题目: Learning Feature Pyramids for Human Pose Estimation - ICCV 2017
作者: Wei Yang, Shuang Li, Wanli Ouyang, Hongsheng Li, Xiaogang Wang,
团队: CUHK, University of Sydney
Pyramid Residual Module(PRMs) —— 金字塔残差模块,来增强 DCNNs 的尺度不变性(invariance in scales);
- Hourglass 网络,conv-deconv 结构;
- 新的权重初始化方法,对 multi-branch 网络权重进行初始化.
目标:增强 DCNNs 对于尺度变化的鲁棒性;
方法:
- PRMs,学习卷积 filter,建立特征金字塔;
- 给定输入 features,PRMs 采用 multi-branch 网络基于不同采样率进行下采样,以获得不同尺度的特征;
- 然后,对不同尺度的特征学习卷积 filters;
- 再对 filtered 特征下采样到相同分辨率,并相加不同尺度特征.
在 Inference 时,Pyramids 类方法被广泛用于处理 scale 变化.
1. Stacked Hourglass Network
[[论文阅读 - Stacked Hourglass Networks for Human Pose Estimation]](http://www.aiuai.cn/aifarm169.html)
Hourglass 网络以 feed-forward 方式学习每个 scale 的信息.
首先,对 feature maps 下采样,bottom-up 处理;
然后,对 feature maps 上采样, top-down 处理;并结合 bottom layers 的更高分辨率特征;如 Figure 2(b).
重复多次 bottom-up 和 top-down,构建 stacked hourglass 网络,在每个 stack 的末尾添加中间监督.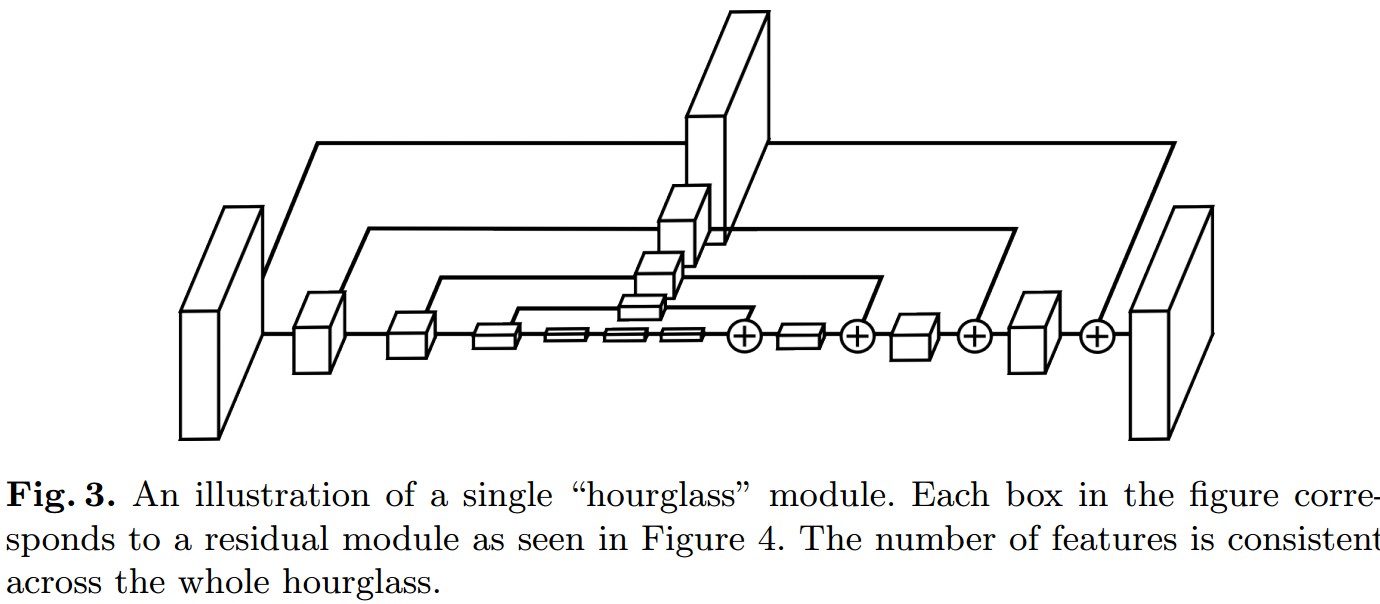
Figure 1. single "hourglass" 模块例示. 每一个 box 对应一个 residual 模块.
