Kaggle Carvana Image Masking Challenge
TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation - 2018
TernausNet - Github 项目
1. TernausNet 论文细节
TernausNet,使用预训练权重改进 U-Net,提升图像分割的效果.
像素级的语义分割,经典网络 U-Net,由编码encoders和解码decoders组成,是医学图像,卫星图像的分割常用的网络结构. 通常情况下,神经网络的权重初始化是采用在 ImageNet 上预训练的权重参数进行的,相比于重新训练,在小数据集上的效果更佳. TernausNet 阐述了如何采用预训练的编码器encoders 来改进 U-Net,以提升图像分割精度. 对比了三种权重初始化方案,
- LeCun uniform
- VGG11 的编码器权重.
- 完全在 Carvana 数据集训练的网络
原始的 U-Net 结构采用跳跃连接(skip connections) 来整合 low-level feature maps 和 higher-level feature maps,以进行精确的像素级定位. 在上采样部分,大量的特征通道向更高的分辨率层传播上下文信息. U-Net 类型的网络结构在二值图像分割应用中,如卫星图像分析,医学图像分析等,取得了很好的成绩.
1.1. 网络结构
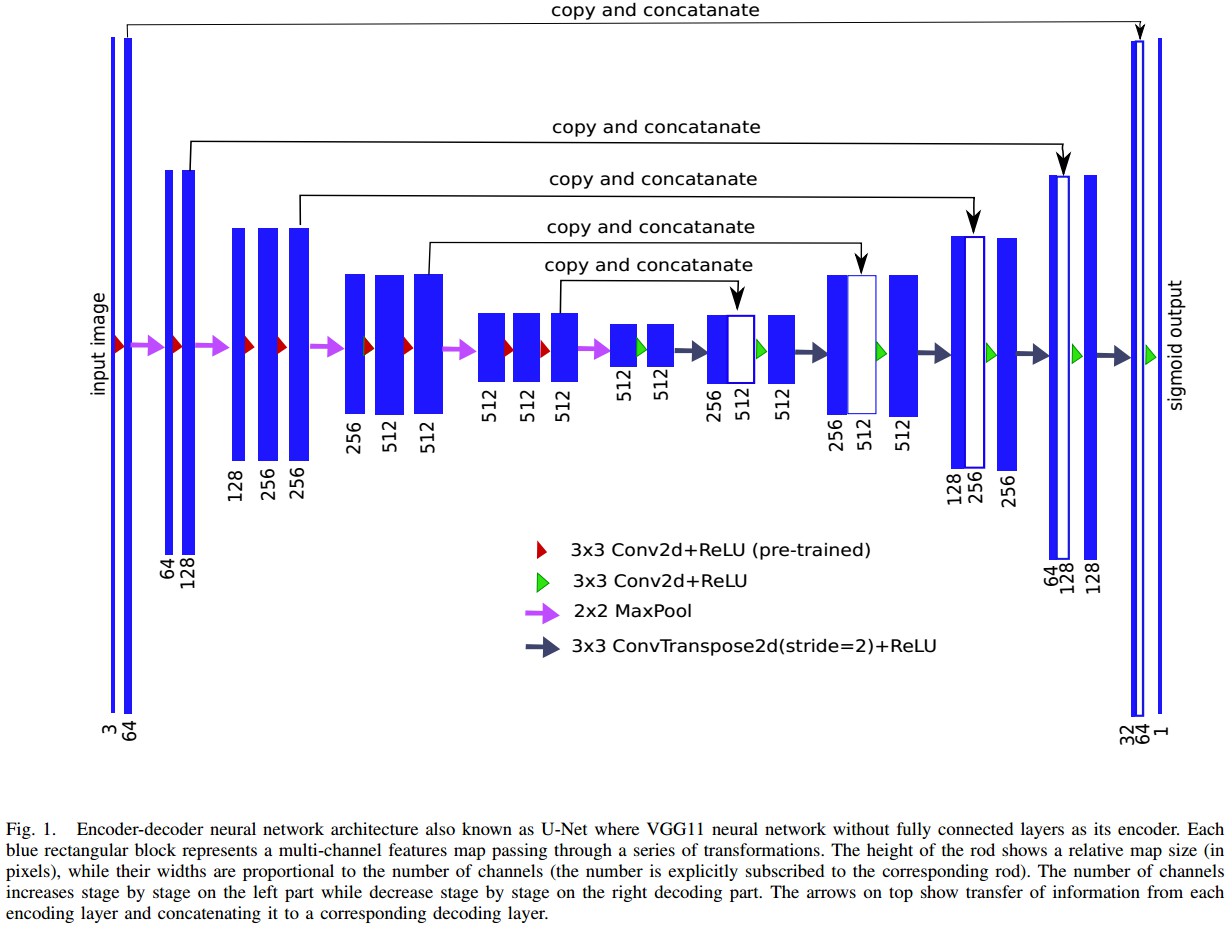 Fig1. U-Net Encoder-decoder 网络结构.
