论文:SqueezeNet: AlexNet-level Accuracy With 50x Fewer Parameters And <0.5 MB Model Size - 2016
作者:Forrest N. Iandola, Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, Kurt Keutzer
团队:DeepScale,Standford University
同等精度下,参数较少的轻量型 CNN 结构优势有:
- [1] - 更有效的分布式训练
分布式训练时,服务器间的通信效率是重要的因素. 轻量型小模型在训练时需要较少的服务器间的信息通信,更易于网络训练. - [2] - 更少的带宽,更易于从云端导入模型到客户端,如自动驾驶汽车.
如,AlexNet 模型大小为 240MB,需要从服务器端到客户端的通信. - [3] - 更灵活的平台部署,如 FPGAs 等其它内存有限的硬件平台.
1. SqueezeNet
1.1 网络结构设计策略
保持模型精度的同时,CNN 结构的设计策略有:
[1] - Strategy 1:采用 1x1 filters 卷积代替 3x3 filters 卷积
1x1 卷积的参数量为 3x3 卷积的 1/9.
[2] - Strategy 2:减少 3x3 filters 卷积的输入通道数.
如果卷积层完全采用 3x3 卷积,则该卷积层的总参数量为:(输入通道数) X (filters 数) X (3x3).
因此,减少 CNN 的参数量,不仅可以采用减少 3x3 filters 卷积的数量(Strategy 1)的方法,还可以减少 3x3 卷积的输入通道数.
这里采用 squeeze layers 实现减少 3x3 卷积的输入通道数的目的.
[3] - Strategy 3:延迟网络的降采样操作,以使得卷积层具有更大的激活图.
卷积网络中,每个卷积层输出激活图(activation map),激活图空间分辨率至少为 1x1,往往大于 1x1.
激活图的 height 和 width 主要被两个因素影响:(1) 输入数据的尺寸,如 256x256 图片;(2) CNN 网络中的降采样层的作用.
Strategy 1 和 Strategy 2 是在保持精度的前提下,减少 CNN 网络的参数量.
Strategy 3 是在有限的参数量的前提下,保持最大的精度.
1.2 SqueezeNet 的 Fire 模块.
如图: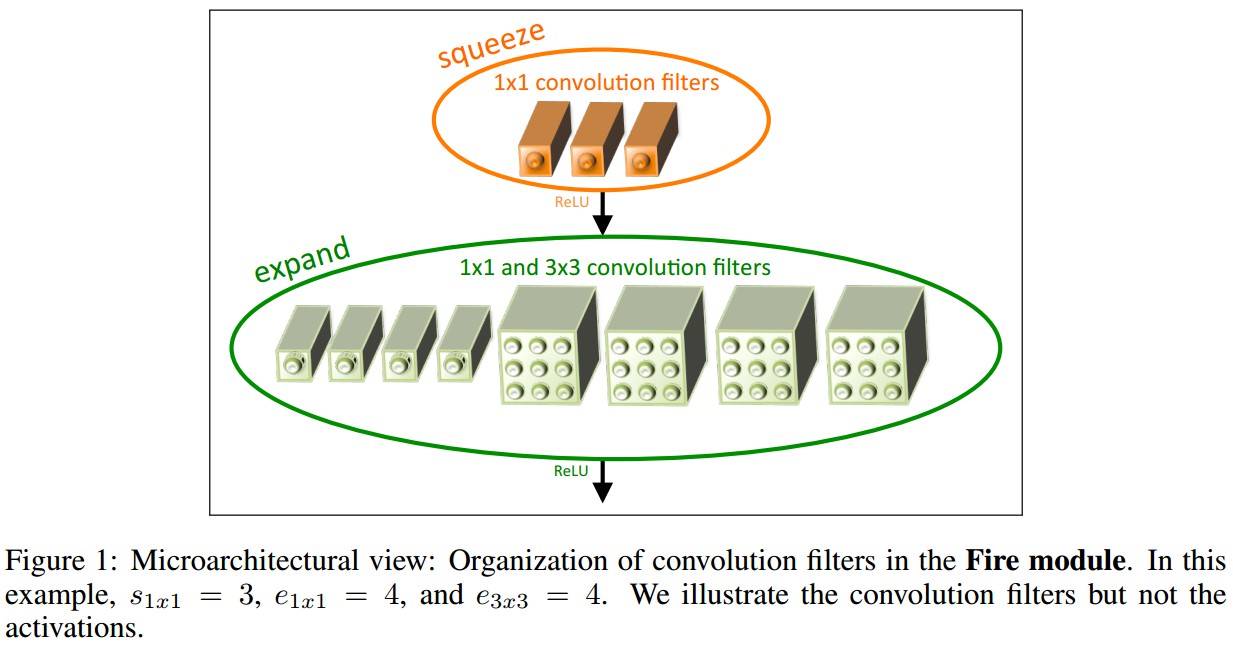
一个 Fire 模块主要组成为:
squeeze 卷积层:只采用 1x1 filter 卷积;Strategy 1.
expand 层:混合采用 1x1 filter 卷积和 3x3 filter 卷积.