Residual Unit: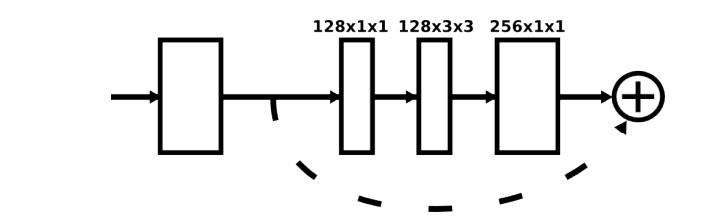
采用 residual unit 来构建 hourglass 网络 block. 但其只能捕捉一个尺度的视觉特征和语义.
Stacked Hourglass Network 训练的中间监督处理: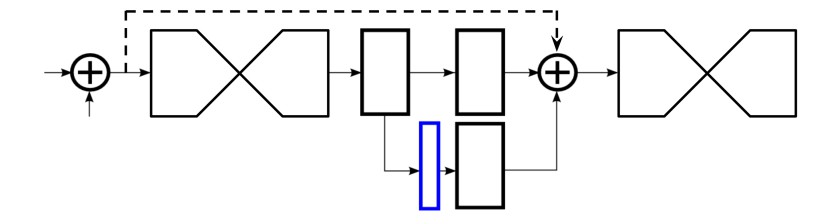
Figure 1.1 中间监督处理. 网络输出 heatmaps(蓝色框) ,其后添加训练 loss. 采用 1×1 卷积将 heatmaps 来匹配 intermediate 特征的 channels 数.
2 Pyramid Residual Modules(PRMs)
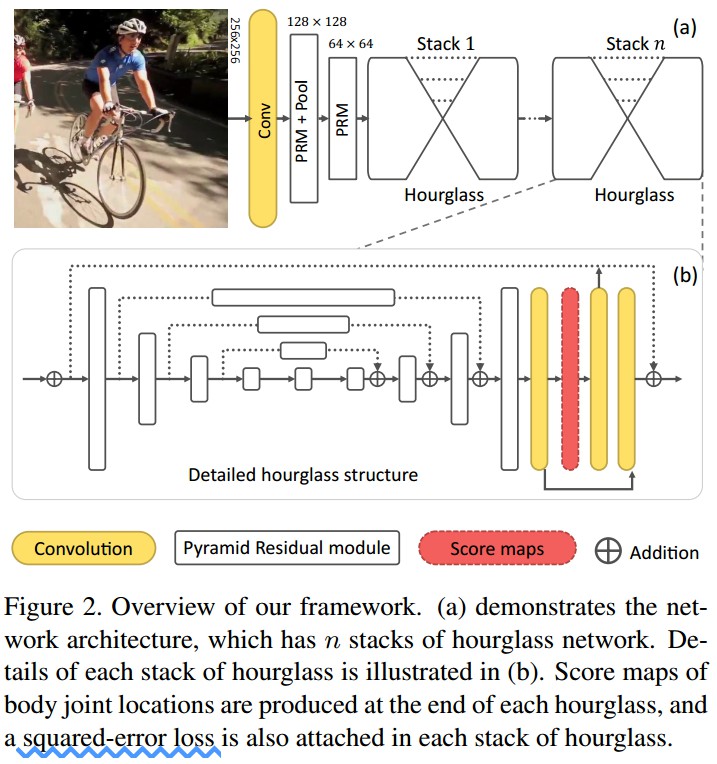
Figure 2. 框架. (a) 网络结构,有 n 个 stacks hourglass 网络. (b) 每个 hourglass stack 的细节. 每个 hourglass 的末尾产生 joint 位置的 scoremaps,并使用 squared-error loss.
PRM 学习输入 features 的不同分辨率的 filters.
记 ${ \mathbf{x}^{(l)} }$ 和 ${ \mathbf{W}^{(l)} }$ 分别为输入和第 ${ l }$ 层的 filter.
