原文:Stable Diffusion — ControlNet Clearly Explained! - 2023.06.08
ControlNet 和 Stable Diffusion 的结合,可以让SD接受条件输入,以引导图像生成过程,得到增强版的 SD.
Github - lllyasviel/ControlNet
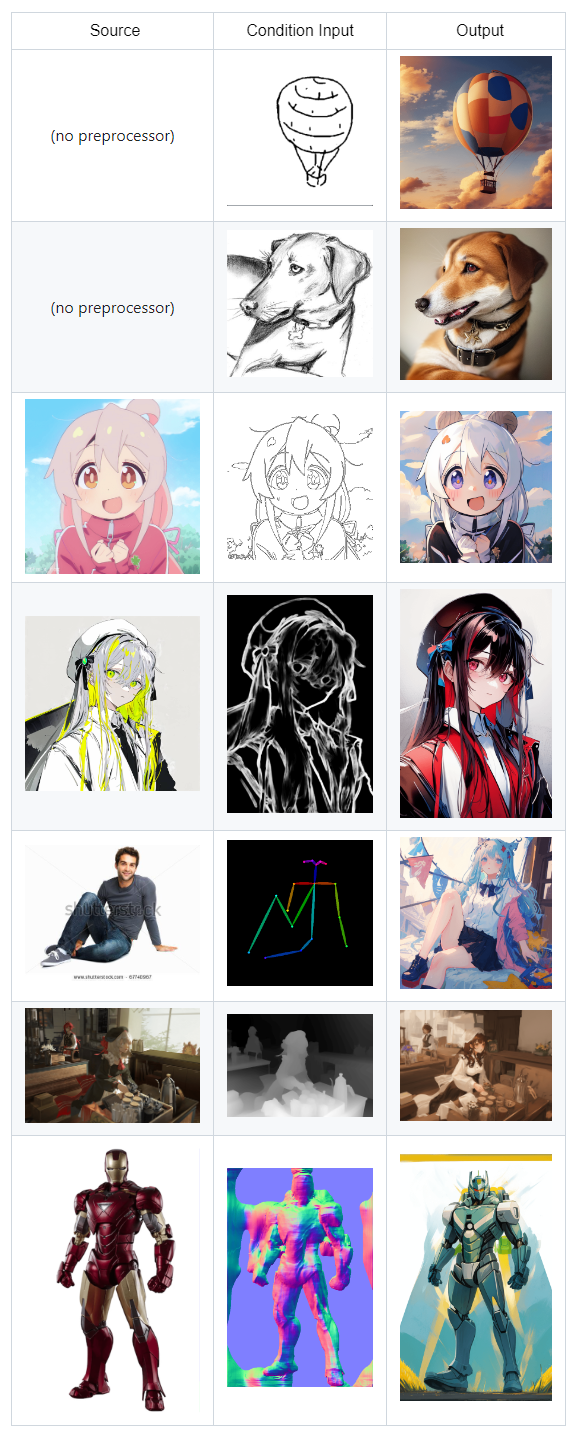
示例如图:
ControlNet 结构
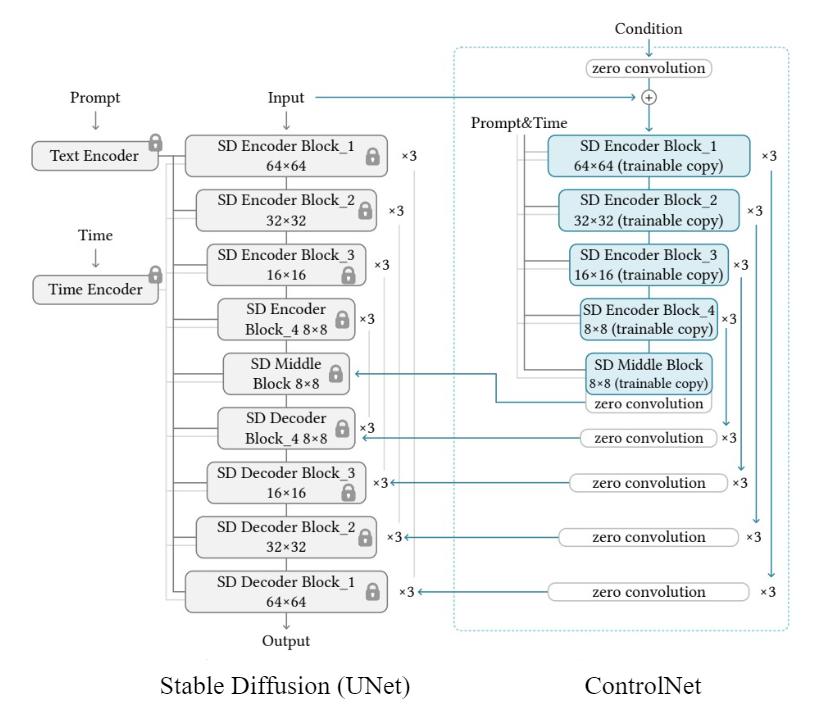
图:ControlNet inner architecture
SD UNet 中的所有参数被冻结,并克隆一份(trainable copy)到 ControlNet. 这些 trainable copy 通过一个外部条件向量(external condition vector)进行训练.
