题目: [[Convolutional Pose Machines - CVPR2016]](http://arxiv.org/abs/1602.00134)
作者: Shih-En Wei, Varun Ramakrishna, Takeo Kanade, Yaser Sheikh
团队: The Robotics Institute Carnegie Mellon University
Code - Caffe
Code - TensorFlow 1.0+
基于序列化的全卷积网络结构,学习空间信息和纹理信息,估计人体姿态.
- Pose Machines 是一种序列化的预测框架,可以学习信息丰富的空间信息模型.
- Convolutional Pose Machines(CPMs) 是将 Convolutional Network 整合进 Pose Machines,以学习图像特征和图像相关(image-depenent)的空间模型,估计人体姿态.
- CPMs 对 long-range 范围内变量间的关系进行建模,以处理结构化预测任务,如,人体姿态估计.
- CPMs 是由全卷积网络组成的序列化结构,卷积网络直接在前一阶段的置信图(belief maps)操作,输出越来越精细化的关节点位置估计结果;
- CPMs 能够同时学习图像和空间信息的特征表示;且,不需要构建任何显式的关节点间关系模型;
- 中间监督 loss 解决梯度消失(vanishing gradients)问题.
- end-to-end with backpropagation.
CPMs 由全卷积网络序列化组成,并重复输出每个关节点的 2D 置信图. 每一个stage,采用图像特征和上一 stage 输出的2D置信图作为输入.
置信图为后面的阶段提供了每个关节点位置的空间不确定性(spatial uncertainty)的非参数编码,使得 CPM 可以学习到丰富的与图像相关的关节点间关系的空间模型.
以 CPM 的某个特定 stage 为例: 关节点置信图的空间信息,为后续 stage 提供了很无歧义的线索信息. 因此,CPM 的每个 stage 都可以输出越来越精细的关节点置信图,如 Figure 1.

为了捕捉关节点间 long-range 的相互关系,CPMs 中每个 stage 的网络设计的启发点是:同时在图像和置信图上得到大的接受野(large receptive field).
1. Pose Machines
记 ${ Y_p \in \mathcal{Z} }$ 表示关节点 p 的像素位置,${ \mathcal{Z} }$ 是图片内所有的关节点位置 $${ (u,v) }$ 集合.
人体姿态估计的目标:预测图片中 P 个人体关节点位置 $${ Y = (Y_1, ..., Y_P) }$.
Pose Machine 由 multi-class 预测器序列组成,如下图,${ g_t(\cdot) }$ 是待训练模型,分类器,用于预测每一 level 中各人体关节点位置.

在每个 stage ${ t \in \lbrace 1,..., T \rbrace }$,分类器 ${ g_t }$ 输出每个关节点位置的置信 ${ Y_p = z, z\in \mathcal{Z} }$. 分类器 ${ g_t }$ 是基于在图像位置 z 所提取的特征为 ${ \mathbf{x}_z \in R^d }$,以及先前 stage 分类器输出的 ${ Y_p }$ 邻域的空间内容信息,进行分类的.
stage t=1 时,分类器 ${ g_1 }$ 输出的关节点置信值:
${ g_1 (\mathbf{x}_z ) \rightarrow \lbrace b_1^p (Y_p = z) \rbrace _{p \in \lbrace 0,...,P \rbrace} }$ (1)
其中,${ b_1^p (Y_p = z) }$ 是分类器 ${ g_1 }$ 是 stage 1 中判定第 p 个关节点在图像位置 z 时的预测分数score.
记在图片每个位置 ${ z = (u,v)^T }$ 关节点 p 的所有置信分数为 ${ \mathbf{b}_t^p \in R^{w×h} }$,w 和 h 分别为图片的宽和高,则:
${ \mathbf{b}_t^p [u, v] = b_t^p (Y_p = z) }$ (2)
简便起见,将所有关节点的置信图(belief maps) 集合记为:${ \mathbf{b}_t \in R^{w × h × (P + 1)} }$ ( P 个关节点加上一个背景类.)
stage t > 1 时,分类器基于两种输入来预测图片关节点位置的置信:
输入1 - 图片特征 ${ \mathbf{x}_z^t \in R^d }$
输入2 - 前一 stage 分类器输出的空间内容信息(contextual information)
${ g_t (\mathbf{x}_z^{\prime}, \psi_t (z, \mathbf{b}_{t-1})) \rightarrow \lbrace b_t^p (Y_p = z)\rbrace_{p \in \lbrace 0,...,P+1\rbrace} }$ (3)
其中 ${ \psi_{t>1}(\cdot) }$ 是置信 ${ \mathbf{b}_{t-1} }$ 到上下文特征的映射.
