深度学习大讲堂 版权所有
推荐关注 深度学习大讲堂 公众号 - deeplearningclass.
转载此处,只用于个人学习备忘. 如若侵权,知悉后,随时删除.
非常感谢!
编者按:在徐凝的《宫中曲》中有这样一句诗,“一日新妆抛旧样”,描绘了中唐时期宫中女人换妆的场景,而另一句诗“檀妆唯约数条霞”,讲的则是复杂的檀妆其实只需寥寥数笔来勾勒.
而在计算机视觉世界中,像素级语义理解技术,则赋予了机器对人脸进行换妆的能力,其通过细粒度分割的方式,将面部的不同区域在像素级剥离开来,从而将换妆的过程简化为寥寥数笔.
今天,来自中科院信息工程研究所的刘偲副研究员 ,将为大家讲述如何利用像素级语义分割技术,在计算机视觉领域用寥寥数笔来为图像换妆.

本次报告的主题为“图像的像素级语义理解”,本文将从语义分割算法出发,着重介绍其在场景解析、人脸解析、以及人体解析中的应用情况.
文中所有应用成果均来自于中科院信息工程研究所网络空间技术实验室,http://liusi-group.com/.

物体分类作为计算机视觉一大重要研究方向,其目的是对图片整体进行分类,如上左图所示,物体分类判断图中含有桌子、人、灯.
而当我们进一步想对图片的局部进行分类时,便需要进行物体检测,如上中图所示,用方框画出物体的位置并判断框中物体是桌子、人或是灯.
当我们想更进一步,对图片中的每个像素进行分类时,我们便进入了一个更加细致的领域,那就是像素级的语义分割,如上右图,每个像素都标上了对应的类别.
可以看出,从物体分类到物体检测再到语义分割,任务的粒度越来越细.
今天我所要介绍的主要内容便是三者中最为细致的语义分割.
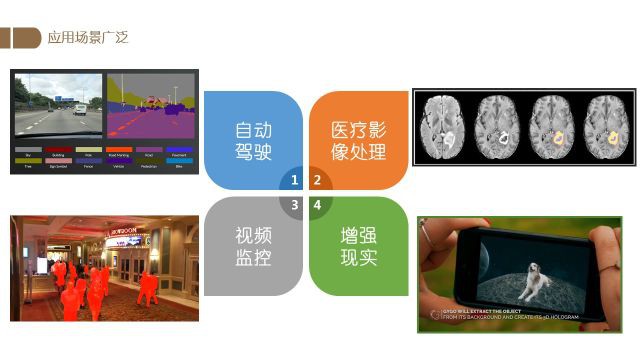
图像的像素级语义理解应用场景非常广泛,在自动驾驶、医疗影像处理、视频监控以及增强现实(AR)中都有很大的使用空间.
例如在自动驾驶中可以通过对获取到的图像进行分割,以辅助车辆更好地对前方场景进行分析和判断;
在医疗影像处理中,可以通过对图像进行解析,准确地发现并定位患者体内的病变组织,从而为治疗提供更多的可靠信息.
图像语义分割相关研究概述
首先回顾一下一些经典的图像分割数据集及算法.
图像分割数据集