PRM 表示为:
${ \mathbf{x}^{(l+1)} = \mathbf{x}^{(l)} + \mathcal{P}(\mathbf{x}^{(l)}; \mathbf{W}^{(l)}) }$
其中,${ \mathcal{P}(\mathbf{x}^{(l)}; \mathbf{W}^{(l)}) }$ 为 feature pyramids,特征金字塔,其形式为:
${ \mathcal{P}(\mathbf{x}^{(l)}; \mathbf{W}^{(l)}) = g (\sum_{c=1}^{C} f_c(\mathbf{x}^{(l)}; \mathbf{w}_{f_c}^{(l)}); \mathbf{w}_{g}^{(l)}) + f_0(\mathbf{x}^{(l)}; \mathbf{w}_{f_0}^{(l)}) }$
C - pyramid 层的数量;
${ f_c(\cdot) }$ - 第 c 层 pyramid 层的变换;
${ \mathbf{W}^{(l)} = \lbrace \mathbf{w}_{f_c}^{(l)}, \mathbf{w}_{g}^{(l)} \rbrace_{c=0}^{C} }$ - 参数
${ f_c(\cdot) }$ 变换的输出相加,再采用 fliter ${ g(\cdot) }$ 卷积.
PRM 例示如 Figure 3. 每个 ${ f_c(\cdot) }$ 设计为 bottleneck 结构,以降低计算和空间复杂度. 例如, Figure 3 中,采用 1×1 卷积来降低特征维度;然后采用 3×3 卷积对下采样的输入特征集计算新特征;最后,将所有的新特征上采样到相同维度,并相加在一起.

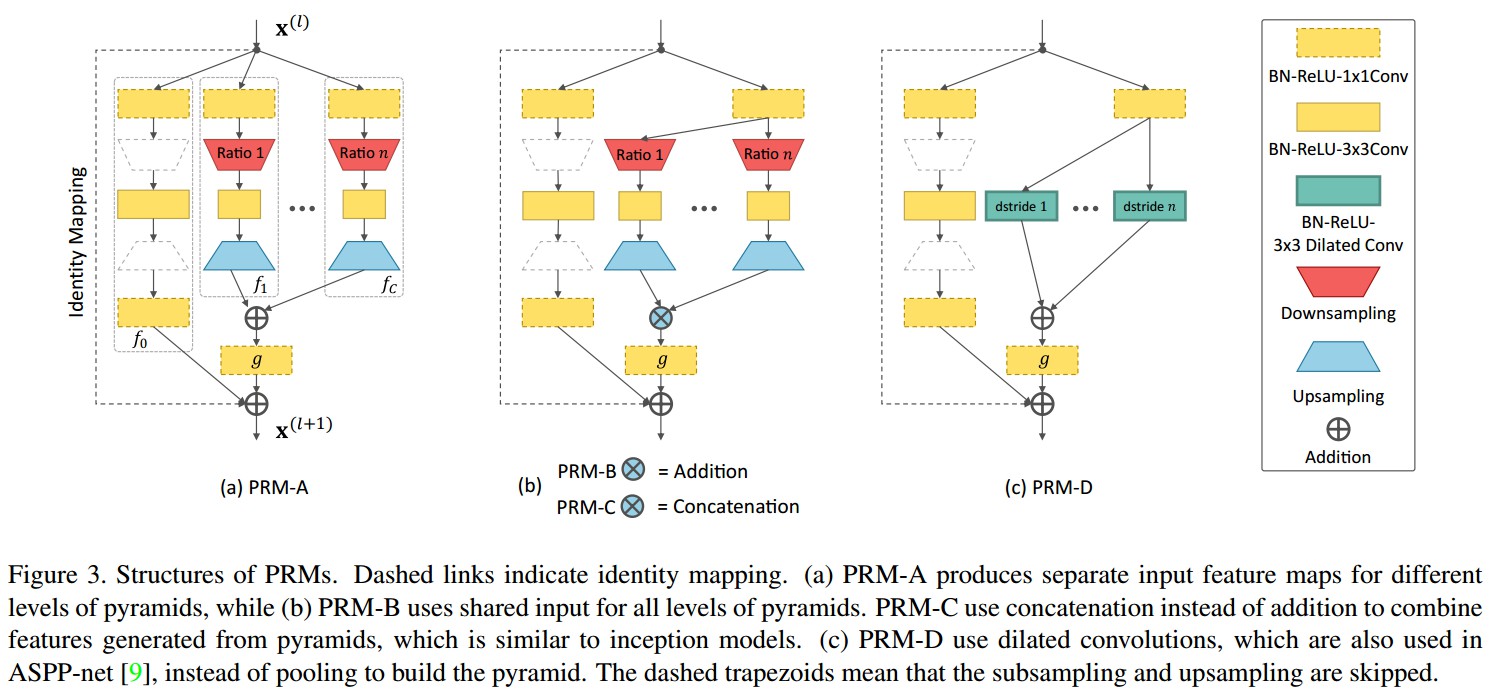