每个 stage,计算的置信beliefs 对每个关节点的估计越来越精细化.
这里,后续 stage 所用到的图像特征 ${ \mathbf{x}^{\prime} }$ 与 stage t=1 所用到的图像特征 ${ \mathbf{x} }$ 是不同的.
Pose Machine 采用 boosted random forests 作为分类器(${ g_t }$),手工设计所有 stages 的图像特征 ${ \mathbf{x}^{\prime} = \mathbf{x} }$,手工设计特征图feature maps ${ \psi_t(\cdot) }$ 来学习所有 stages 的空间信息.
2. Convolutional Pose Machines - CPMs
CPM 同时利用深度卷积网络的优点,和 Pose Machine 框架的空间建模.
CPM 结构如图:
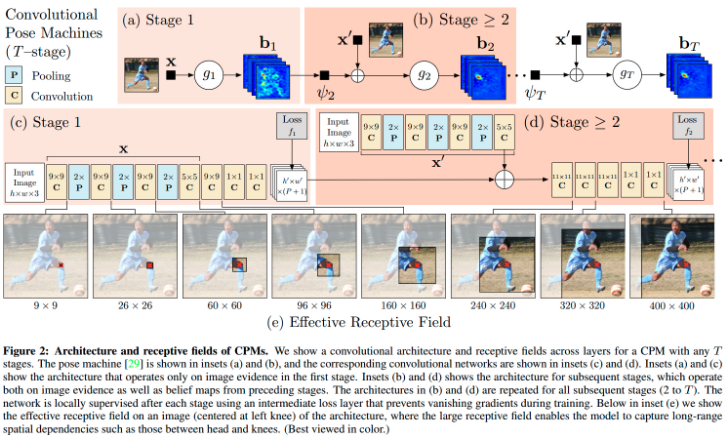
根据源码给出的 deploy.prototxt,CPM 部署时是 multi-scales 的,处理流程:
[1] - 基于每个 scale,计算网络预测的各关节点 heatmap;
[2] - 依次累加每个关节点对应的所有 scales 的 heatmaps;
[3] - 根据累加 heatmaps,如果其最大值大于指定阈值,则该最大值所在位置 (x,y) 即为预测的关节点位置.
2.1. Stage t = 1 时关节点定位
stage t = 1 时, CPM 根据图片局部信息(local image evidence)预测关节点. 利用图片局部信息local,是指,网络的接受野被约束到输出像素值的局部图片块. 如图:
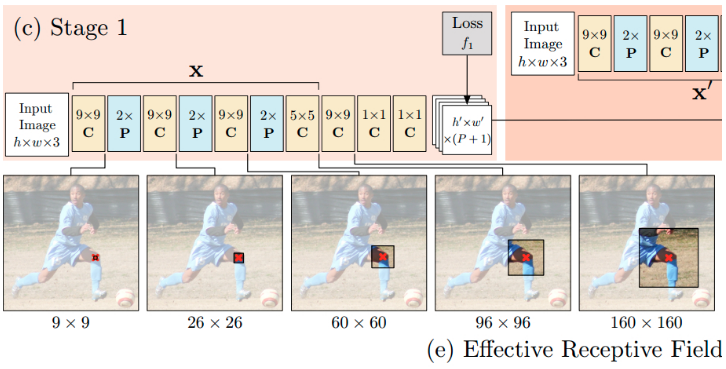
输入图片经过全卷积网络,输出关节点的预测结果. 网络包括 5 个卷积层和 2 个 $1×1$ 卷积层.
输入图片 368 × 368,卷积层不改变 feature maps 的 width 和 height,经三次 pooling 层,输出的 feature maps 大小 46 × 46,共 P + 1 个 feature maps.
The receptive field of the network shown above is 160 × 160 pixels. The network can effectively be viewed as sliding a deep network across an image and regressing from the local image evidence in each 160 × 160 image patch to a P + 1 sized output vector that represents a score for each part at that image location.
${ t \geq 2 }$ 时网络的输出是一致的,都是 46 × 46 × (P+1) 的 feature maps.