早期语义分割数据集,通常包含图片数量、物体类别较少.
例如,2005年由微软提出的MSRC包含23类物体,591张图片.
2008年的LabelMe则含有183类物体,3万多张图片.
2009年第一个道路语义分割的数据集CamVid发布.
2011年的SIFTFLOW类别数为33类,含有2688张图片.
2012年的PASCAL VOC含有21类物体以及2913张图片,该数据集后来成为了语义分割任务中一个重要的benchmark dataset.
2014年在PASCAL VOC的基础上,PASCAL CONTEXT将物体类别以及图片数量都进行了大幅地扩充.
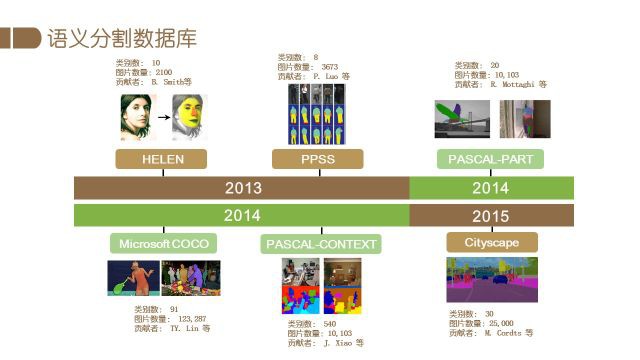
2013年针对人脸分割的Helen分割数据集发布,同年发布的还有香港中文大学的人体分割数据集PPSS.
2014年发布的PASCAL PART将PASCAL VOC中物体的部位进行细分,提供了更加细致的分割标注.
同年微软提出了COCO数据集,丰富的图片和类别使其成为了又一重要的benchmark dataset.
随后,针对道路图片的Cityscape以及含有深度信息的SUN RGB-D数据集也被发布了出来.
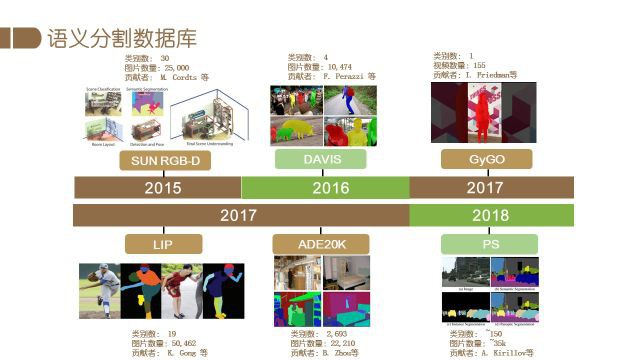
2016年的DAVIS数据集将instance级的分割与视频相结合,提出了视频中的物体分割这一更加具有挑战的任务,类似的还有2017年发布的GyGO数据集。
2017年中山大学、商汤科技集团等发布了一个更加完善的人体分割数据库LIP(Look into Person),同年发布的ADE20K则将物体类别推向了极致,数据集中标注了将近2700类的物体.
近期由FAIR发布的Panoptic Segmentation则整合了已有的多个数据集并提出了一个新的分割任务.
现在我们来介绍一下语义分割算法的前世今生.
语义分割算法

早期的算法中有参数型方法的代表Texton Boost,也有Label Transfer等非参的方法.
2012年发表于TPAMI的Learning Hierarchical Features for Scene Labeling则是第一篇将深度学习应用于语义分割的算法.
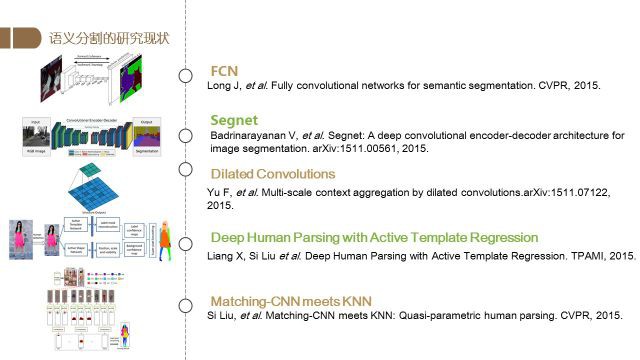
2015年由Long等人提出的Fully Convolutional Networks for Semantic Segmentation(FCN) 不仅获得了当年CVPR的best paper候选,还引领了之后语义分割算法使用全卷积网络的方向.
之后的Segnet提出了复用encoding特征的办法,带有洞的卷积(Dilated Convolution)扩大了网络的视野域,极大地提升了分割的精度,成为了语义分割网络的“标配”.
2015年梁小丹博士和我本人合作发表于TPAMI的Deep Human Parsing with Active Template Regression首次将语义分割应用于人像解析.
我们的另一篇工作Matching-CNN meets KNN: Quasi-parametric human parsing则将KNN的方法与CNN进行结合,提升了网络对人体进行解析的能力.

