题目: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
作者: Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam
团队: Google Inc.
空间金字塔池化模块(spatial pyramid pooling,SPP) 和 编码-解码结构(encode-decoder) 用于语义分割的深度网络结构. SPP 利用对多种比例(rates)和多种有效接受野(fields of view)的不同分辨率特征处理,来挖掘多尺度的上下文内容信息. 解编码结构逐步重构空间信息来更好的捕捉物体边界.
DeepLabv3+ 对 DeepLabV3 添加了一个简单有效的解码模块,提升了分割效果,尤其是对物体边界的分割. 基于提出的编码-解码结构,可以任意通过控制 atrous convolution 来输出编码特征的分辨率,来平衡精度和运行时间(已有编码-解码结构不具有该能力.).
DeepLabV3+ 进一步利用 Xception 模块,将深度可分卷积结构(depthwise separable convolution) 用到带孔空间金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)模块和解码模块中,得到更快速有效的 编码-解码网络.
DeepLabV3 采用多个不同比例的并行 atrous conv 来挖掘不同尺度的上下文信息,记为 ASPP.
PSPNet 对不同尺度的网络进行池化处理,处理多尺度的上下文内容信息.
深度网络最后层输出的 feature map 虽然能够编码丰富的语义信息,但由于 pooling 和不同步长的卷积处理,会导致物体边界信息丢失. 且,计算 GPU 显存占用较多.