Fig1. U-Net Encoder-decoder 网络结构.
其中,VGG11 不包含全连接层的网络作为其编码器encoder. 每个蓝色方框块表示多通道 feature map 的传递变换. 杆(rod) 的高度表示相对 map 尺寸(像素为单位),杆的宽度正比于通道数量. 左边编码器部分中,通道数量越来越多;右边解码器部分,通道数量逐渐减少. 箭头部分表示从每个编码器层的信息传递,并链接到对应的解码器层.
U-Net 能够在相对小的训练数据集上有效学习. 通常情况,U-Net 采用随机初始化权重重新开始训练. 众所周知,深度网络的训练需要相对较大的图片数据集进行训练,以避免过拟合. 在 ImageNet 上预训练的网络模型被普遍用于很多网络权重的初始化.
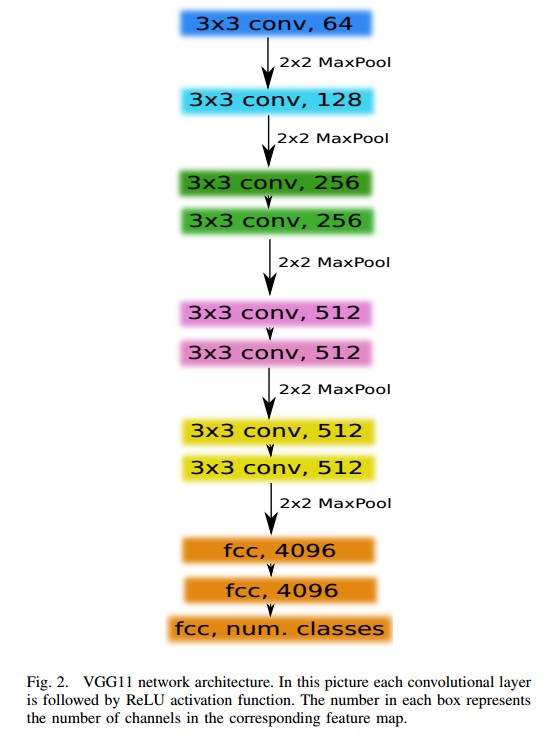
这里,U-Net 网络中的编码器采用相对简单的 VGG 网络的 CNN,包含 11 个序列化层,即 VGG11,如 Fig2. VGG11 包含 7 个卷积层,每个卷积层后接 ReLU 激活层,还有 5 个 max pooling 层,其每次将 feature map 尺寸降低为 1/2. 所有的卷积层采用 3x3 的 kernels. 如 Fig 1. 编码器的构建,移除了所有的全连接层,并替换为 512 通道的卷积层.