之后Deeplab算法结合了dilated convolution以及fully connected crfs,提升了分割性能.
RefineNet则提出了一种将高层语义特征以及底层特征进行融合的结构,极大地改进了性能.
随后商汤科技公司提出的PSPNet引入了Pyramid Pooling Module,在获得了多个尺度特征的基础上,通过结合这些特征得到更好的分割结果.
旷视科技提出的Large Kernel Matters则使用了较大的卷积以及一个Boundary Refinement模块来提升网络的整体性能.
之后FAIR的Mask RCNN提出RoI Align层,在faster-rcnn的基础上实现了instance级的语义分割.
随后Deeplab的改进版MaskLab提出一种新的方向特征,改进了instance级分割效果.
回顾完语义分割的数据集以及常见算法.
下面我们将介绍我们组在这方面的工作.
报告者组的研究工作

从场景解析、人脸解析以及人体解析三个方面来分别作介绍.
场景解析

壁纸作为家中装饰的一个非常重要的部分,常常决定了整个房间的气氛.
于是很多人在装修时一定会想看一下自己的房间适合换上什么样的壁纸.
因此,我们提出了一个可以对墙壁壁纸进行解析以及更换的模型.
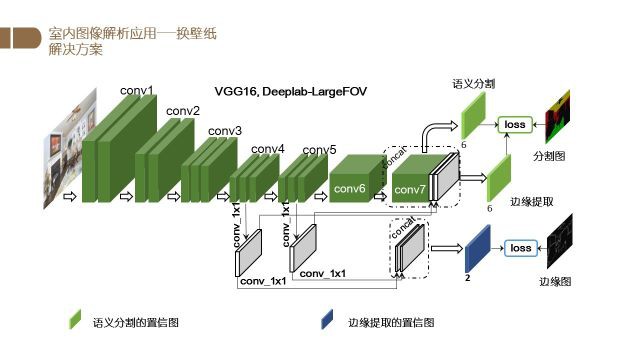
具体来说,在给定输入的图片之后,我们先用一个基于VGG16的Deeplab-LargeFOV模型提取特征。
此外,我们加入了两个1x1的卷积对con4和conv5的特征进行提取以得到图像的边缘信息,之后再将边缘信息与语义分割的结果进行融合,得到最终的分割结果.
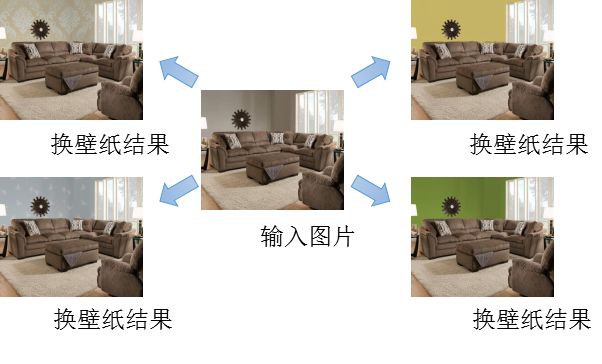
根据分割的结果,我们就可以对壁纸进行颜色和纹理的更换.
该工作发表于2017年的ACM Multimedia会议.
下图是一些结果展示.
人脸解析