编码-解码模型编码计算速度快,且解码能够逐步重构更好的物体边界.
DeepLabV3 的输出能够编码丰富的语义信息,其利用 atrous 卷积来控制编码输出的特征分辨率,取决于计算资源.
DeepLabV3+ 新添加了解码模块来重构精确的图像物体边界,如 Fig 1.
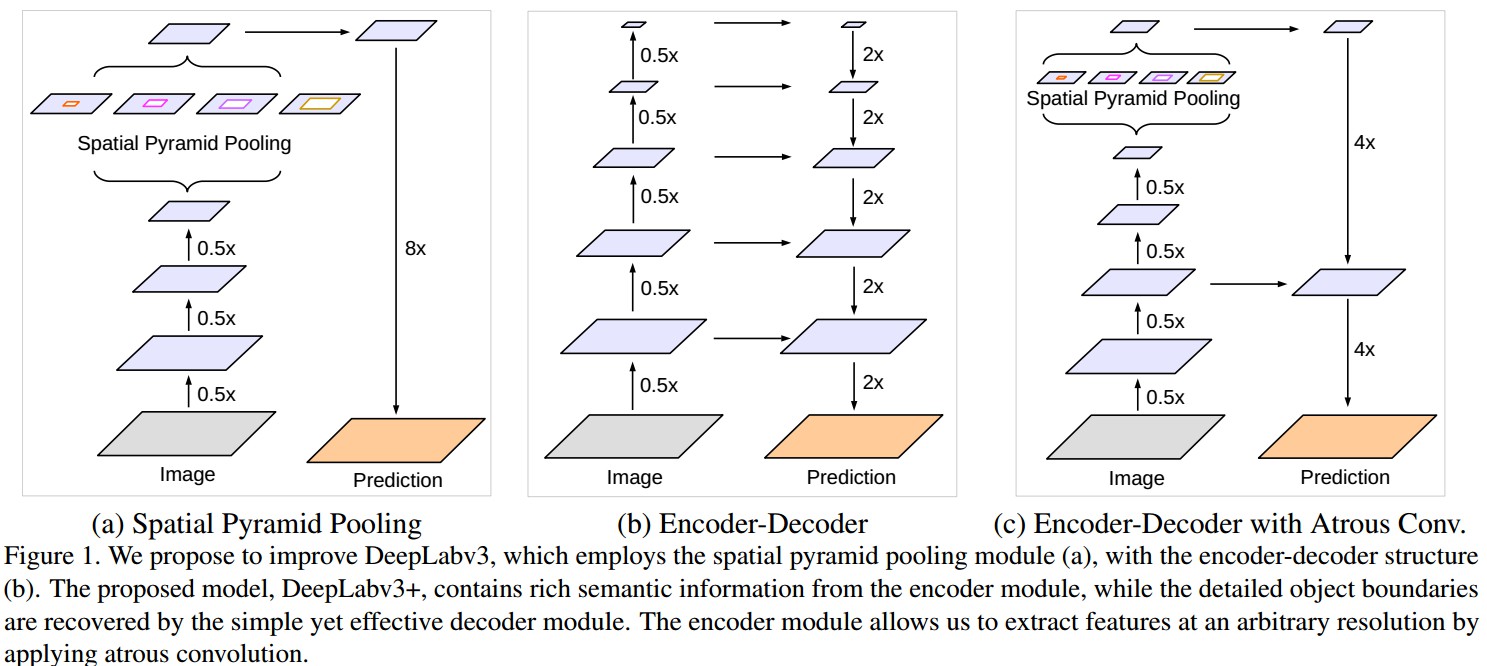
Fig 1. SPP、Encoder-Decoder 和 Encoder-Decoder with Atrous Conv(DeepLabV3+ ) 网络结构对比.
深度可分离卷积结构(depthwise separable convolution) 和 group convolution 能够有效降低计算量与参数量,同时保持模型表现.
1. Encoder-Decoder with Atrous Convolution
1.1 Atrous Convolution
Atrous Convolution 扩展了标准的网络卷积操作,其通过调整卷积 filter 的接受野来捕捉多尺度的上下文内容信息,输出不同分辨率的特征.
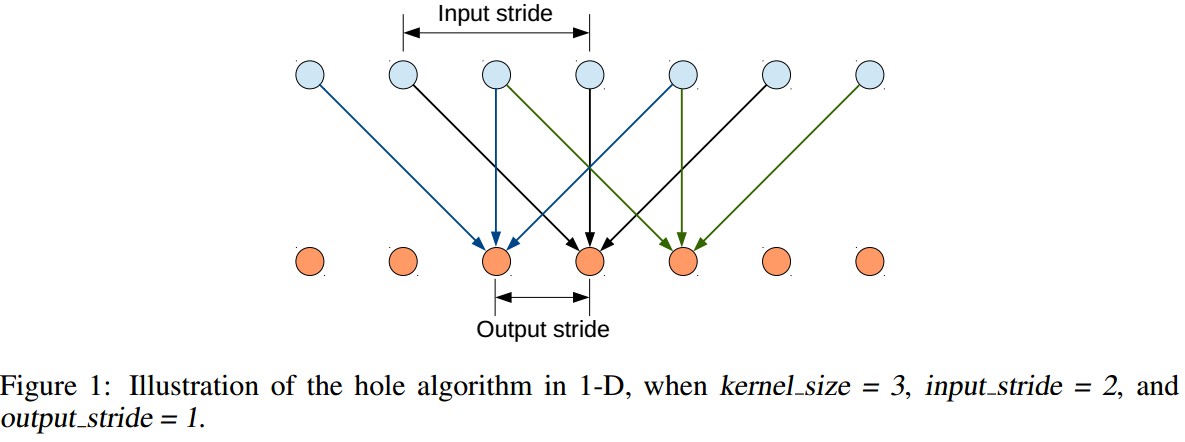
以 2D 信号为例,对于输出 feature map ${ y }$ 的每个位置 ${ i }$,卷积 filter ${ w }$,输入 feature map ${ x }$ ,atrous 卷积计算为:
${ y[i] = \sum_{k} x[i + r \cdot k] w[k] }$ (1)
atrous rate ${ r }$ 是对输入信号的采样步长.
标准的卷积操作等价于 ${ r = 1 }$.