 解码器的构建,采用 transposed 卷积层,将 feature map 的尺寸翻倍,同时将通道数量减半. 另外,transposed 卷积层与编码器中对应的输出结构连接一起. 得到的 feature map 进行卷积操作,以保持通道数量与编码器部分的对称性. 上采样程序重复 5 次,对应与编码器中的 5 次 max pooling. 一般来说,全卷积层可以采用任何尺寸的图片作为输入,但是由于这里有 5 个 max pooling 层,每个 max pooling 对图像下采样一次,只有当图片尺寸能够整除 32(2x2x2x2x2) 时,才可以作为当前网络的输入.
解码器的构建,采用 transposed 卷积层,将 feature map 的尺寸翻倍,同时将通道数量减半. 另外,transposed 卷积层与编码器中对应的输出结构连接一起. 得到的 feature map 进行卷积操作,以保持通道数量与编码器部分的对称性. 上采样程序重复 5 次,对应与编码器中的 5 次 max pooling. 一般来说,全卷积层可以采用任何尺寸的图片作为输入,但是由于这里有 5 个 max pooling 层,每个 max pooling 对图像下采样一次,只有当图片尺寸能够整除 32(2x2x2x2x2) 时,才可以作为当前网络的输入.
1.2. Inria Aerial Image Labeling Dataset 结果
Inria Aerial Image Labeling Dataset 数据集包含 180 张欧洲和美国的城市住区的航空图像,并被标注为建筑(building) 和非建筑(not building) 两类. 每张图片是 5000x5000 分辨率的 RGB 图像,每个像素对应于地球表面的 30x30 平方厘米. 30 张作为验证集,150 张作为训练集,训练了 100 个 epochs. 随机裁剪为 768x768 作为训练输入,中心裁剪 1440x1440 用于验证输入. 采用 Jaccard index(IoU,Intersection Over Union) 作为评估度量. 两个数据集 A 和 B 的相似性度量的 IoU 定义如下:
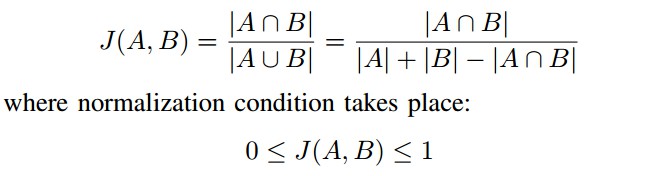 图像像素的表示形式,
图像像素的表示形式,
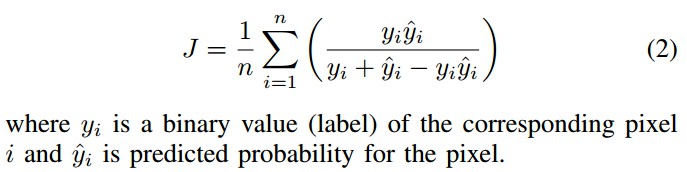 由于将图像语义分割任务作为像素分类问题,也采用了二值分类任务的 loss 函数 - 二值交叉熵:
由于将图像语义分割任务作为像素分类问题,也采用了二值分类任务的 loss 函数 - 二值交叉熵:
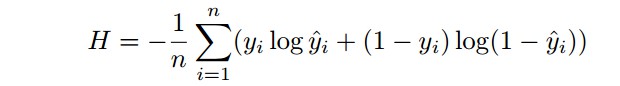 最终的 loss 函数为:
最终的 loss 函数为:
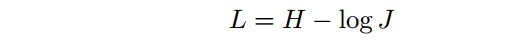 同时最大化像素正确预测的概率和预测的 mask 和 groundtruth mask 间的 IoU. U-Net 的网络输出是每个像素的概率值. 为了得到二值像素值,采用 threshold=0.3 进行二值化. 根据不同数据集进行选择该阈值. 所有小于阈值的像素设为 0,大于阈值的像素设为 1. 然后每个像素值乘以 255,即可得到最终的黑白预测mask. 不同权重初始化网络的结果:
同时最大化像素正确预测的概率和预测的 mask 和 groundtruth mask 间的 IoU. U-Net 的网络输出是每个像素的概率值. 为了得到二值像素值,采用 threshold=0.3 进行二值化. 根据不同数据集进行选择该阈值. 所有小于阈值的像素设为 0,大于阈值的像素设为 1. 然后每个像素值乘以 255,即可得到最终的黑白预测mask. 不同权重初始化网络的结果:

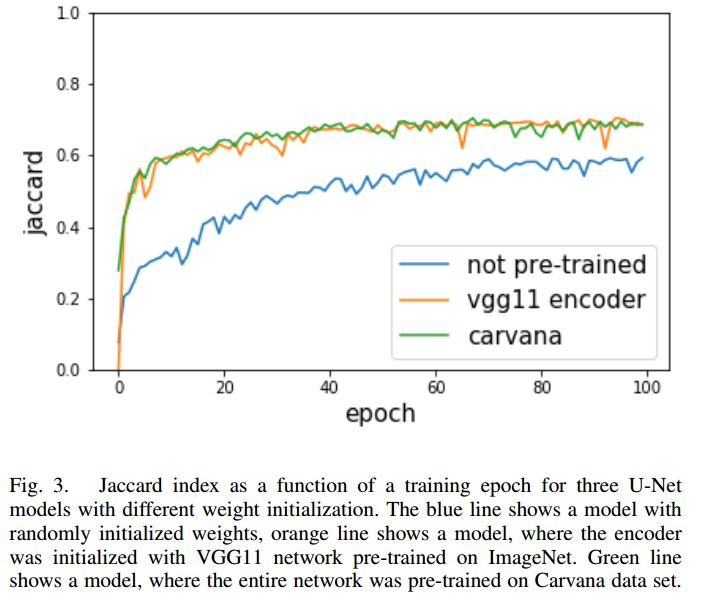

Kaggle车辆边界识别第一名解决方案:使用预训练权重轻松改进U-Net
Kaggle Carvana 图像分割比赛冠军模型 TernausNet 解读
2. TernausNet - Github 实现
- 训练的模型 - TernausNet.pt
- U-Net 模型定义:
from torch import nn
from torch.nn import functional as F
import torch