首先我们定义一下这里所说的人脸解析问题.
如上图所示,对于给定的一张人脸图片,我们希望得到不同语义部位的分割结果,换句话说就是将图像中的每个像素标注为对应的类别.
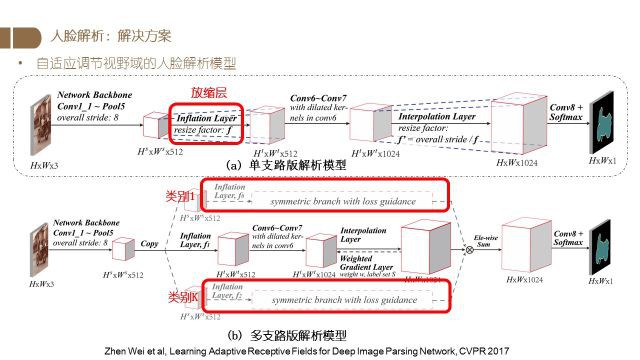
上图是我们课题组在CVPR2017所发表的一份工作.
通过加入一个可学习的放缩层,可以让网络自动地去调节视野域以得到最好的分割结果.
为此我们设计了两个不同版本的网络,其中单支路版本使用一个resize factor对特征进行变换,并使用变换后的特征进行前向计算,得到最终分割结果.
而多支路的版本则可以根据需要设置多个支路并让每个支路学习到不同的resize factor,最终将这些特征进行合并、并进行前向计算,得到分割结果.
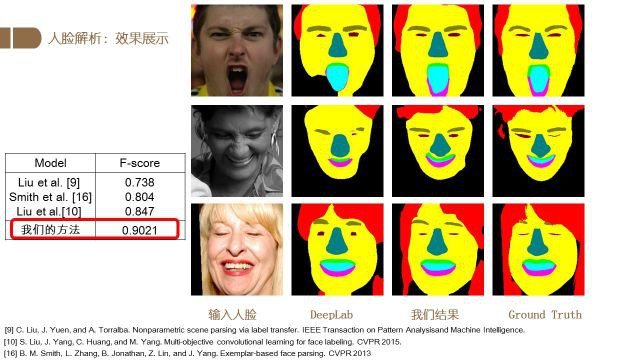
上图是我们的方法与其他人脸解析算法的定量及定性结果比对.
可以看出我们的算法显著提升了解析的效果.
仔细看图中右方的结果图,可以看出在嘴唇、眉毛、眼睛等部位的结果上,我们的方法结果更好.

基于人脸解析,我们开展了多项工作,主要有智能美妆、妆容迁移、人脸老化三个工作.
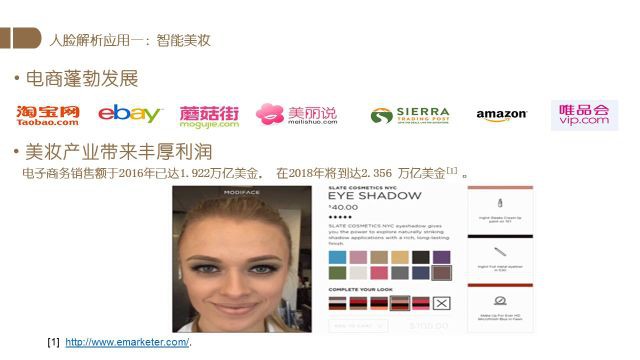
首先是智能美妆部分.
电商的发展以及美妆业的巨大市场催生了对智能美妆产品的需求.


根据人脸解析的结果,我们可以将指定的美妆产品应用于图片,最终得到美妆的结果.
具体来说,在得到人脸解析结果后我们将选择的化妆产品应用于相应的区域.
有了这一系统,我们可以在不用手动化妆、卸妆的情况下尝试不同的妆容效果.

一些女生看到明星的照片时,常常会想看自己化上同样的妆是什么样子.
为此我们设计了一个基于深度学习的妆容迁移算法.