Fire 模块的三个可调维度(超参数):
${s_{1x1}}$ - squeeze 层的 filters 数(都是 1x1 filters);
${e_{1x1}}$ - expand 层的 1x1 卷积 filters 数;
${e_{3x3}}$ - expand 层的 3x3 卷积 filters 数.
Fire 模块使用时,设定 ${s_{1x1}}$ 小于 $({e_{1x1} + e_{3x3}})$,使得 squeeze 层有利于减少 3x3 filters 卷积的输入通道数.
1.3 SqueezeNet 网络结构
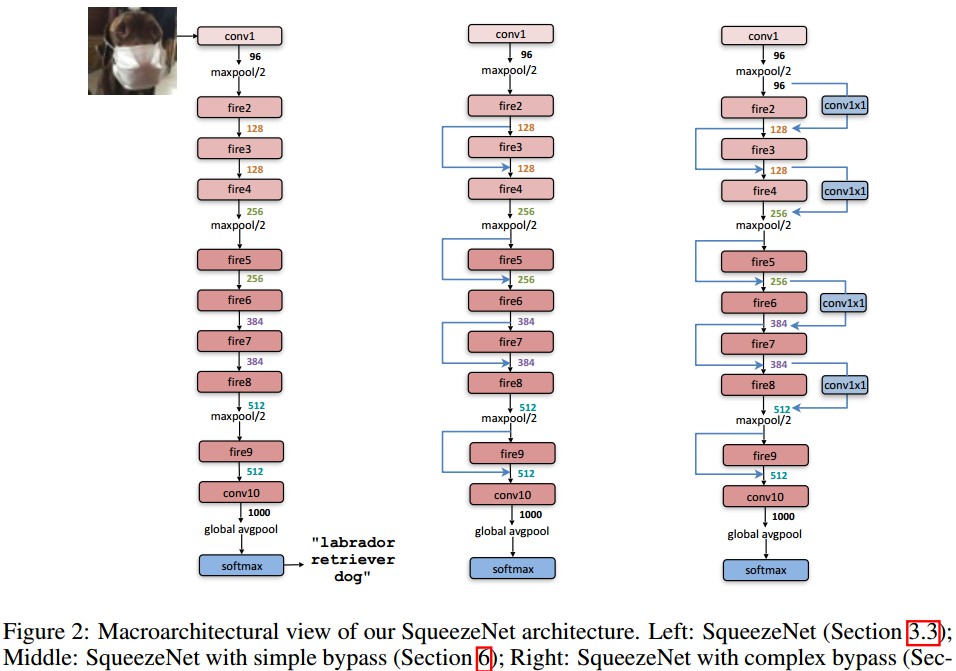
如图 Figure 2.
SqueezeNet 首先是一个卷积层(conv1),然后接 8 个 Fire 模块(fire2-9),最后接一个卷积层(conv10).
从网络开始到结束,逐渐的增加每个 fire 模块的 filters 数.
SqueezeNet 在 conv1,fire4,fire8 和 conv10 网络层后,采用步长为 3 的 max-pooling 操作.(Strategy3).