from torchvision import models
import torchvision
def conv3x3(in_, out):
return nn.Conv2d(in_, out, 3, padding=1)
class ConvRelu(nn.Module):
def __init__(self, in_, out):
super().__init__()
self.conv = conv3x3(in_, out)
self.activation = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.activation(x)
return x
class DecoderBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.block = nn.Sequential(
ConvRelu(in_channels, middle_channels),
nn.ConvTranspose2d(middle_channels, out_channels, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.block(x)
class UNet11(nn.Module):
def __init__(self, num_filters=32, pretrained=False):
"""
:param num_classes:
:param num_filters:
:param pretrained:
False - no pre-trained network is used
True - encoder is pre-trained with VGG11
"""
super().__init__()
self.pool = nn.MaxPool2d(2, 2)
self.encoder = models.vgg11(pretrained=pretrained).features
self.relu = self.encoder[1]
self.conv1 = self.encoder[0]
self.conv2 = self.encoder[3]
self.conv3s = self.encoder[6]
self.conv3 = self.encoder[8]
self.conv4s = self.encoder[11]
self.conv4 = self.encoder[13]
self.conv5s = self.encoder[16]
self.conv5 = self.encoder[18]
self.center = DecoderBlock(num_filters 8 2, num_filters 8 2, num_filters * 8)
self.dec5 = DecoderBlock(num_filters (16 + 8), num_filters 8 2, num_filters 8)
self.dec4 = DecoderBlock(num_filters (16 + 8), num_filters 8 2, num_filters 4)
self.dec3 = DecoderBlock(num_filters (8 + 4), num_filters 4 2, num_filters 2)
self.dec2 = DecoderBlock(num_filters (4 + 2), num_filters 2 * 2, num_filters)
self.dec1 = ConvRelu(num_filters * (2 + 1), num_filters)
self.final = nn.Conv2d(num_filters, 1, kernel_size=1)
def forward(self, x):
conv1 = self.relu(self.conv1(x))
conv2 = self.relu(self.conv2(self.pool(conv1)))
conv3s = self.relu(self.conv3s(self.pool(conv2)))
conv3 = self.relu(self.conv3(conv3s))
conv4s = self.relu(self.conv4s(self.pool(conv3)))