1.2 Depthwise separable convolution
深度可分卷积操作,将标准卷积分解为一个 depthwise conv,depthwise conv 后接 pointwise conv(如,1×1 conv),有效的降低计算复杂度.
depthwise conv 对每一个输入通道(channel) 分别进行 spatial conv;
pointwise conv 用于合并 depthwise conv 的输出.
TensorFlow 实现的 depthwise separable conv 已经在 depthwise conv 中支持 atrous conv.
1.3 DeepLabv3 as encoder
DeepLabV3 采用 atrous conv 来提取不同分辨率的特征.
这里,记,输入图片空间分辨率与最终输出分辨率(在 global pooling 或 FCN 层之前的输出 feature map)的比率为输出步长(output_stride).
图像分类 - 最终输出 feature map 的空间分辨率一般是输入图片的 1/32,即 output_stride=32.
语义分割 - 一般为 output_stride=16 或 output_stride=8.
DeepLabV3 采用 ASPP 模块,采用不同比率的 atrous conv 来得到不同尺度的卷积特征.
DeepLabV3+ 采用DeepLabV3 输出的 feature map 作为提出的 编码-解码结构的编码输出. 编码输出 feature map 是 256 channels 的,包含丰富的语义信息.
另外,还可以根据计算资源,通过 atrous conv 来提取任意分辨率的 feature.
1.4 DeepLabV3+ Proposed decoder
DeepLabV3 输出的编码特征,一般 output_stride=16.
DeepLabV3 中的对 feature map 采用因子为 16 的双线性插值(bilinearly upsampled)处理,可以看做是 naive 的解码模块,但不足以重构物体分割细节.
DeepLabV3+ 提出的解码模块,如图:
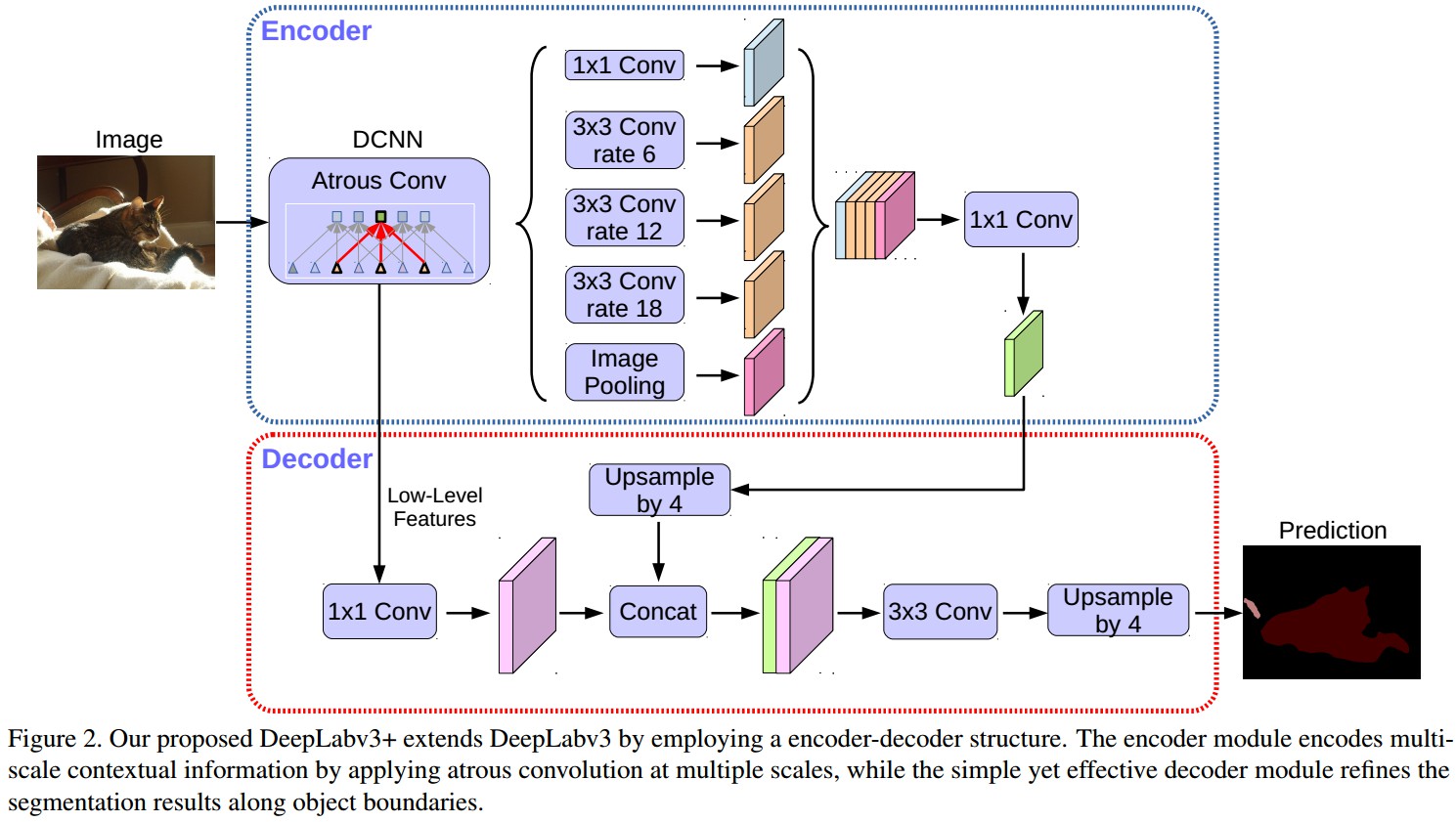