Figure 3. PRMs 结构. 虚线表示恒等映射(identity mapping). (a) PRM-A, 将输入 feature maps 从不同金字塔层独立分离;(b) PRM-B,对于所有的金字塔层采用共享输入;PRM-C 采用 concatenation 取代 addition 来组合从金字塔层得到的特征,类似于 inception 模型;(c) PRM-D,利用 dilated 卷积,类似于 ASPP-net,而不是采用 pooling 来构建金字塔. 虚线梯形表示跳过下采样和上采样.
2.1 生成输入特征的金字塔
DCNNs一般应用 max-pooling 和 average-pooling 来降低 feature maps 的分辨率,编码其平移不变性.
但,pooling 采用至少为 2 的整数因子,会导致 feature maps 的分辨率降低很快,很粗糙;不能很好的生成金字塔.
因此,这里采用 fractional max-pooling 来逼近传统图像金字塔的平滑和下采样处理,以得到不同分辨率 feature maps.
第 c 层金字塔的下采样率计算:
${ s_c = 2 ^{-M \frac{c}{C}}, c = 0,...,C, M \geq 1 }$
这里 ${ s_c \in [2^{-M}, 1] }$ 表示相对于输入 features 的分辨率.
例如,当 c=0,输出与其输入分辨率相同.
当 M=1, c=C,输出 map 的分辨率是其输入的一半.
实验中,设置 M=1, C=4,金字塔的最小尺度得到的 map 分辨率是其输入的一半.
2.2 讨论
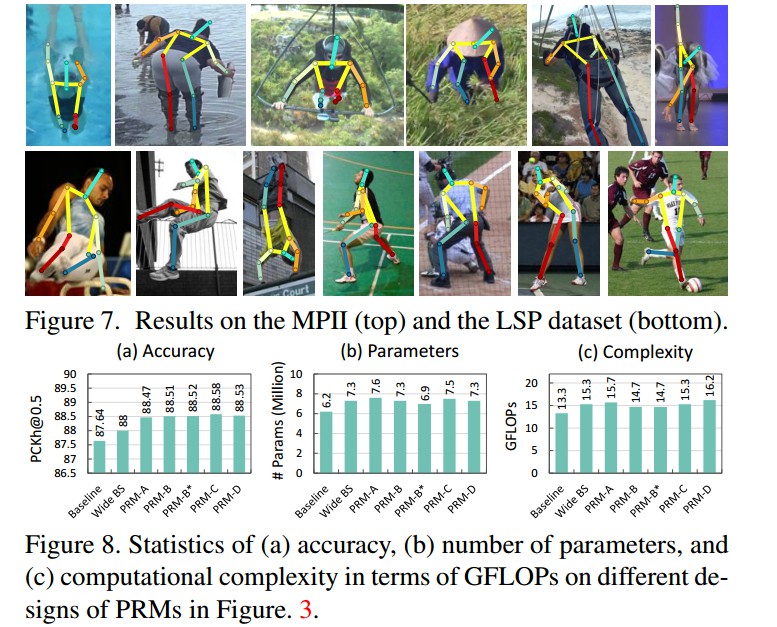
[1] - PRM 可以用于 CNN 结构的基础模块,如 stacked hourglass networks-姿态估计, Wide Residual Nets-图像分类,ResNeXt-图像分类.