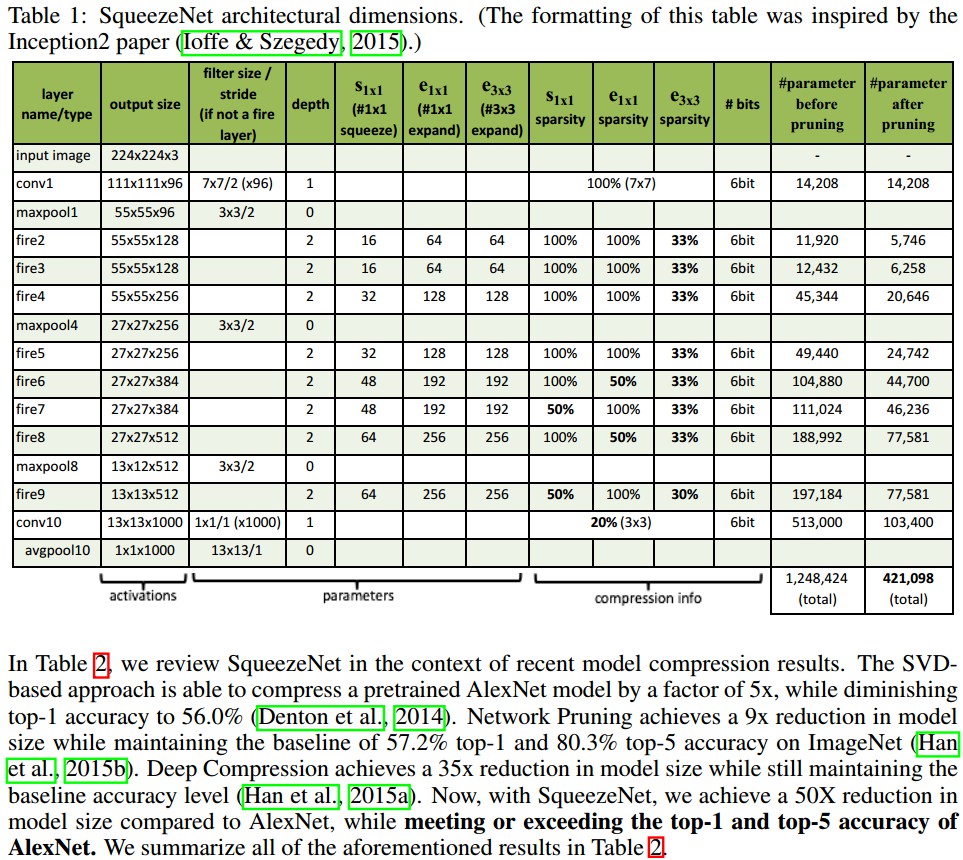
参数量计算:
- [1] - conv1: (7x7x3 + 1)x96=14208
- [2] - fire2: (1x1x96 + 1)x16 + (1x1x16 + 1)x64 + (3x3x16 + 1)x64 = (1552 + 1088 + 9280) = 11920
- [3] - fire3: (1x1x128 + 1)x16 + (1x1x16 + 1)x64 + (3x3x16 + 1)x64 = (2064 + 1088 + 9280) = 12432
- [4] - fire4: (1x1x128 + 1)x 32 + (1x1x32 + 1)x128 + (3x3x32 + 1)x128 = (4128 + 4224 + 36992) = 45344
......
squeeze 层采用 1x1 卷积极大的减少了参数量,同时具有降维作用;但其代价是输出的特征图通道数(维度)大大减少. 其后的 expand 层采用 1x1 和 3x3 两种尺寸的卷积进行特征提取,链接两种尺寸的卷积后,特征图的维度被升维. 不过 3x3 卷积的参数超过 1x1 卷积的参数量,不利于模型参数的减少. 对此,SqueezeNet 还对 3x3 卷积进行剪枝操作,以减少参数量.
1.4 SqueezeNet 的其它细节
- [1] - 为确保 1x1 卷积和 3x3 卷积的输出激活图具有相同的 height 和 width 尺寸,SqueezeNet 在 expand 模块中,对 3x3 卷积的输入数据,添加了 1 像素的边界补零(zero-padding).
- [2] - squeeze 和 expand 层均采用 ReLU 激活函数.
- [3] - fire9 模块后采用 Dropout,比例为 0.5.
- [4] - SqueezeNet 没有全连接层,参考了 NIN 网络的思想.
- [5] - SqueezeNet 训练时,初始化学习率为 0.04,然后线性递减.
- [6] - 原生 Caffe 不支持包含多种不同尺寸的 filter 卷积层,因此,采用两个单独卷积层(1x1 卷积和 3x3 卷积) 来实现 expand 层. 然后,在通道维度将两个单独卷积层的输出进行链接. 从数值上等价于单个网络层,但包含了两种不同的 1x1 和 3x3 卷积操作.
