问题:
给定 mini-batch image-text 图文对数据,$\mathcal{B} = \{ (I_1, T_1), (I_2, T_2), ... \}$, 对比学习(Contrastive Learning) 的目标是,使得匹配的 $(I_i, T_i)$ 的特征(Embeddings) 互相对齐,而不匹配的 $(I_i, T_{j \neq i})$ 的特征拉开差距。
一般假设,对于所有的图像 $i$,其他图像$j$ 的对应文本都是与 $i$ 不相关的。 这种假设往往是噪声和不完美的。
SigLIP
Sigmoid Loss for Language Image Pre-Training
1. Softmax Loss 语言文本预训练
回顾下 Softmax Loss.
通常需要训练一个 image model $f$ 和一个 text model $g$,最小化如下损失函数:
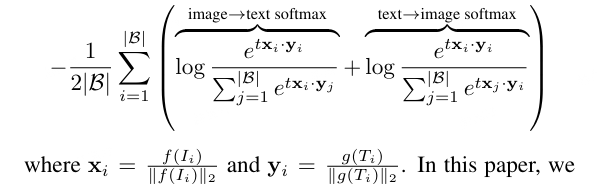
2. Sigmoid Loss 语言文本预训练
https://github.com/google-research/big_vision
提出一种不需要计算全局归一化因子的 Sigmoid Loss,其分别处理每个 image-text 图文对,有效的将模型训练问题转换为标准的二值分类.
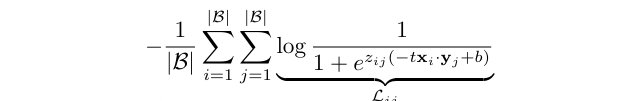
其中,$z_{ij}$ 是每个给定的图像和文本的标签,如果该图像和文字是一对,则 $z_{ij} = 1$,否则,$z_{ij} = -1$
算法伪代码如:

3. Data parallelism 数据并行实现
对比学习往往需要用到数据并行,即,数据被分到 $D$ 台设备,计算损失时,必须通过高成本的 all-gather 操作聚合所有 embeddings,更重要的是,这还需要构建一个内存密集型的 B×B 成对相似度矩阵。
而,对于 Sigmoid loss,
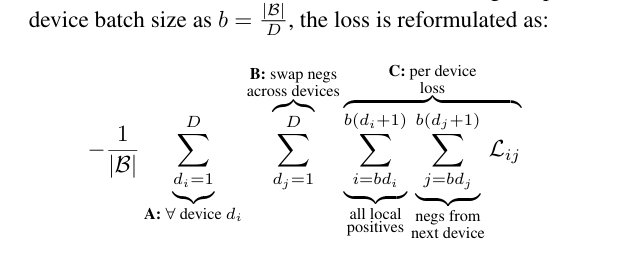
如图,
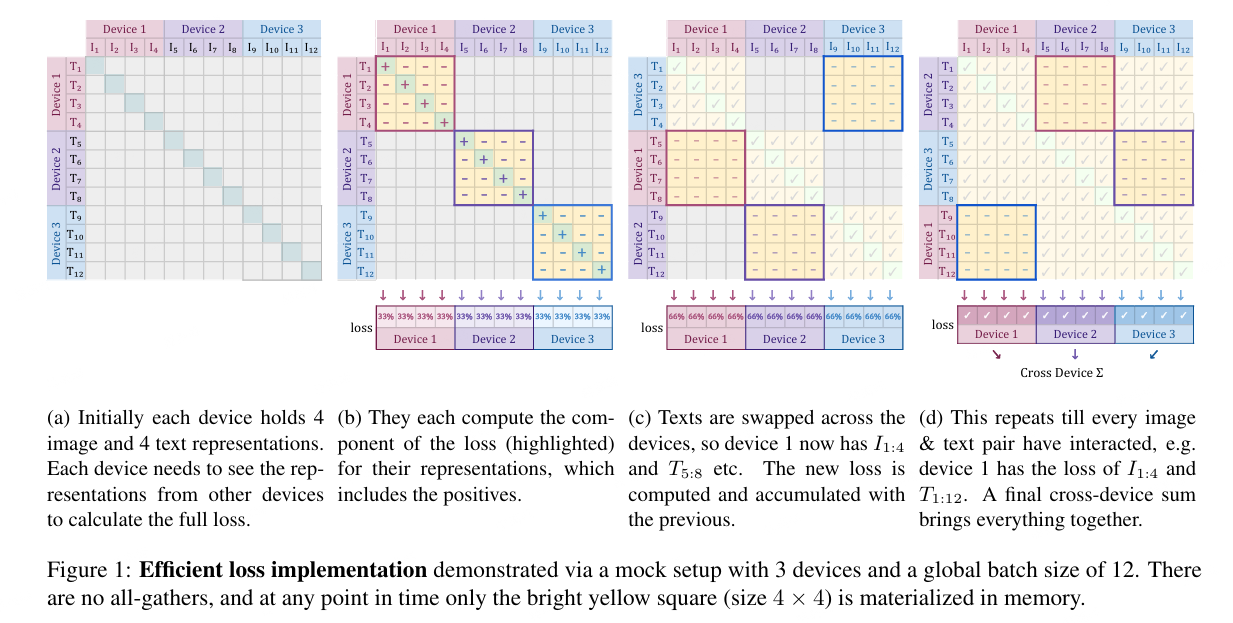
4. mSigLIP: Multi-lingual pre-training
多语言预训练.