[2] - Pyramid 结构的变形:
- 如 Figure 3(a-b),采用 max-pooling,convolution 和 upsampling 学习特征金字塔;
- 如 Figure 3(c),PRM-D,采用 dilated convolution 来计算特征金字塔;
- 如 Figure 3(b),PRM-C,金字塔不同层次特征除了采用相加(summation)处理,还可以采用 concatenation;
- Figure 3(b),PRM-B 具有相当的表现,但参数相对较少,计算复杂度较低. 【提供的[[Code-Torch]](https://github.com/bearpaw/PyraNet) 应该是基于 PRM-B 模型.】
[3] - 权重共享:
传统方法,如 HOG,对不同层次的图像金字塔学习,以生成特征金字塔. 处理过程对应于共享金字塔 ${ f_c(\cdot) }$ 不同层次的权重 ${ W_{f_c}^{(l)} }$.
权重共享有效的减少了参数量.
[4] - 复杂度
stacked hourglass network 的 residual unit 的输入和输出是 256-d,在residual unit 降低到 128-d.
这里采用该 residual unit 对原始尺度分支处理.
由于小分辨率的特征包含相对较少的信息,故这里对小尺度分支采用小的特征 channel.
例如,给定 PRM,有 5 个分支,对于小尺度分支有 28 个 feature channel.
参数和 GFLOPs 的复杂度大约只增加了 10%.
3 网络训练和推断
3.1 训练
[1] - 采用 score maps 来表示关节点位置:
记 groundtruth 位置为 ${ \mathbf{z} = \lbrace \mathbf{z} _{k=1}^{K} \rbrace }$
${ \mathbf{z}_k = (x_k, y_k) }$ 为图像中第 k 个关节点的位置.
groundtruth score map ${ \mathbf{S}_k }$ 是均值 ${ \mathbf{z}_k }$ 和方差 ${ \Sigma }$ 的 Gaussian 分布:
${ \mathbf{S}_k(\mathbf{p}) \sim \mathcal{N} (\mathbf{z}_k, \Sigma) }$
${ \mathbf{p} \in R^2 }$ -关节点位置;
${ \Sigma }$ - 单位矩阵 identity matrix ${ \mathbf{I} }$ .
每个 hourglass network 预测 K 个关节点的 score maps,${ \hat{\mathbf{S}} = [\hat{\mathbf{S}}_k] _{k=1}^{K} }|$
[2] - Loss 函数:
每个 hourglass network stack 的末尾添加 squared error loss:
${ \mathcal{L} = \frac{1}{2} \sum_{n=1}^{N} \sum _{k=1}^{K} ||\mathbf{S}_k- \hat{\mathbf{S}}_k||^2 }$
N - 样本数
3.2 推断
最后一个 hourglass stack 预测的 score maps,取 scoremap 的最大值位置,作为关节点位置 ${ \hat{\mathbf{z}}_k }$.
${ \hat{\mathbf{z}}_k = arg max _{\mathbf{p}} \hat{\mathbf{S}}_k(\mathbf{p}), k=1,...,K }$
3.3 网络初始化方法
主要是提出 multi-branch 网络初始化方法.
对于深度网络的训练,初始化很重要,尤其是像素级的 dense prediction. 在 dense prediction 中,由于全卷积网络需要较多的显存消耗,只能采用小 minibatch.