如上面两图所示.
我们通过人脸解析算法得到妆容的关键区域,然后使用风格迁移的算法将不同区域的妆容转移至对应的区域.根据不同的参考妆容可以获得不同的迁移结果.
通过控制迁移时的参数,我们还可以控制妆容的浓淡.
相应工作发表于IJCAI 2016.
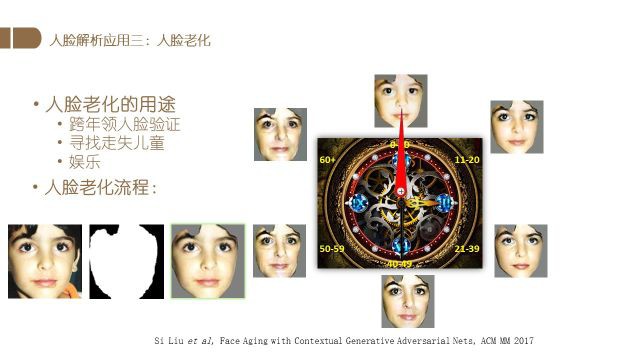
人脸解析的第三个应用是人脸老化.
人脸老化对于跨年龄验证、走失人口寻找都有重要意义,而且具有一定的娱乐价值.
在我们的工作中,先通过人脸解析提取人脸的主要部分,然后使用图片以及对应的年龄信息训练一个生成对抗网络(GAN).
在训练好模型后,将一个人的照片以及想转换到的年龄信息输入进这个模型,就可以得到相应年龄段的照片.该论文发表于ACM MM 2017.
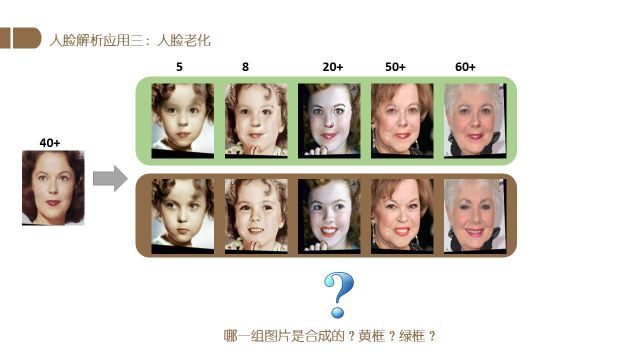
上图右方两行图片中,有一行是我们的网络生成的结果,有一行是真实的图片。
各位猜一猜哪一行是真实的,哪一行是生成的。
正确答案是:第一行是生成的图片,第二行是真实的图片。不知道各位猜对了没有~

上图是两个不同人物的生成结果.
我们生成了这两个人在0-10岁、19岁-29岁、40-49岁、及60岁以后四个年龄段的结果.
可以从下面的动图里看到整个变化过程.
人体解析
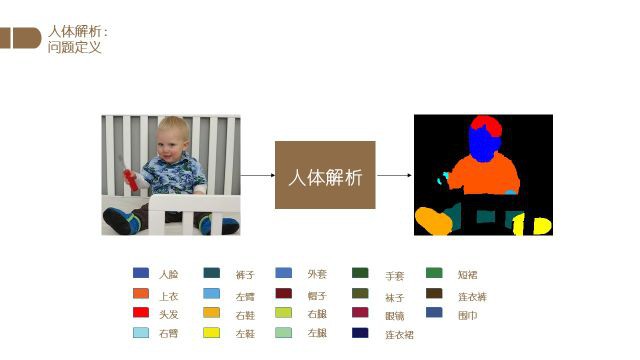
最后介绍一下人体解析的相关工作.
与人脸解析部分相同,我们首先定义一下人体解析问题.
对于一个给定的人物图片,人体解析的主要任务是将图片中人体的不同部位进行分类,最后获得像素级的分类结果.
如上图所示.
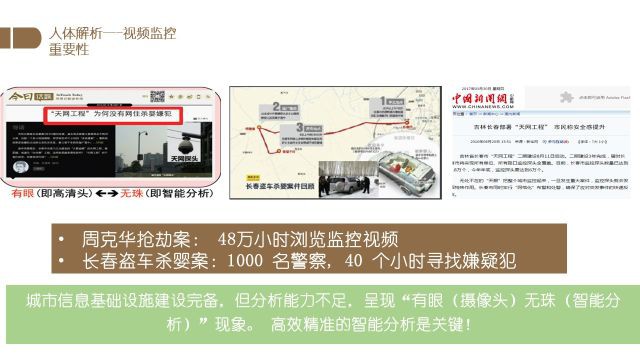
那么研究人体解析有什么样的重要性呢?
举两个经典案例,在周克华抢劫案以及长春盗车杀婴案件中,虽然案发城市已经有完备的监控设备,但由于缺乏相应的分析能力,导致视频的筛选和分析仍需人力来进行,被人们形容为“有眼无珠”.
如果能减少相应的人力消耗并提高分析速度,将会给社会带来很大的积极影响.