对原来的权重创建副本,而不是直接训练原来的权重,原因在于,
- 避免数据集比较小时的过拟合
- 保持大模型的高质量性能
Feedforward
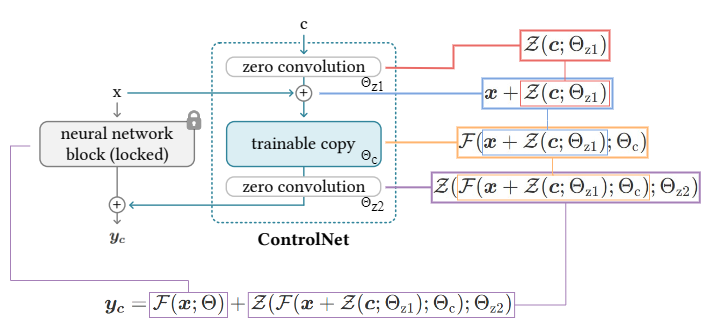
其中,
[1] - $x, y$ - 神经网络中的深度特征
[2] - $c$ - 额外的条件
[3] - $+$ - 特征相加,Feature addition
[4] - $Z(\cdot;\cdot)$ - Zero convolution 操作,weight 和 bias 初始化都是 0 的 1x1 conv 层
[5] - $F(\cdot;\cdot)$ - 神经网络 block 操作,如 resnet block,conv-bn-relu block 等
[6] - $\Theta _{z1}$ - 第一个 zero conv 层的参数
[7] - $\Theta _{z2}$ - 第二个 zero conv 层的参数
[8] - $\Theta _{c}$ - 训练副本(trainable copy) 的参数
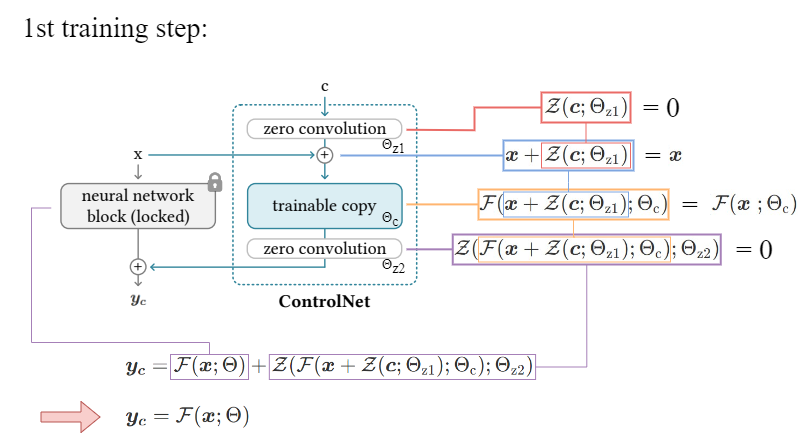
图:The 1st training step of ControlNet
在第一个 training step 过程中,由于 zero conv 层的 weight 和 bias 均初始化为 0,因此,feed-forward 过程与没有 ControlNet 是一致的.
经过 BP后,ControlNet 的 zero conv 层变为非零,并影响输出.
换句话说,当 ControlNet 应用到神经网络 blocks 中,但并没有进行任何优化之前,其并不会影响深度特征.
Backpropagation
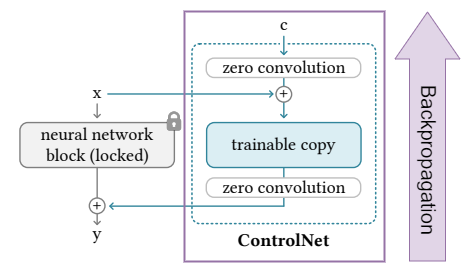
图:ControlNet backpropagation
backpropagation 更新 trainable copy 和 ControlNet 中的 zero conv 层的参数,使得 zero conv 的权重通过学习过程逐渐过渡到优化值.