2. SqueezeNet 分析
2.1 SqueezeNet 与模型压缩方法的对比
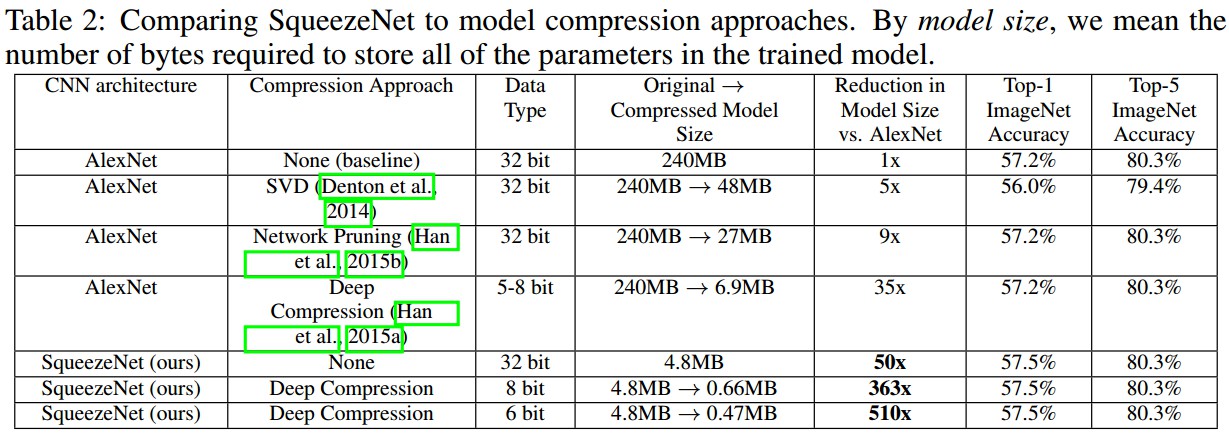
SqueezeNet 模型确实适合于模型压缩. 对比 AlexNet 模型大小可以减少 510x.
2.2 CNN 微结构的元参数(metaparameters)
SqueezeNet 中,每个 Fire 模块有三个超参数:${s_{1x1}}$,${e_{1x1}}$ 和 ${e_{3x3}}$.
SqueezeNet 网络中共有 8 个 Fire 模块,24 维超参数.
为了扩展类似于 SqueezeNet 的网络结构的设计空间,定义了更高层的元参数,来控制 CNN 中的所有 Fire 模块的维度,即:
- ${base_e}$ - CNN 中第一个 Fire 模块的 expand filters 的数量;
- ${freq}$ - Fire 模块的数量;
- ${incr_e}$ - 每 ${freq}$ 个 Fire 模块之后增加的 expand filters 的数量;
- ${e_i}$ - 第 i 个 Fire 模块中 expand filters 的数量;即 ${ e_i = base_e + (incr_e * |\frac{i}{freq}|) }$.
- ${pct_{3x3}}$ - Fire 模块的 expand 层中,采用了 1x1 和 3x3 两种尺寸的卷积,${pct_{3x3}}$ 定义了 expand 层中 3x3 卷积的比例. 有:${e_i = e_{i, 1x1} + e_{i, 3x3}}$, ${e_{i, 3x3} = e_i * pct_{3x3}}$,${e_{i, 1x1} = e_i * (1-pct_{3x3})}$
- SR(Squeeze Ratio) - squeeze 层中 filters 个数与 Fire 模块中所有 filters 总个数的比例. 则:${s_{i, 1x1} = SR * e_i = SR * (e_{i,1x1} + e_{i, 3x3}) }$

2.3 SqueezeNet 的 Bypass 连接

3. SqueezeNet 网络结构可视化
Caffe 中的定义:SqueezeNet_v1.0/deploy.prototxt
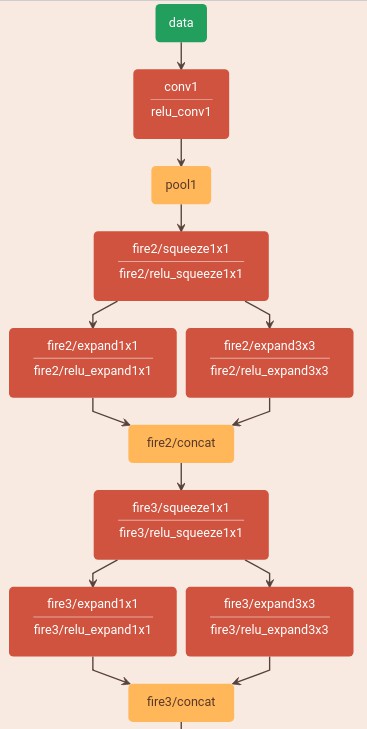
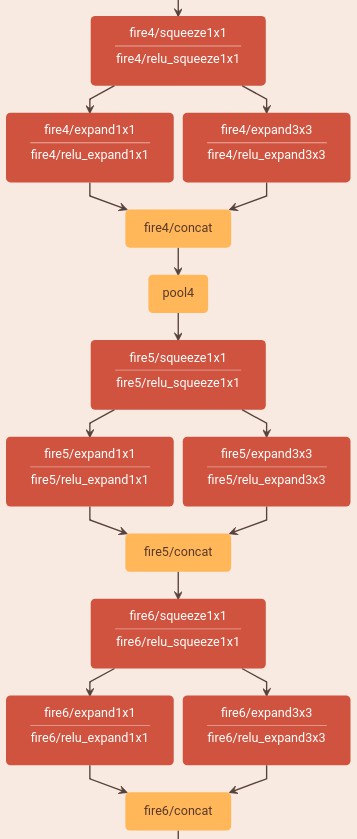
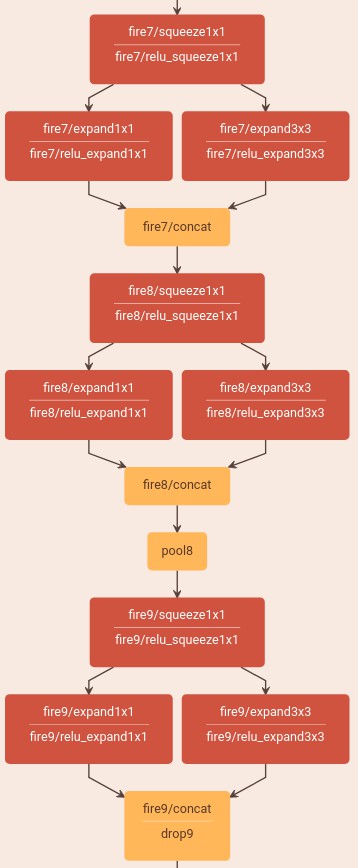

4. SqueezeNet 的 Pytorch 中的定义
Pytorch 中的定义:squeezenet.py
import math
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.utils.model_zoo as model_zoo
__all__ = ['SqueezeNet', 'squeezenet1_0', 'squeezenet1_1']
model_urls = {
'squeezenet1_0': 'https://download.pytorch.org/models/squeezenet1_0-a815701f.pth',
'squeezenet1_1': 'https://download.pytorch.org/models/squeezenet1_1-f364aa15.pth',
}
class Fire(nn.Module):
def __init__(self, inplanes, squeeze_planes,
expand1x1_planes, expand3x3_planes):
super(Fire, self).__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes,
kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes,
kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.squeeze_activation(self.squeeze(x))