2.2. Stage t > 1 时关节点定位
启发点:关节点的置信图(belief maps),尽管存在 noisy, 但却是包含有用信息的. 如图:
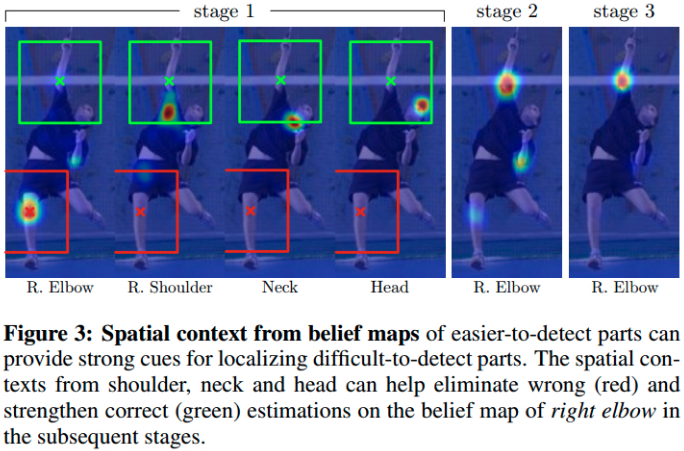
Figure 3. belief maps 的空间信息. 容易检测的关节点可以为难以检测的关节点提供有用信息. (shouler, neck, head) 关节点,对于 (right elbow) 后续 stages 的 belief maps 来说,有助于消除其错误的估计(red),并提升其正确估计(green).
在 stage t > 1 时,分类器 ${ g_{t>1} }$ 可以利用在图像位置 z 的周围区域存在一定 noisy 的 belief maps 的空间内容信息(spatial context),根据关节点一致性几何关系,提高分类器的预测效果.
A predictor in subsequent stages (${ g_{t>1} }$) can use the spatial context ( ${ \psi_{t>1}(·) }$) of the noisy belief maps in a region around the image location z and improve its predictions by leveraging the fact that parts occur in consistent geometric configurations.
t = 2 时,分类器 ${ g_2 }$ 的输入如图,包括:
输入1: - 原始图片特征 ${ \mathbf{x}_z^2 }$;
输入2: - 卷积结果;先前 stage,对每个关节点的 beliefs,通过特征函数 ${ \psi }$ 计算的到的特征;
输入3: - 生成的 center 的 Gaussian 中心约束( Caffe 实现中给出)

t > 2 时,分类器 ${ g_{t>2} }$ 的输入,不再包括原始图片特征,而是替换为上一层的卷积结果,其它的输入与 t=2 相同. 也是三个输入.
特征函数 ${ \psi }$ 的作用是对先前 stage 不同关节点的空间 belief maps 编码.
CPM 没有显式函数来计算空间内容特征,而是,定义特征函数 ${ \psi }$ 作为分类器在先前 stage 的 beliefs 上的接受野(receptive field).
网络设计的原则是:在 stage t=2 网络的输出层的接受野是足够大的,以能学习不同关节点间的复杂和 long-range 关联性.
CPM 介绍了关于大接受野的好处,接受野对于精度的影响,如图: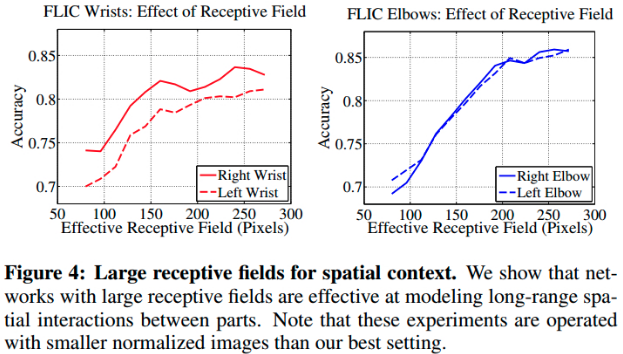
大接受野的两种方式:
[1] - 采用 pooling 操作, 会牺牲精度precision;
[2] - 增大 kernel size,会使参数量增加,训练时出现梯度消失的风险.
stage ${ t \geq 2 }$ 时,网络结构及对应的接受野如图:
stride-8 网络与 stride-4 的精度一样高,更容易得到大的接受野.
3. CPM 训练
CPM 每个 stage 都会输出关节点的预测结果,重复地输出每个关节点位置的 belief maps,以渐进精细化的方式估计关节点. 故,在每个 stage 输出后均计算 loss,作为中间监督 loss,避免梯度消失问题.