DeepLabV3++ 解码模块中,首先将编码特征采用因子 4 的双线性上采样;然后,连接(Concatenation)从主干网络所输出的对应的具有相同空间分辨率的 low-level 特征(如,ResNet-101 中 Conv2).
由于对应的 low-level 特征往往包含较多的 channels(如256, 512),可能会超过输出编码特征(这里输出 256 channels) 导致训练困难,故在连接(Concatenation)操作前,采用 1×1 卷积对 low-level 特征进行操作,以减少 channels 数.
连接(Concatenation) 处理后,采用 3×3 卷积和因子 4 的双线性上采样来改善特征.
output_stride = 16 的编码模块输出,取得了速率和精度的平衡.
output_stride = 8 的编码模块输出,精度更高,但计算复杂度增加.
2. Modified Aligned Xception
Xception 模型 已经在图像分类上取得了快速计算.
MSRA 提出的改进版本 Aligned Xception 在目标检测中实现了快速计算.
这里,基于 Aligned Xception 进行一些改进:
- 相同深度 Xception,除了没有修改 entry flow network 结构,以快速计算和内存效率.
- 采用 depthwise separable conv 来替换所有的 max-pooling 操作,以利用 atrous separable conv 来提取任意分辨率的 feature maps.
- 在每个 3×3 depthwise conv 后,添加 BN 和 ReLU,类似于 MobileNet.
改进的 Xception 结构如图:

3. Experiments
- ResNet-101/Modified Aligned Xception - atrous conv 提取 feature maps.
- TensorFlow
- PASCAL VOC 2012 - 20 object classes 和 1 background class.
- crop_size = 513 × 513,initial_learning_rate=0.007,poly,fine-tune.
- output_stride = 16,随机裁剪数据增强.