Why gradient will not be zero?
普遍认为,如果 conv 层的权重是 0,则其梯度也会是 0. 但是,并不一定如此.
假设 $y = wx + b$ 是 zero conv 层,其中 $w$ 和 $b$ 分别是 weights 和 bias,$x$ 是输入的 feature map. 下图是每一项的梯度.
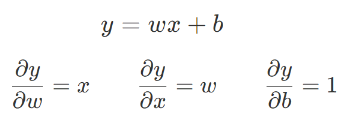
图:The gradient of a general layer
开始时,当 $w=0$ 时,$x$ 一般是非零的. 因此,尽管由于 zero conv,关于 $x$ 的梯度会变为 0,但 weight 和 bias 的梯度是并没有受影响的.
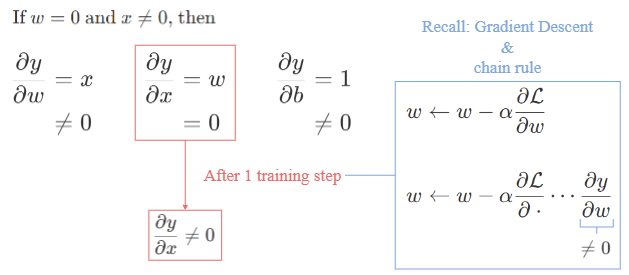
图:All become non-zero after 1 training step
经过一次梯度 step 优化后,权重 $w$ 被更新为 non-zero 值(因为 $y$ 关于 $w$ 的偏微分是 non-zero).
ControlNet with Stable Diffusion
Encoder
由于 SD 的 UNethical 接受的是 latent feature (64x64),而不是原始图像,因此,需要将 image-based conditions 转换为 64x64 feature space,以匹配卷积的尺寸.
$$ c_f = \xi (c_i) $$
可以采用神经网络 $\xi$ 将输入条件 conditions $c_i$ 编码为 feature map $c_f$.
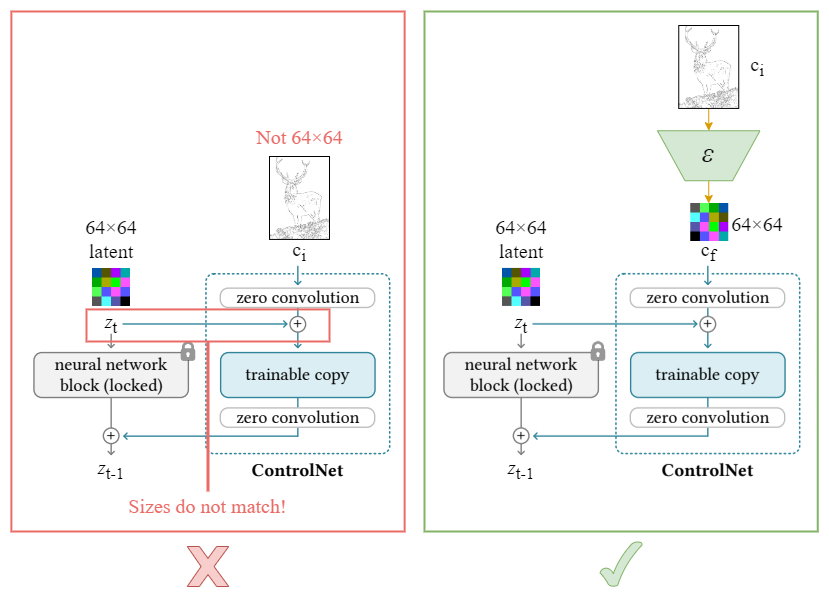
图:ControlNet encoder
如上图,使用 $z_t$ 和 $z_{t-1}$ 作为 locked network block 的输入和输出,以匹配 SD 中的符号表示.
Overall Architecture
如图,一个 denoising step 中,ControlNet 和 SD UNet 的输入和输出.