关节点 p 的 groundtruth belief map 记为:${ b_{*}^p (Y_p = z) }$,是通过在每个关节点 p 的 groundtruth 位置 (x, y) 放置 Gaussian 函数模板的方式得到,
如:
template<typename Dtype>
void DataTransformer<Dtype>::putGaussianMaps(Dtype* entry, Point2f center, int stride, int grid_x, int grid_y, float sigma){
//LOG(INFO) << "putGaussianMaps here we start for " << center.x << " " << center.y;
float start = stride/2.0 - 0.5; //0 if stride = 1, 0.5 if stride = 2, 1.5 if stride = 4, ...
for (int g_y = 0; g_y < grid_y; g_y++){
for (int g_x = 0; g_x < grid_x; g_x++){
float x = start + g_x * stride;
float y = start + g_y * stride;
float d2 = (x-center.x)*(x-center.x) + (y-center.y)*(y-center.y);
float exponent = d2 / 2.0 / sigma / sigma;
if(exponent > 4.6052){ //ln(100) = -ln(1%)
continue;
}
entry[g_y*grid_x + g_x] += exp(-exponent);
if(entry[g_y*grid_x + g_x] > 1)
entry[g_y*grid_x + g_x] = 1;
}
}
}每个 stage 的 Loss 函数:
$$ f_t = \sum_{p=1}^{P+1} \sum _{z \in \mathcal{Z}} ||b_t^p(z) - b _*^p(z)||_2^2 $$
最终计算的 loss:
$$ { \mathcal{F} = \sum_{t=1}^{T} f_t } $$
所有的 stage ${ t \geq 2 }$ ,共享图像特征 ${ \mathbf{x}^{\prime} }$. (Caffe 实现中 T=6.)
MPII 数据增强处理:
- 随机旋转图片 [-40, 40]
- 图片缩放 [0.7, 1.3]
- 水平翻转
4. 分析与实验
4.1 中间监督 loss 对于梯度消失的作用
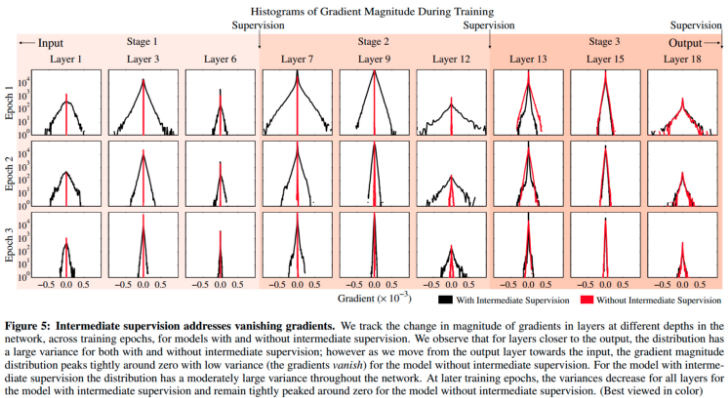
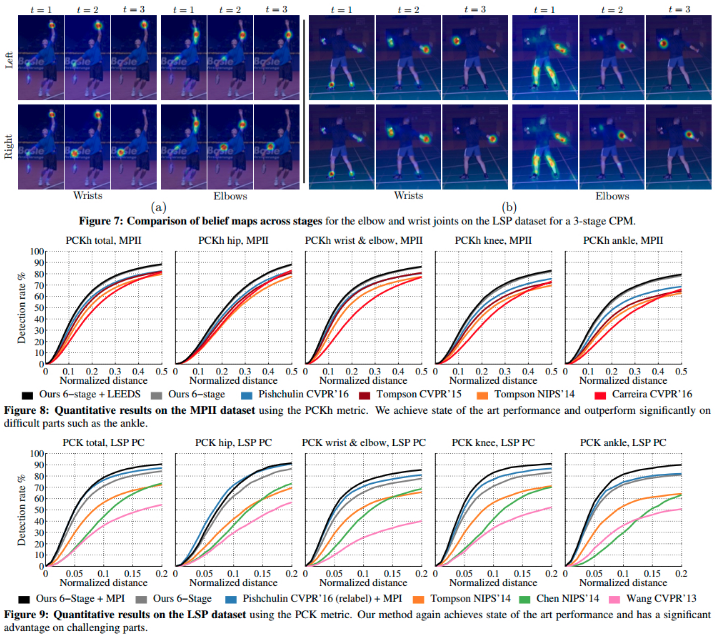
4.2. 实验结果

2 条评论
您好,在caffe官网中的网络结构和文章中网络结构相同(卷积层个数、卷积核大小),为什么在tensorflow版本中前面用到了VGG结构(卷积核等相关内容都不同),想请问这是用不同网络结构表示相同意思么?
Convolutional Pose Machines 第一个 stage 是改造了 vgg 的. 你这里是说 vgg网络结构的问题吗?