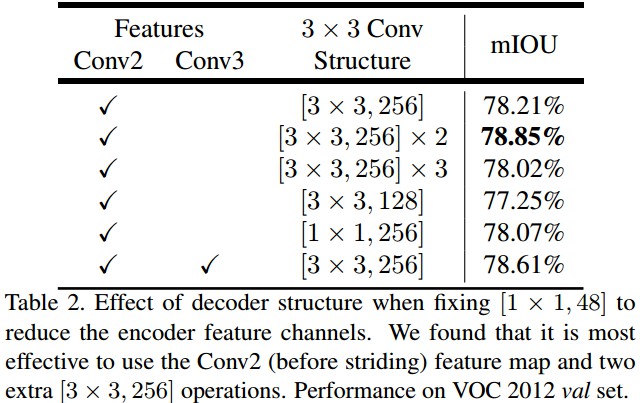
3.1 Decoder Design Choices

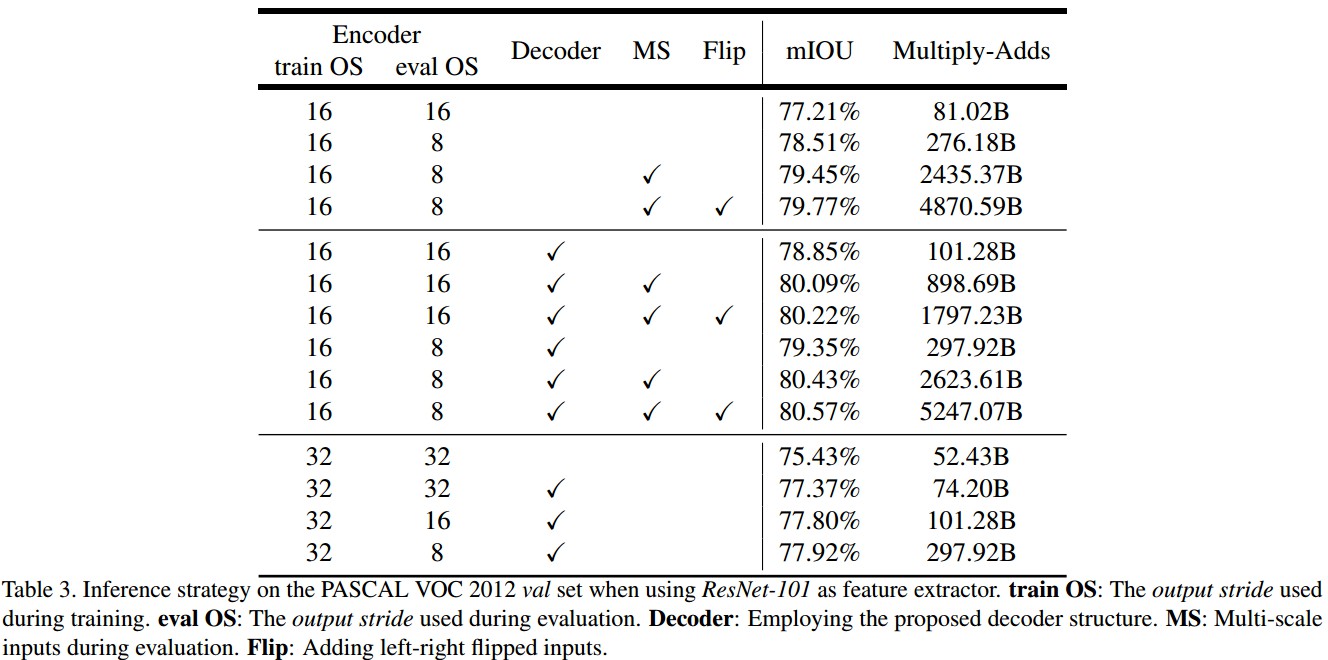
3.2 ResNet-101 as Network Backbone
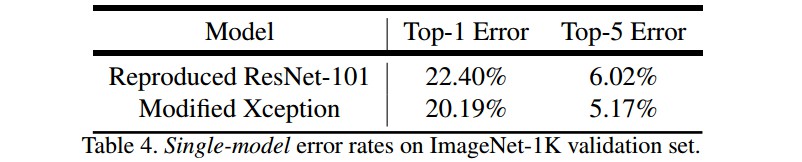
3.3 Xception as Network Backbone

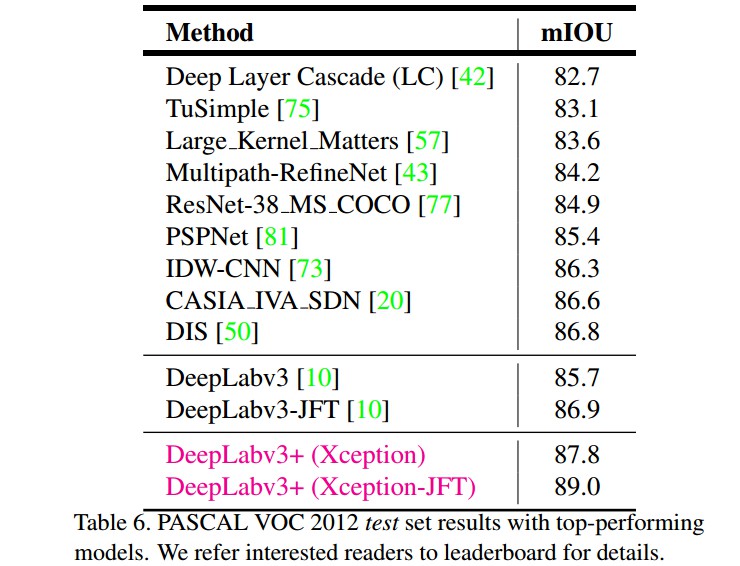

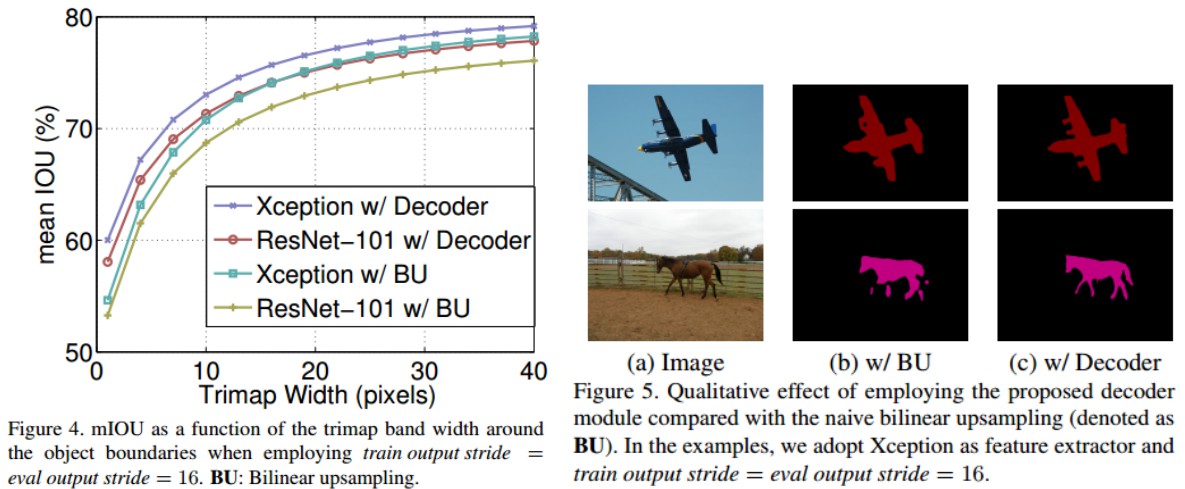
3.4 Improvement along Object Boundaries
Releated
[1] - 论文阅读 - (Deeplab-V3)Rethinking Atrous Convolution for Semantic Image Segmentation
[2] - 论文阅读 - Semantic Image Segmentation With Deep Convolutional Nets and Fully Connected CRFs
[3] - 论文阅读 - Pyramid Scene Parsing Network
[4] - 论文阅读 - Multi-scale Context Aggregation by Dilated Convolutions
2 条评论
你好,感觉文章写得很好,请问可以转载吗?
交流学习,注明下就可以了.