Kaggle Carvana Image Masking Challenge
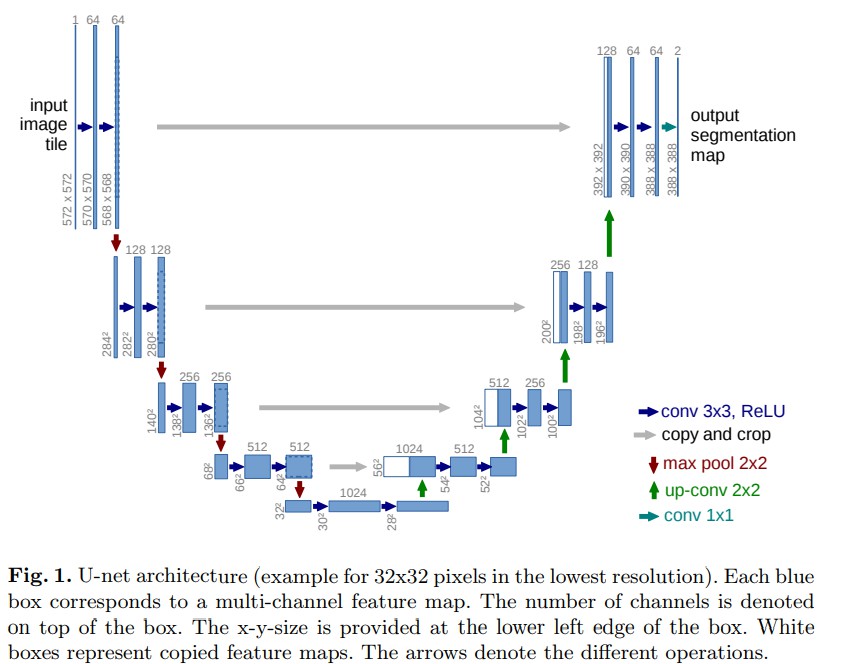
1. UNet
Github 项目 - Pytorch-UNet
Pytorch-UNet - U-Net 的 PyTorch 实现,用于二值汽车图像语义分割,包括 dense CRF 后处理.
Pytorch-UNet 用于 Carvana Image Masking Challenge 高分辨率图像的分割. 该项目只输出一个前景目标类,但可以容易地扩展到多前景目标分割任务.
Pytorch-UNet 提供的训练模型 - MODEL.pth,采用 5000 张图片从头开始训练(未进行数据增强),在 100k 测试图片上得到的 dice coefficient 为 0.988423. 虽然结构并不够好,但可以采用更多数据增强,fine-tuning,CRF 后处理,以及对 masks 的边缘添加更多权重等方式,提升分割精度.
2. pydensecrf 库
[[Github - PyDenseCRF]](https://github.com/lucasb-eyer/pydensecrf)
[1] - 安装:
sudo pip install pydensecrf[2] - 使用:
import numpy as np
import pydensecrf.densecrf as dcrf
d = dcrf.DenseCRF2D(640, 480, 5) # width, height, nlabels3. Pytorch-UNet
Pytorch-UNet
[1] - 训练的 PyTorch 模型 - MODEL.pth
[2] - U-Net 网络定义 - unet_parts.py
# sub-parts of the U-Net model
import torch
import torch.nn as nn
import torch.nn.functional as F
class double_conv(nn.Module):
'''(conv => BN => ReLU) * 2'''
def __init__(self, in_ch, out_ch):
super(double_conv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, 3, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv(x)
return x
class inconv(nn.Module):
def __init__(self, in_ch, out_ch):
super(inconv, self).__init__()
self.conv = double_conv(in_ch, out_ch)
def forward(self, x):
x = self.conv(x)
return x
class down(nn.Module):
def __init__(self, in_ch, out_ch):
super(down, self).__init__()
self.mpconv = nn.Sequential(
nn.MaxPool2d(2),
double_conv(in_ch, out_ch)
)
def forward(self, x):
x = self.mpconv(x)
return x
class up(nn.Module):
def __init__(self, in_ch, out_ch, bilinear=True):
super(up, self).__init__()
# would be a nice idea if the upsampling could be learned too,
# but my machine do not have enough memory to handle all those weights
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
else:
self.up = nn.ConvTranspose2d(in_ch//2, in_ch//2, 2, stride=2)
self.conv = double_conv(in_ch, out_ch)
def forward(self, x1, x2):
x1 = self.up(x1)
diffX = x1.size()[2] - x2.size()[2]
diffY = x1.size()[3] - x2.size()[3]
x2 = F.pad(x2, (diffX // 2, int(diffX / 2),
diffY // 2, int(diffY / 2)))
x = torch.cat([x2, x1], dim=1)
x = self.conv(x)
return x
class outconv(nn.Module):
def __init__(self, in_ch, out_ch):
super(outconv, self).__init__()
self.conv = nn.Conv2d(in_ch, out_ch, 1)
def forward(self, x):
x = self.conv(x)
return x[3] - U-Net 网络定义 - unet_model.py
# full assembly of the sub-parts to form the complete net
from .unet_parts import *
class UNet(nn.Module):
def __init__(self, n_channels, n_classes):
super(UNet, self).__init__()
self.inc = inconv(n_channels, 64)
self.down1 = down(64, 128)
self.down2 = down(128, 256)
self.down3 = down(256, 512)
self.down4 = down(512, 512)
self.up1 = up(1024, 256)
self.up2 = up(512, 128)
self.up3 = up(256, 64)
self.up4 = up(128, 64)
self.outc = outconv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
x = self.outc(x)
return x3.1. 测试 demo
import argparse
import os
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
from PIL import Image
from unet import UNet
from utils import resize_and_crop, normalize, split_img_into_squares, hwc_to_chw, merge_masks, dense_crf
from torchvision import transforms
def predict_img(net,
full_img,
scale_factor=0.5,
out_threshold=0.5,
use_dense_crf=True,
use_gpu=False):
img_height = full_img.size[1]
img_width = full_img.size[0]
img = resize_and_crop(full_img, scale=scale_factor)
img = normalize(img)
left_square, right_square = split_img_into_squares(img)
left_square = hwc_to_chw(left_square)
right_square = hwc_to_chw(right_square)