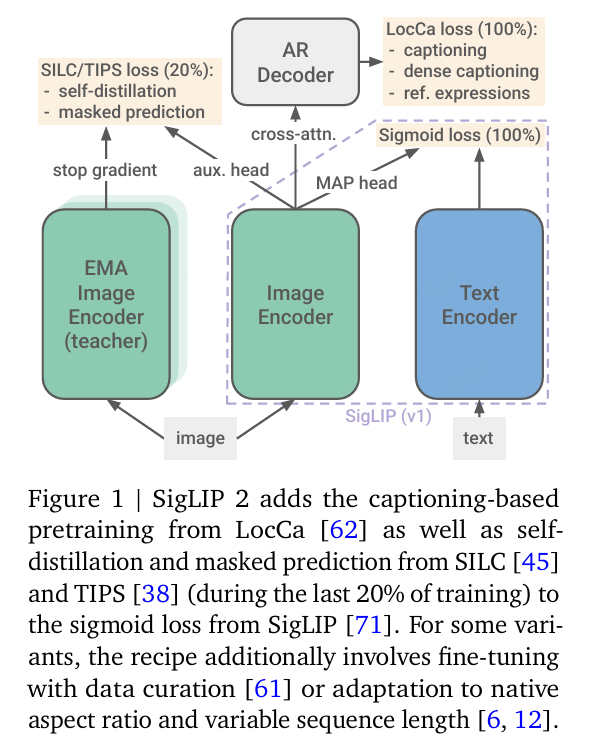
SigLIP2
多语言视觉语言编码器,multilingual vision-language encoders
将 SigLIP 的图文训练目标,与多项之前已有独立技术,形成一套统一方案,包括:括基于描述的预训练(captioning-based pretraining)、自监督损失(self-supervised loss, self-distillation、masked prediction) 以及在线数据筛选(online data curation).
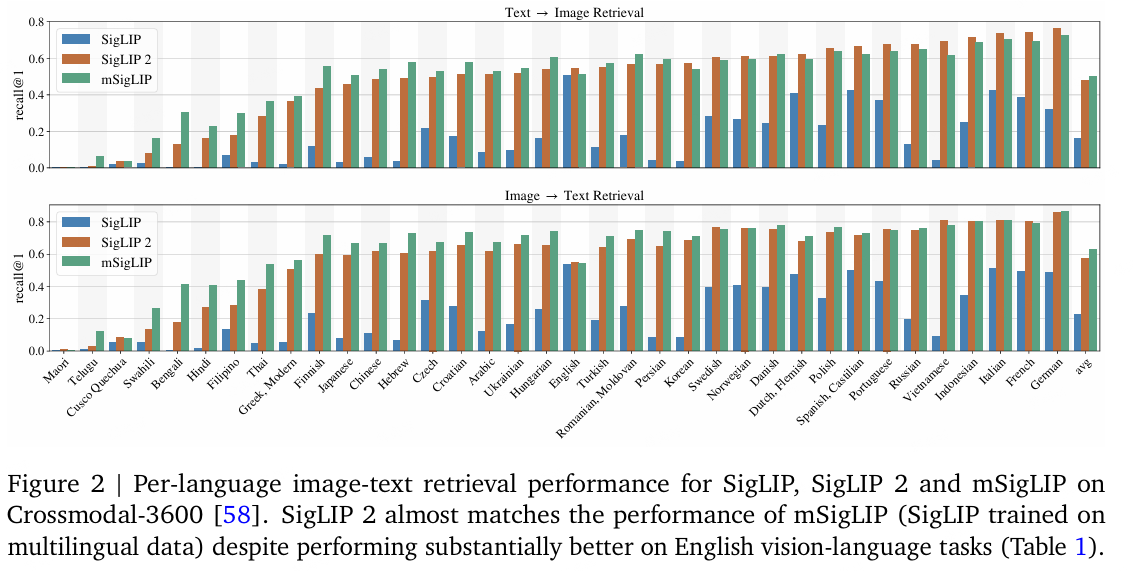
图文检索任务的精度对比,
https://huggingface.co/blog/siglip2
视觉编码器,是将接收图像,将其编码为表征向量,该表征可用于分类、目标检测、图像分割等下游视觉任务。
致力于追求具备密集性、局部感知能力和语义丰富性的视觉表征( dense, locality-aware, and semantically rich)。
实现
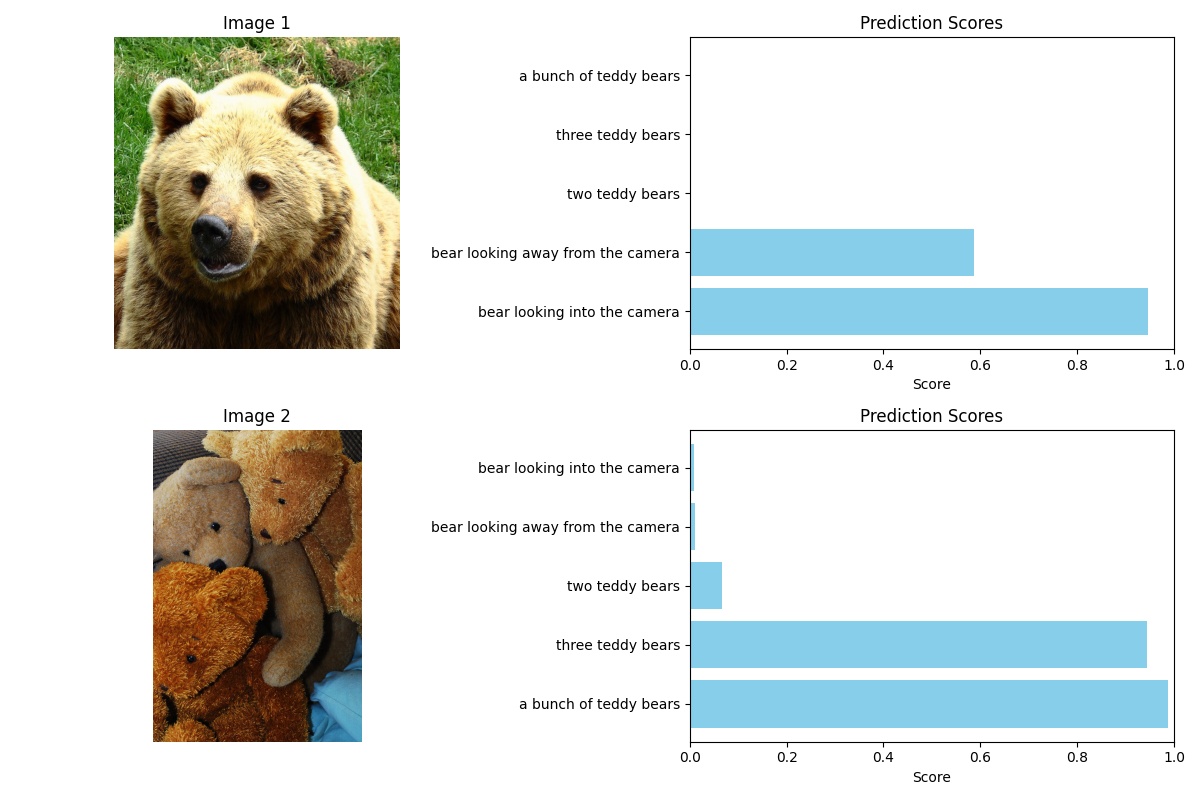
from transformers import pipeline
ckpt = "google/siglip2-so400m-patch14-384"
pipe = pipeline(model=ckpt, task="zero-shot-image-classification")
inputs = {
"images": [
"https://huggingface.co/datasets/merve/coco/resolve/main/val2017/000000000285.jpg", # bear
"https://huggingface.co/datasets/merve/coco/resolve/main/val2017/000000000776.jpg", # teddy bear
],
"texts": [
"bear looking into the camera",
"bear looking away from the camera",
"a bunch of teddy bears",
"two teddy bears",
"three teddy bears"
],
}
outputs = pipe(inputs["images"], candidate_labels=inputs["texts"])
如,
Embedding 特征提取
import torch
from transformers import AutoModel, AutoProcessor
from transformers.image_utils import load_image
ckpt = "google/siglip2-so400m-patch14-384"
model = AutoModel.from_pretrained(ckpt, device_map="auto").eval()
processor = AutoProcessor.from_pretrained(ckpt)
image = load_image("https://huggingface.co/datasets/merve/coco/resolve/main/val2017/000000000285.jpg")
inputs = processor(images=[image], return_tensors="pt").to(model.device)
with torch.no_grad():
image_embeddings = model.get_image_features(**inputs)
print(image_embeddings.shape) # torch.Size([1, 1152])