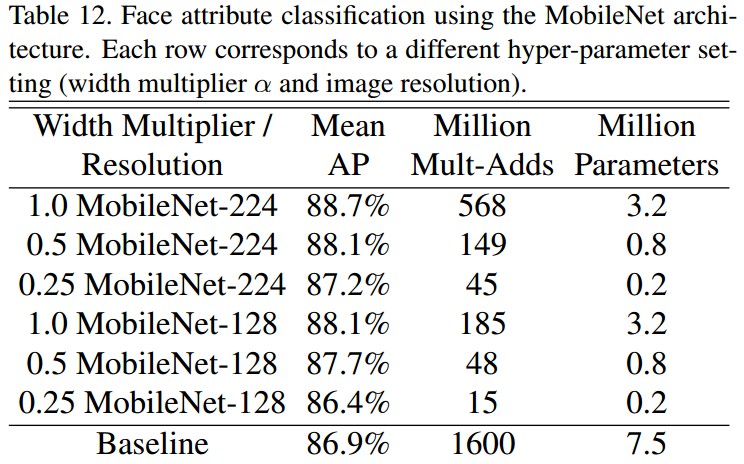
3.4 人脸属性分类
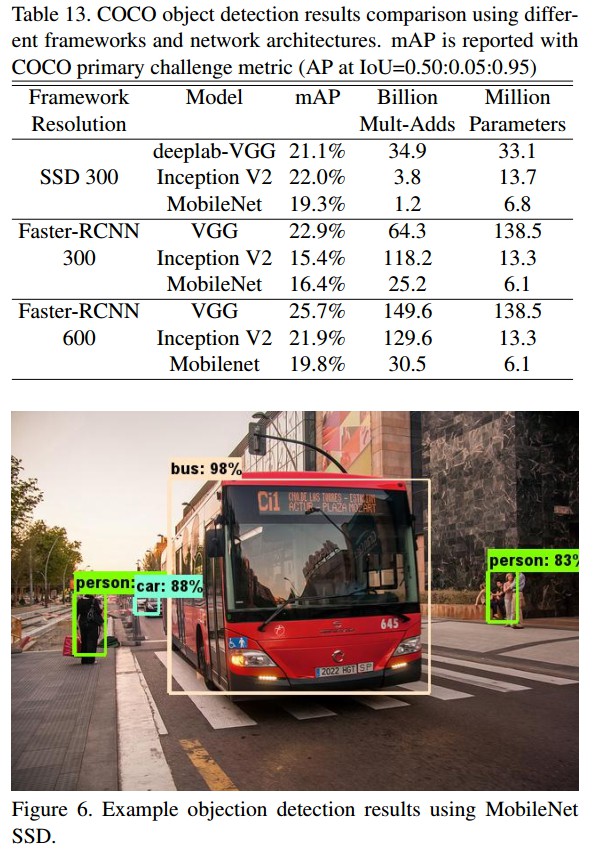
3.5 目标检测
3.6 人脸识别