X_left = torch.from_numpy(left_square).unsqueeze(0)
X_right = torch.from_numpy(right_square).unsqueeze(0)
if use_gpu:
X_left = X_left.cuda()
X_right = X_right.cuda()
with torch.no_grad():
output_left = net(X_left)
output_right = net(X_right)
left_probs = F.sigmoid(output_left).squeeze(0)
right_probs = F.sigmoid(output_right).squeeze(0)
tf = transforms.Compose([transforms.ToPILImage(),
transforms.Resize(img_height),
transforms.ToTensor() ])
left_probs = tf(left_probs.cpu())
right_probs = tf(right_probs.cpu())
left_mask_np = left_probs.squeeze().cpu().numpy()
right_mask_np = right_probs.squeeze().cpu().numpy()
full_mask = merge_masks(left_mask_np, right_mask_np, img_width)
if use_dense_crf:
full_mask = dense_crf(np.array(full_img).astype(np.uint8), full_mask)
return full_mask > out_threshold
def mask_to_image(mask):
return Image.fromarray((mask * 255).astype(np.uint8))
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--model', '-m', default='MODEL.pth',
metavar='FILE',
help="Specify the file in which is stored the model"
" (default : 'MODEL.pth')")
# parser.add_argument('--input', '-i', metavar='INPUT', nargs='+',
# help='filenames of input images', required=True)
parser.add_argument('--output', '-o', metavar='INPUT', nargs='+',
help='filenames of ouput images')
parser.add_argument('--cpu', '-c', action='store_true',
help="Do not use the cuda version of the net",
default=False)
parser.add_argument('--viz', '-v', action='store_true',
help="Visualize the images as they are processed",
default=False)
parser.add_argument('--no-save', '-n', action='store_true',
help="Do not save the output masks",
default=False)
parser.add_argument('--no-crf', '-r', action='store_true',
help="Do not use dense CRF postprocessing",
default=False)
parser.add_argument('--mask-threshold', '-t', type=float,
help="Minimum probability value to consider a mask pixel white",
default=0.5)
parser.add_argument('--scale', '-s', type=float,
help="Scale factor for the input images",
default=0.5)
return parser.parse_args()
if name == "__main__":
args = get_args()
args.cpu = 0
args.no_crf = True
args.model = './MODEL.pth'
net = UNet(n_channels=3, n_classes=1)
print("Loading model {}".format(args.model))
if not args.cpu:
print("Using CUDA version of the net, prepare your GPU !")
net.cuda()
net.load_state_dict(torch.load(args.model))
else:
net.cpu()
net.load_state_dict(torch.load(args.model, map_location='cpu'))
print("Using CPU version of the net, this may be very slow")
print("Model loaded !")
in_files = os.listdir('/path/to/testcars')
for i, fn in enumerate(in_files):
fn = os.path.join('/path/to/testcars', fn)
print("nPredicting image {} ...".format(fn))
img = Image.open(fn)
if img.size[0] < img.size[1]:
print("Error: image height larger than the width")
else:
mask = predict_img(net=net,
full_img=img,
scale_factor=args.scale,
out_threshold=args.mask_threshold,
use_dense_crf=not args.no_crf,
use_gpu=not args.cpu)
print("Visualizing results for image {}, close to continue ...".format(fn))
fig = plt.figure()
a = fig.add_subplot(1, 2, 1)
a.set_title('Input image')
plt.imshow(img)
b = fig.add_subplot(1, 2, 2)
b.set_title('Output mask')
plt.imshow(mask)
plt.show()
3.2. 未进行 dense crf 后处理
未进行 dense crf 后处理:

dense crf 后处理:
7 条评论
作者您好,可以麻烦您发一份 MODEL.pth给我吗,文章里的链接失效了,我的邮箱是1666371476@qq.com,谢谢!
参考:https://github.com/milesial/Pytorch-UNet/#pretrained-model
感谢谢作者
请问这一步后,返回的true和false:return full_mask > out_threshold,在下一步转Image时会报错,请问怎么解决呀
报错提示是什么呢
能发一份MODEL.pth给我吗,谢谢,我的邮箱823451255@qq.com
您好,可以麻烦您发一份 MODEL.pth给我吗,文章里的链接失效了,我的邮箱是595644129@qq.com,谢谢!