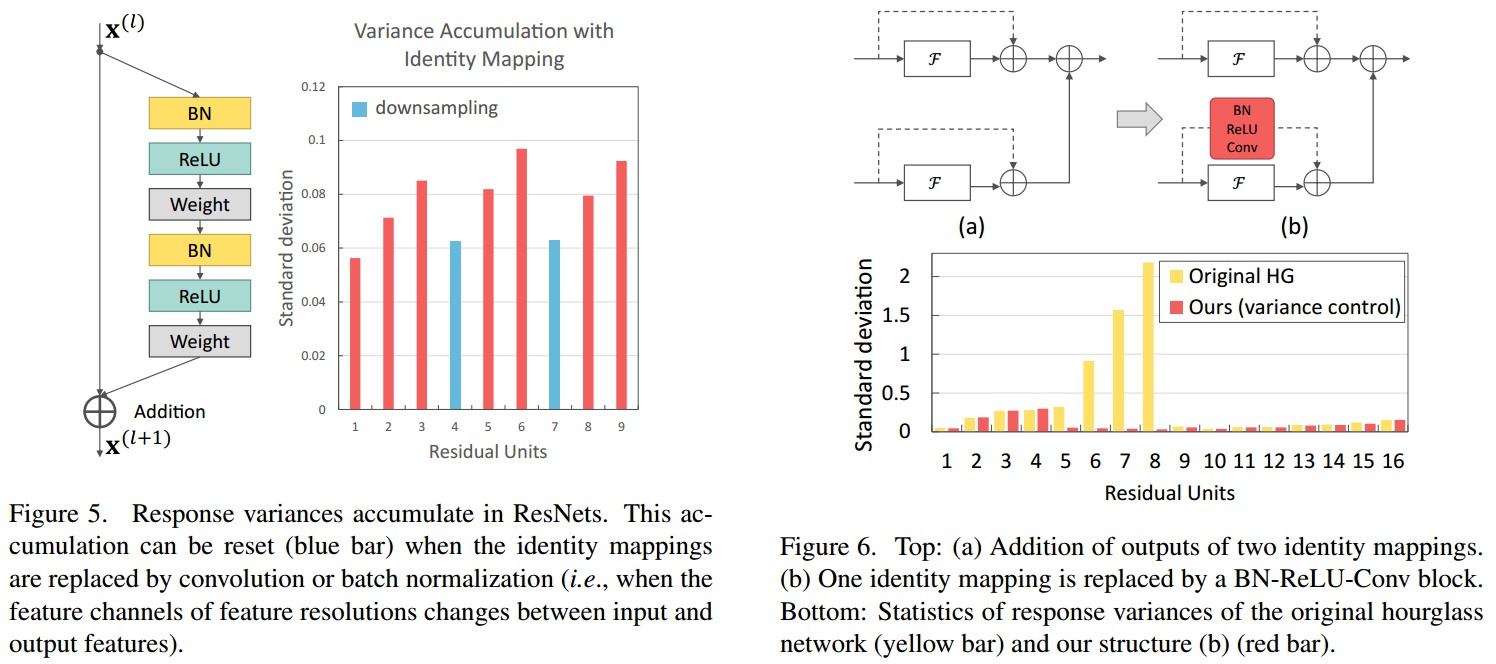
3.4 Output Variance Accumulation 输出方差的累积问题
- 恒等映射 Identity mapping 会导致随着网络的加深,响应的变化逐渐增加,使得优化难度增大.
- 当两个 residual units 的输出相加时,这里采用 batch_normalization 和 ReLU 后接 $1×1$ 的卷积来代替恒等映射. 如 Figure 6.
4 实现和结果
4.1 实现细节
- 输入图片根据标注的人体位置和 scale ,从 resized 图片中裁剪尺寸 256×256.
- LSP test 集:直接采用图像中心作为人体位置,根据图片尺寸估计人体 scale;
- 训练数据增广:scaling,rotation,flipping,color noise等;
- 采用 Torch 训练
- 网络优化方法为 RMSProp,4 Titan X GPUs,mini-batch size 为 16,每张 GPU 4 张图片,200 epoches.
- 初始化学习率 7 × 10^{-4},在 150 epoch 和 170 epoch 各减少 10×.
- Testing 对 6-scale 图像 Pyramids 并 flipping 进行.