return torch.cat([
self.expand1x1_activation(self.expand1x1(x)),
self.expand3x3_activation(self.expand3x3(x))
], 1)
class SqueezeNet(nn.Module):
def __init__(self, version=1.0, num_classes=1000):
super(SqueezeNet, self).__init__()
if version not in [1.0, 1.1]:
raise ValueError("Unsupported SqueezeNet version {version}:"
"1.0 or 1.1 expected".format(version=version))
self.num_classes = num_classes
if version == 1.0:
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(512, 64, 256, 256),
)
else:
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(64, 16, 64, 64),
Fire(128, 16, 64, 64),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(128, 32, 128, 128),
Fire(256, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
Fire(512, 64, 256, 256),
)
# Final convolution is initialized differently form the rest
final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
final_conv,
nn.ReLU(inplace=True),
nn.AvgPool2d(13, stride=1)
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m is final_conv:
init.normal_(m.weight, mean=0.0, std=0.01)
else:
init.kaiming_uniform_(m.weight)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x.view(x.size(0), self.num_classes)
def squeezenet1_0(pretrained=False, **kwargs):
"""
SqueezeNet 模型结构,From:论文 SqueezeNet: AlexNet-level
accuracy with 50x fewer parameters and <0.5MB model size
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SqueezeNet(version=1.0, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['squeezenet1_0']))
return model
def squeezenet1_1(pretrained=False, **kwargs):
"""
SqueezeNet 1.1 模型结构,
From:https://github.com/DeepScale/SqueezeNet/tree/master/SqueezeNet_v1.1.
SqueezeNet 1.1 比 SqueezeNet1.0 计算量少了 2.4 倍,
稍微少了一部分参数量,且不牺牲精度.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = SqueezeNet(version=1.1, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['squeezenet1_1']))
return model