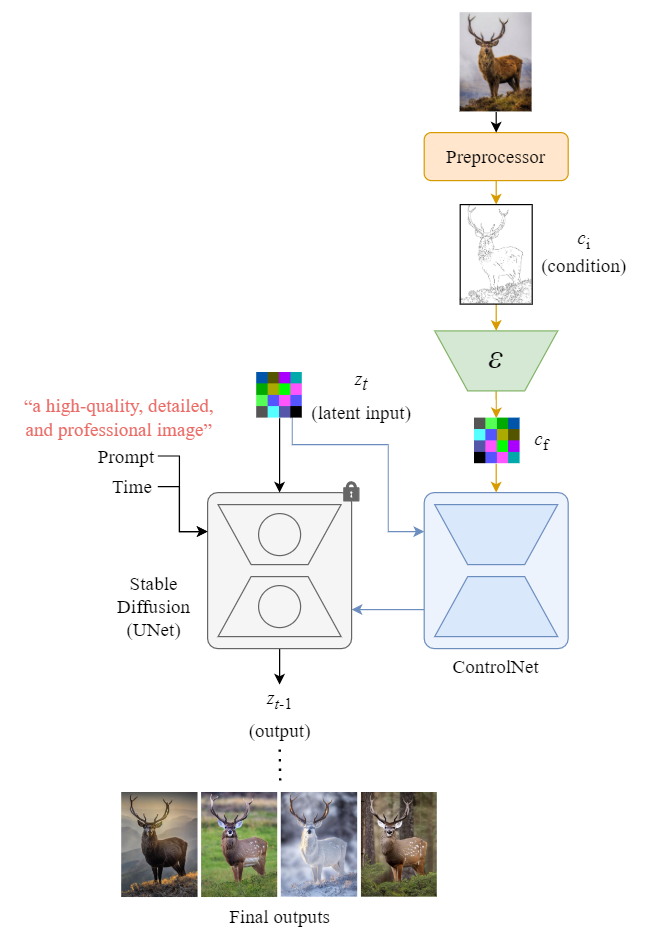
图:The flow of one denoising step
ControlNet 和 SD 的 reverse diffusion process (sampling) 示例,如图:
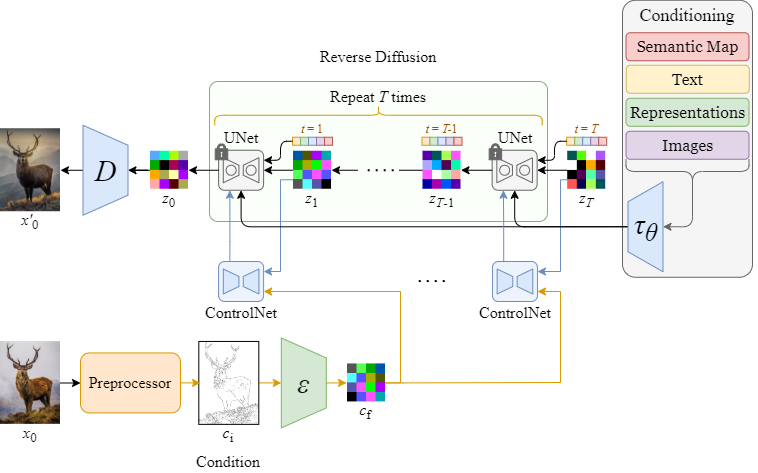
图:The flow of the entire reverse diffusion
Training
ControlNet 的损失函数类似于 SD,但包含了 text condition $c_t$ 和 latent condition $c_f$,以基于特定条件提升输出一致性.

图:ControlNet loss function
作为训练过程的一部分,随机将 text prompts $c_t$ 中的 50% 设为空字符. 有助于提升 ControlNet 对于输入条件图(input condition maps)的更好理解,如Canny edge、human scribbles 等.
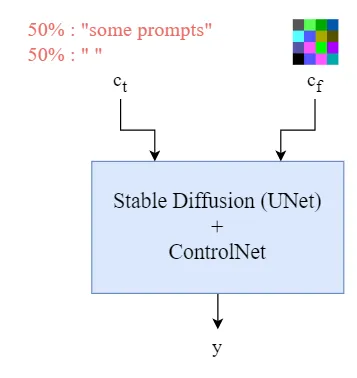
图:Training ControlNet
通过移除 prompts,编码器被强制去学习 control maps 中更多的信息,能够有助于对语义内容的理解能力.
Summary
ControlNet 是与预训练的 Diffusion Model,特指 Stable Diffusion,共同使用的一种神经网络。
ControlNet 允许包含更多的条件输入,如edge maps, segmentation maps, and key points 等.
References
[1] L. Zhang and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” arXiv.org, https://arxiv.org/abs/2302.05543.
1 条评论
太清晰了!!膜拜!!