如上图所示。设计好的分割模型可以准确地将人体图像进行分割,同时属性预测模型可以对人像进行准确的预测.
这样一来,当我们拿到一个描述,例如图中“棕色上衣、黑色紧身裤,拿着白色行李箱的女性”时,计算机便可以快速地在海量监控数据中自动地找到匹配的图片或视频.
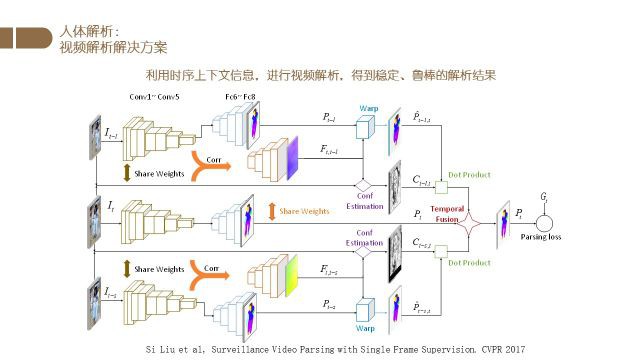
上图是我们CVPR2017的一个工作的网络结构框图.
该工作充分利用了多帧的信息,得到了很好的人体分割结果.
下面我们将介绍网络的各个部分以及相应的功能.
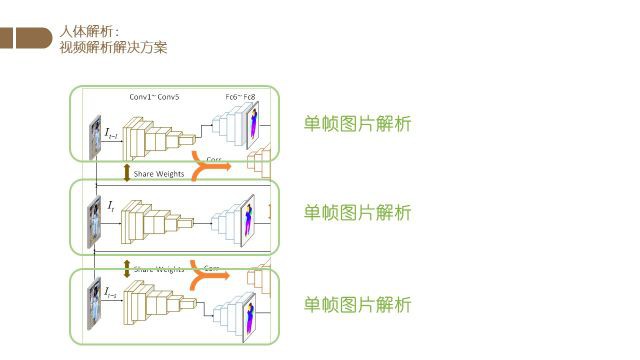
首先我们使用一个基于FCN(全卷积网络)的分割网络对视频中的不同帧进行分割.
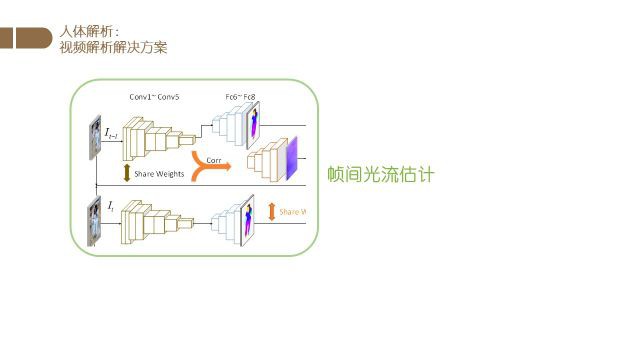
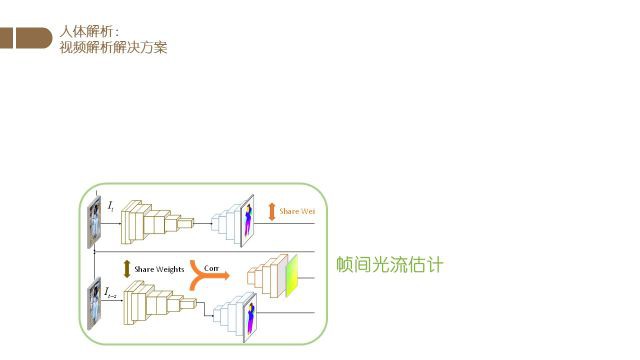
然后我们使用分割时所使用的特征进行光流的估计,得到帧与帧之间的光流信息.
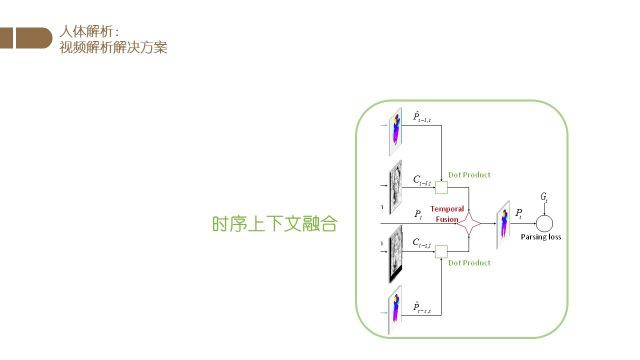
最后我们根据光流信息对不同帧的结果进行融合.
最终得到目标帧的分割结果.
下图是我们分割算法以及属性预测算法的动态演示图.