4.2 Results
网络初始化方法对比: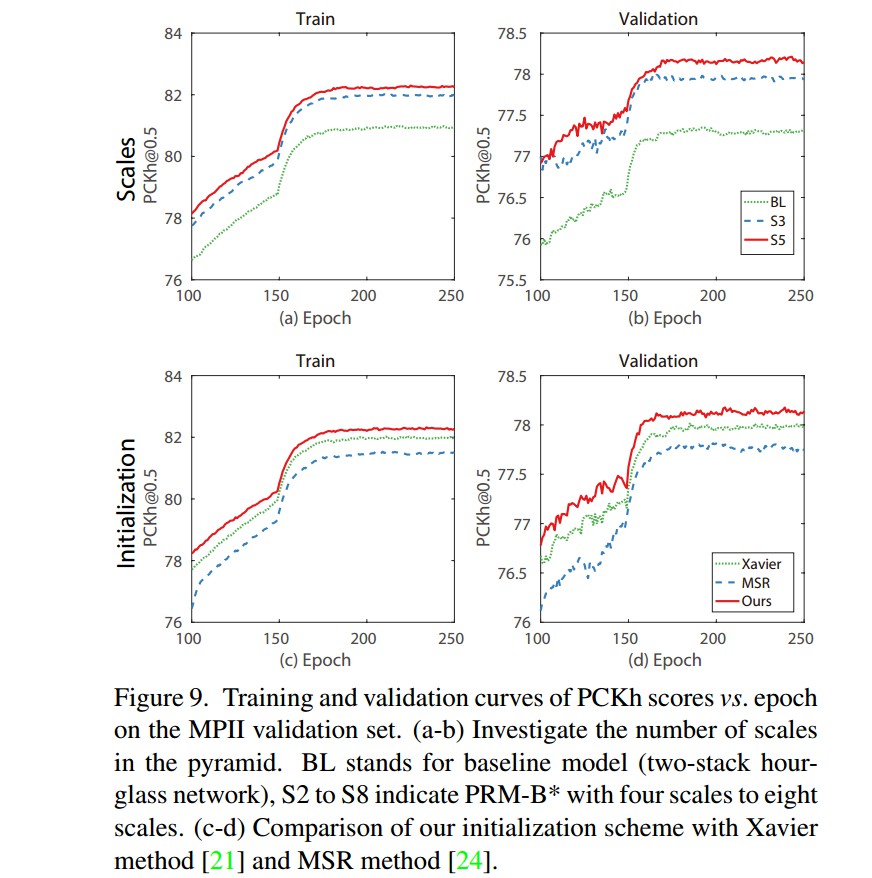
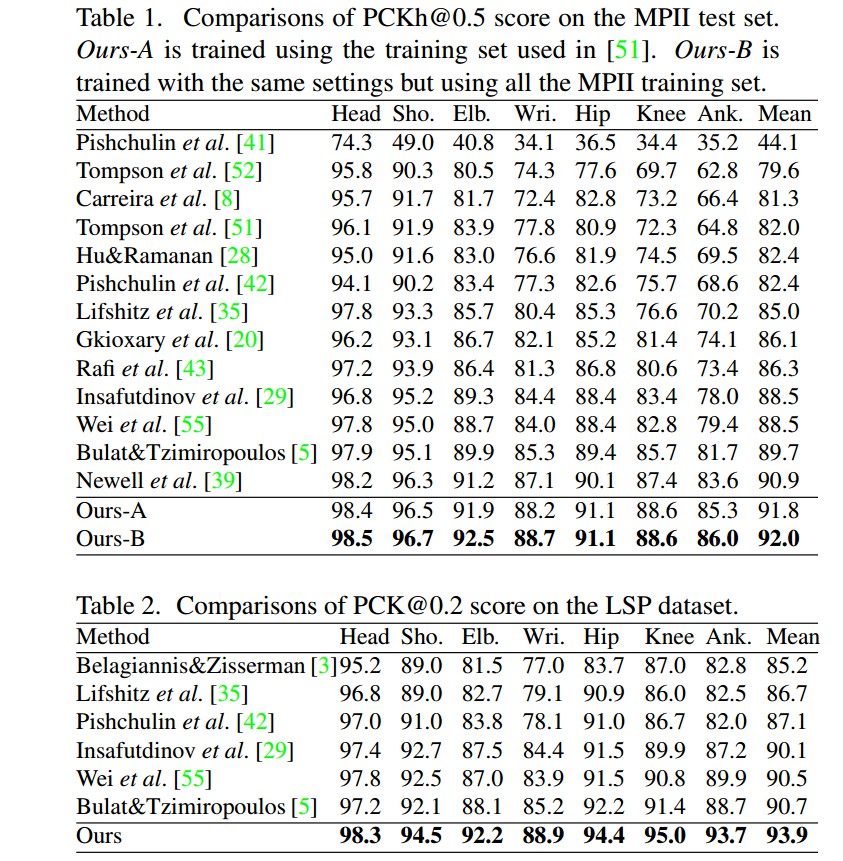
MPII 和 LSP 数据集上不同方法对比: