原文:Progressing with GANs - 2019.02.19
作者:Yuan Ma
此文主要是采用 TF 和 TFHub 来介绍 ProgressiveGAN(ProGAN,或 PCGAN).
ProGAN 是 ICLR 2018 提出的,并用于生成全高清(full-HD)照片逼真的图像,或平滑地组合任何先前生成的图像.
ProGAN 主要的四个创新点:
[1] - 渐进式增长和高分辨率层的平滑衰减(progressively growing and smoothly fading in higher resolution layers)
[2] - 小批量标准偏差(minibatch standard deviation)
[3] - 均衡学习率(equalized learning rate)
[4] - 逐像素特征归一化(pixel-wise feature normalization)
1. 隐空间插值(Latent space interpolation)

2. ProGAN 的四个创新点
2.1. 渐进式增长和高分辨率层的平滑衰减
progressively growing and smoothly fading in higher resolution layers.
技术角度来说,训练时,往往是从低分辨率卷积层到更多高分辨率层进行的. 其原因是,在引入更高分辨率前,首先训练早期网络层,其很难导航损失函数空间(The reason for it is to train the early layers first before introducing a higher resolution, where it is harder to navigate the loss space.)
故,这里从简单的事情开始,如,先采用 4x4 训练几次,再到复杂的事情,如,采用 1024x1024 训练几个 epochs:
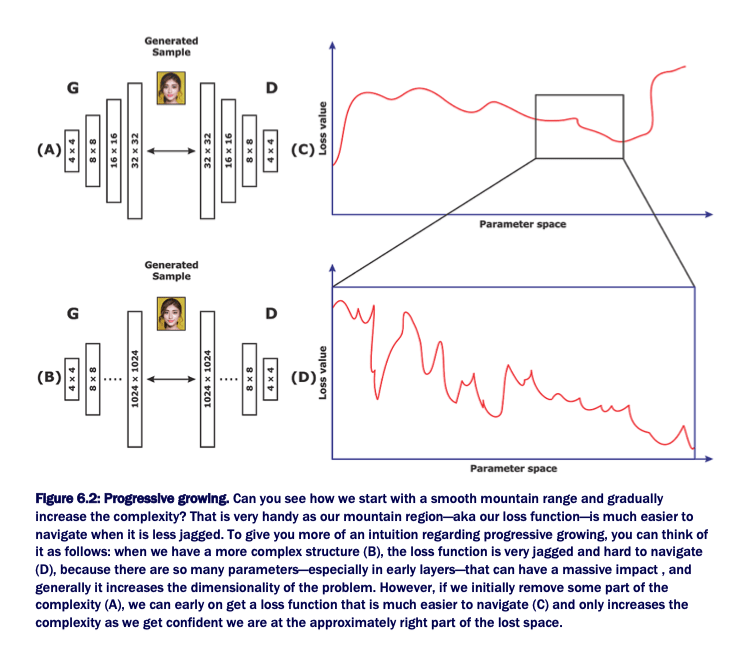
在这种情况下,问题是,即使一次引入一层,如从 4x4 到 8x8,其仍然会给训练系统带来巨大的冲击. ProGAN 所采用的处理是,在这些网络层中平滑衰减,如下图:
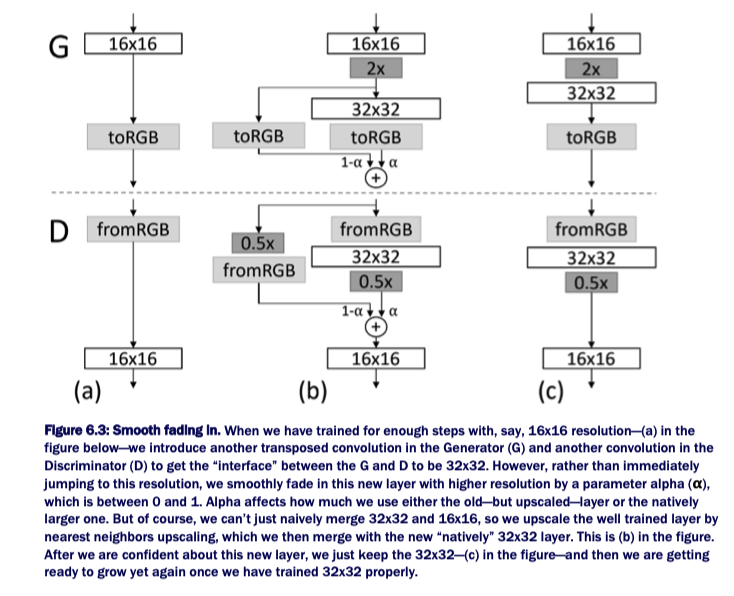
其TF 实现如:
import tensorflow as tf
import keras as K
#渐进式平滑(progressive smoothing)类似于:
def upscale_layer(layer, upscale_factor):
'''
Upscales layer (tensor) by the factor (int) where
the tensor is [group, height, width, channels]
'''
height = layer.get_shape()[1]
width = layer.get_shape()[2]
size = (scale * height, scale * width)
upscaled_layer = tf.image.resize_nearest_neighbor(layer, size)
return upscaled_layer
def smoothly_merge_last_layer(list_of_layers, alpha):
'''
Smoothly merges in a layer based on a threshold value alpha.
This function assumes: that all layers are already in RGB.
This is the function for the Generator.
:list_of_layers : items should be tensors ordered by size
:alpha : float \in (0, 1)
'''
# Hint!
# If you are using pure Tensorflow rather than keras, always remember scope
last_fully_trained_layer = list_of_layers[2]
# now we have the originally trained layer
last_layer_upscaled = upscale_layer(last_fully_trained_layer, 2)
# this is the newly added layer not yet fully trained
larger_native_layer = list_of_layers[-1]
# This makes sure we can run the merging code
assert larger_native_layer.get_shape() == last_layer_upscaled.get_shape()
# This code block should take advantage of broadcasting
new_layer = (1-alpha) * upscaled_layer + larger_native_layer * alpha
return new_layer2.2. 小批量标准偏差
minibatch standard devision.
要进行的处理有:
[1] - 首先,计算 batch 内所有图像的标准偏差,以得到每个通道的每个像素的标准偏差所构成的单张图像.
[2] - 然后,计算所有通道的标准偏差,以得到单个特征图(feature map)或特定像素的标准偏差矩阵.
[3] - 最后,计算所有像素的标准偏差,以得到单个标量值.
实现如:
def minibatch_std_layer(layer, group_size=4):
'''
Will calculate minibatch standard deviation for a layer.
Will do so under a pre-specified tf-scope with Keras.
Assumes layer is a float32 dat type. Else needs validation/casting.
Note: there is a more efficient way to do this in Keras, but just for
clarity and alignment with major implementations (for understanding)
this wad done more explicitly. Try thsi as an exercise.
'''
# Hint!
# If you are using pure Tensorflow rather than Keras, always remember scope
# minibatch group must be divisible by (or <=) group_size
group_size = K.backend.minimum(group_size, tf.shape(layer)[0])
# just getting some shape information so that we can use
# them as shorthand as well as to ensure defaults
s = list(K.init_shape(int))
s[0] = tf.shape(intput)[0]
# Reshaping so that we operate on the level of hte minibatch
# in this code we assume the layer to be:
# [Group (G), Minibatch (M), Width (W), Height (H), channel (C)]
# but be careful different impelmentations use the Theano specific
# order instead
minibatch = K.backend.reshape(layer, (group_size, -1, s[1], s[2], s[3]))
# Center the mean over the group [M, W, H, C]
minibatch -= tf.reduce_mean(minibatch, axis=0, keepdims=True)
# Calculate the variance of the group [M, W, H, C]
minibatch = tf.reduce_mean(K.backend.square(minibatch), axis = 0)
# Calculate the standard deviation over the group [M, W, H, C]
minibatch = K.backend.square(minibatch + 1e8)
# Take average over feature maps and pixels [M, 1, 1, 1]
minibatch = tf.reduce_mean(minibatch, axis=[1,2,4], keepdims=True)
# Add as a layer for each group and pixels
minibatch = K.backend.tile(minibatch, [group_size, 1, s[2], s[3]])
# Append as a new feature map
return K.backend.concatenate([layer, minibatch], axis=1)2.3. 均衡化学习率
Equalized learning rate.
均衡化学习率可能是一种并不是每个人都清楚的深度学习黑技术.
此外,关于均衡化学习率还存在很多细微差别,其需要对 RMSProp 和 Adam 优化器的实现以及权重初始化有充分的了解.
def equalize_learning_rate(shape, gain, fan_in=None):
'''
This adjusts the weights of every layer by the constant from He's initializer so
that we adjust for the variance in the dynamic range in different features
shape : shape of tensor (layer): [kernel, kernel, height, feature_maps]
gain : typically sqrt(2)
fan_in : adjustment for the number of incoming connections as per Xavier's / He's initialization
'''
# Default value is product of all the shape dimension minus the feature maps dim -- this gives us the number of incoming connections per neuron
if fan_in is None: fan_in = np.prod(shape[:-1])
# This uses He's initialization constant
std = gain / K.sqrt(fan_in)
# creates a constant out of the adjustment
wscale = K.constant(std, name='wscale', dtype=np.float32)
# gets values for weights and then uses broadcasting to apply the adjustment
adjusted_weights = K.get_value('layer', shape=shape,
initializer=tf.initializers.random_normal()) * wscale
return adjusted_weights2.4. 逐像素特征归一化
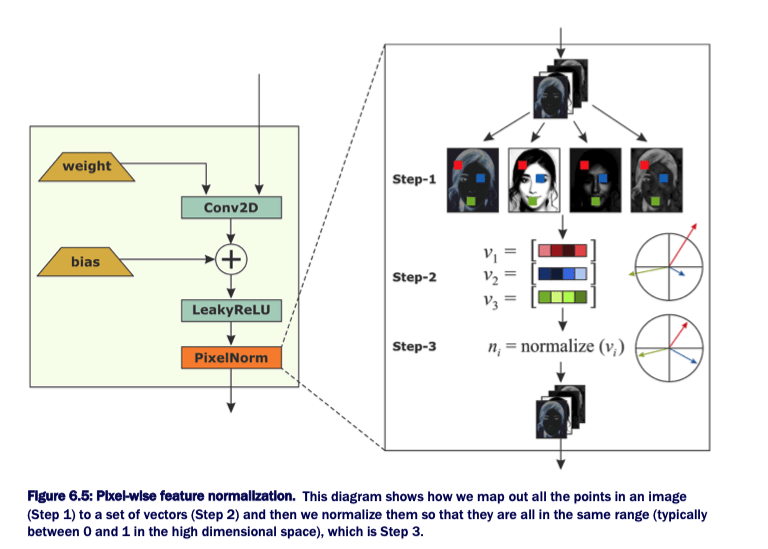
Pixel-wise feature normalization.
至今,大部分网络都采用了某型形式的归一化,一般为 bathc normalization 或其virtual version版本.

像素归一化仅对每层激活值进行处理,在其作为输入送到下一层之前.

其数学公式为:
$$ n_{(x, y)} = \frac{a_{(x, y)}}{\sqrt{\frac{1}{N} \sum_{j=0}^{N-1} (a_{x, y}^j)^2 + \epsilon}} $$
最后要注意的是,像素归一化仅用于 Generator,因为激活值爆炸问题只有当两个网络都参与时,才会导致军备竞赛.
def pixelwise_feat_norm(inputs, **kwargs):
'''
Uses pixelwise feature normalization as proposed by Krizhevsky et at. 2012.
Returns the input normalized
inputs : Keras / TF Layers
'''
normalization_constant = K.backend.sqrt(K.backend.mean(input**2, axis=-1, keepdims=True) + 1.0e-8)
return inputs / normalization_constant