总结与展望

首先分享了我们在场景解析方面的工作,主要是壁纸虚拟更换以及图片去雾霾工作(由于篇幅未展开).
然后介绍了在人脸解析方面的工作,包括妆容迁移、人脸老化、智能美妆.
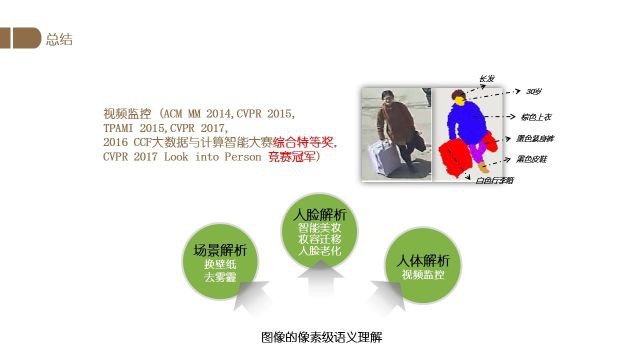
最后我介绍了在人体解析方面的工作,主要是视频监控中的人体解析任务.
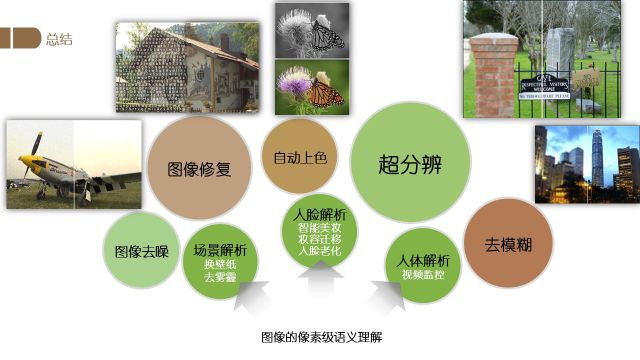
图像的像素级语义理解还有很多的研究方向,例如图像去噪、图像修复、自动上色、超分辨率、去模糊等等.

对于未来的发展,我们认为主要有三个趋势。
[1] - 首先是模型的小型化,未来深度学习的模型将逐渐从计算、储存能力丰富的GPU集群走向CPU平台或是嵌入式设备中,这对模型的大小以及计算复杂度都将有更严格的限制.
[2] - 第二个趋势就是数据标注的低成本化,未来将会有更多的弱监督、半监督算法涌现,加上迁移学习的发展,我们对于数据的人工标注将会越来越少。相应的成本也将越来越低.
[3] - 最后是信息源的多模态化,现在的图像解析工作大多基于普通的RGB三通道图片.但随着信息源的增多,我们可以获得深度信息、雷达探测信息等更多的数据. 通过这些数据的整合,我们将进一步提升解析算法的性能.
涉及的论文下载 - https://pan.baidu.com/s/1pMuaqHd