conv4 = self.relu(self.conv4(conv4s))
conv5s = self.relu(self.conv5s(self.pool(conv4)))
conv5 = self.relu(self.conv5(conv5s))
center = self.center(self.pool(conv5))
dec5 = self.dec5(torch.cat([center, conv5], 1))
dec4 = self.dec4(torch.cat([dec5, conv4], 1))
dec3 = self.dec3(torch.cat([dec4, conv3], 1))
dec2 = self.dec2(torch.cat([dec3, conv2], 1))
dec1 = self.dec1(torch.cat([dec2, conv1], 1))
return self.final(dec1)
def unet11(pretrained=False, **kwargs):
"""
pretrained:
False - no pre-trained network is used
True - encoder is pre-trained with VGG11
carvana - all weights are pre-trained on
Kaggle: Carvana dataset https://www.kaggle.com/c/carvana-image-masking-challenge
"""
model = UNet11(pretrained=pretrained, **kwargs)
if pretrained == 'carvana':
state = torch.load('TernausNet.pt')
model.load_state_dict(state['model'])
return modeldemo.py
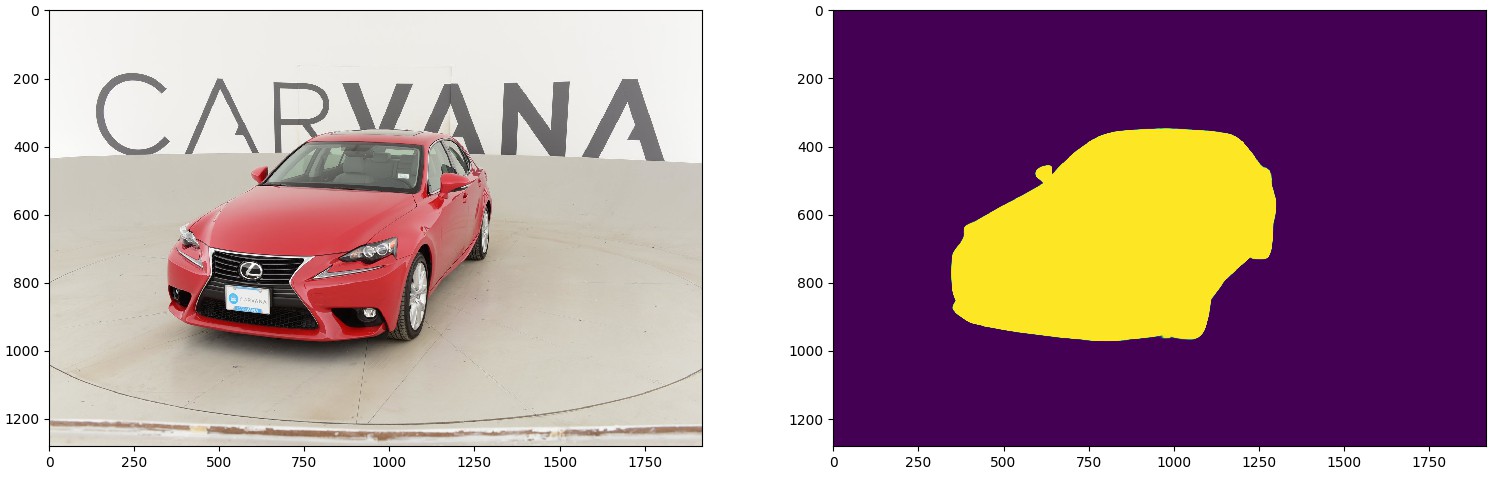
import cv2 import numpy as np import matplotlib.pyplot as plt import torch from torch import nn from unet_models import unet11 from torch.nn import functional as F from torchvision.transforms import ToTensor, Normalize, Compose device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def get_model(): model = unet11(pretrained='carvana') model.eval() return model.to(device) def mask_overlay(image, mask, color=(0, 255, 0)): """ Helper function to visualize mask on the top of the car """ mask = np.dstack((mask, mask, mask)) * np.array(color) mask = mask.astype(np.uint8) weighted_sum = cv2.addWeighted(mask, 0.5, image, 0.5, 0.) img = image.copy() ind = mask[:, :, 1] > 0 img[ind] = weighted_sum[ind] return img def load_image(path, pad=True): """ Load image from a given path and pad it on the sides, so that eash side is divisible by 32 (newtwork requirement) if pad = True: returns image as numpy.array, tuple with padding in pixels as(x_min_pad, y_min_pad, x_max_pad, y_max_pad) else: returns image as numpy.array """ img = cv2.imread(str(path)) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) if not pad: return img height, width, _ = img.shape if height % 32 == 0: y_min_pad = 0 y_max_pad = 0 else: y_pad = 32 - height % 32 y_min_pad = int(y_pad / 2) y_max_pad = y_pad - y_min_pad if width % 32 == 0: x_min_pad = 0 x_max_pad = 0 else: x_pad = 32 - width % 32 x_min_pad = int(x_pad / 2) x_max_pad = x_pad - x_min_pad img = cv2.copyMakeBorder(img, y_min_pad, y_max_pad, x_min_pad, x_max_pad, cv2.BORDER_REFLECT_101) return img, (x_min_pad, y_min_pad, x_max_pad, y_max_pad) img_transform = Compose([ToTensor(), Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) def crop_image(img, pads): """ img: numpy array of the shape (height, width) pads: (x_min_pad, y_min_pad, x_max_pad, y_max_pad) @return padded image """ (x_min_pad, y_min_pad, x_max_pad, y_max_pad) = pads height, width = img.shape[:2] return img[y_min_pad:height - y_max_pad, x_min_pad:width - x_max_pad] model = get_model() img, pads = load_image('lexus.jpg', pad=True) with torch.no_grad(): input_img = torch.unsqueeze(img_transform(img).to(device), dim=0) with torch.no_grad(): mask = F.sigmoid(model(input_img)) mask_array = mask.data[0].cpu().numpy()[0] mask_array = crop_image(mask_array, pads) plt.subplot(1, 2, 1) plt.imshow(img) plt.subplot(1, 2, 2) plt.imshow(mask_array) plt.show() print('Done.')
13 条评论
你好,我也需要一份ternausnet.pt,如果方便的话请发送至邮箱21210860041@m.fudan.edu.cn
你好,ternausnet.pt 链接无效了,请问还有吗,请发送至邮件 2457571634@qq.com
作者您好,可以麻烦您发一份ternausnet.pt给我吗,文章里的链接失效了,我的邮箱是1666371476@qq.com,谢谢!
你好,ternausnet.pt链接失效了,请问还有吗,请发送至邮件2312930648@qq.com
已发送邮箱.
你好,ternausnet.pt链接失效了,请问能发到我邮箱吗 sdujnbj@163.com,麻烦您了
已发送到邮箱.
你好,ternausnet.pt链接无效了,请问还有吗,请发送至邮件823451255@qq.com
已发送到邮箱.
您好,ternausnet.pt文件也可以发我邮箱一下吗?16221147@bjtu.edu.cn 。麻烦您了,辛苦了
已发送到邮箱.
你好,ternausnet.pt链接失效了,请问还有吗,请发送至邮件3292645343@qq.com
已发送到邮箱.