论文:Deep High-Resolution Representation Learning for Human Pose Estimation - CVPR2019
作者:Ke Sun1, Bin Xiao, Dong Liu, Jingdong Wang
团队:University of Science and Technology of China, Microsoft Research Asia
1. 概述
在人体姿态估计问题中,学习可靠的高质量分辨率的特征图(heatmaps),是比较重要的. 现有很多方法往往是根据由高分辨率到低分辨率的网络(high-to-low resolution network)产生的低分辨率特征图,来重构高分辨率的特征图表示. 如:
[1] - Hourglass 网络结构:

[2] - Cascaded pyramid networks 网络结构:

[3] - SimpleBaseline 网络结构(低分辨率到高分辨率的处理采用的是 transposed conv.):

[4] 结合 dilated convolutions 的网络结构(注: reg. = regular convolution, dilated = dilated convolution, trans. = transposed convolution, strided = strided convolution, concat. = concatenation):

上面这些方法中,
- [1] 中,高分辨率到低分辨率的处理与低分辨率到高分辨率的处理过程是对称的.
- [2], [3] 和 [4] 中,高分辨率到低分辨率的处理,可以看作是分类网络的一部分(如 ResNet 和 VGGNet),比较重(heavy); 而低分辨率到高分辨率的处理是比较轻量的(light).
- [1] 和 [2] 中,高分辨率到低分辨率处理和低分辨率到高分辨率处理的相同分辨率层间的跳跃链接(skip-connections)(虚线连接),主要用于融合低层特征和高层特征.
- [2] 中,右边的部分,refinenet,通过卷积操作,融合了低层特征和高层特征.
而,论文提出的方法是,首先采用高分辨率的子网络作为第一阶段;然后逐渐添加高分辨率到低分辨率的子网络,得到多个阶段的输出;最后,并行的连接多分辨率子网络的输出. 其进行了多次多尺度融合(multi-scale fusions),因此,使得每一个高分辨率到低分辨率的特征图表示,都可以一次又一次地从其它并行表示分支接收信息,从而得到信息更丰富的高分辨率表示. 最终,网络输出的关键点heatmap 更精确,空间分辨率精度更高.
论文提出的网络结构HRNet(High-Resolution Net),如图:

图1. HRNet 图示. 包含多个并行的高分辨率到低分辨率的子网络,实现跨多分辨率子网络的信息交换(即:多尺度融合). 图中水平方向和垂直方向分别表示网络的深度和特征图的尺度.
HRNet 能够在网络整个过程中保持特征的高分辨率表示.
HRNet 的优势之处:
[1] - HRNet 并行地连接各高分辨率到低分辨率子网络的输出,而不是被较多采用的串行连接. 因此,HRNet 能够一直保持高分辨率表示,而不是采用低分辨率到高分辨率的处理来重构高分辨率表示,故 HRNet 的 heatmap 具有更高的空间精确度.
[2] - 特征融合一般采用的是,底层特征表示与高层特征表示的聚合融合;而,HRNet 采用的重复性的多尺度融合,基于相同网络深度和相似特征层的低分辨率表示的辅助,来提升高分辨率的表示能力,以使得高分辨率的表示更有助于姿态估计.
2. HRNet
人体姿态估计,也叫做关键点检测,旨在检测 $W \times H \times 3$ 的图片 $\mathbf{I}$ 中 $K$ 个关键点或人体部分的位置(如,elbow, wrist 等). 一般是将问题转换为,估计 $K$ 个 $W' \times H'$ 的 heatmaps,$\lbrace \mathbf{H}_1, \mathbf{H}_2, ..., \mathbf{H}_{K} \rbrace$ 的问题,其中,heatmap $\mathbf{H}_k$ 表示第 $k$ 个人体关键点的位置置信(location confidence).
HRNet 采用了流行的技术方案,采用 CNN 网络来预测人体关键点,其主要包括两个衰减特征分辨率的步长卷积(strided conv)网络:主干网络(main body)输出与输入特征图相同分辨率的特征图(feature maps);一个回归器,用于估计 heatmaps 中关键点的位置,并转换回原来的全分辨率. HRNet 关注于主干网络的设计, 如 Figure1.
2.1. 序列化的多分辨率子网络
序列化的多分辨率子网络(sequential multi-resolution subnetworks)
人体姿态估计网络,是采用序列地连接各高分辨率到低分辨率的子网络进行构建的,其中,每个 stage 的每个子网络都是包含多个卷积序列,且,在邻近的子网络间,会有下采样层,以将特征分辨率减半.
记 $\mathcal{N}_{sr}$ 为第 $s$ 个 stage的子网络,$r$ 为分辨率索引(特征图分辨率是第一个子网络分辨率的 $\frac{1}{2^{r-1}}$).
包含 $S$ 个 stages 高分辨率到低分辨率的网络可以表示为(假设 $S=4$):
$$ \mathcal{N}_{11} \rightarrow \mathcal{N}_{22} \rightarrow \mathcal{N}_{33} \rightarrow \mathcal{N}_{44} $$
2.2. 并行化多分辨率子网络
并行化多分辨率子网络(parallel multi-resolution subnetworks)
采用一个高分辨率的子网络作为第一个 stage,然后一个接一个的逐渐添加高分辨率到低分辨率的子网络,并并行地连接各个多分辨率子网络. 因此,后一个 stage 的并行子网络的分辨率特征包含了其前一 stage 的分辨率特征以及额外的低分辨率的特征.
例如,包含 4 个并行子网络的网络结构,如下:

2.3. 重复地多尺度融合
重复地多尺度融合(repeated multi-scale fusion)
HRNet 中引入 exchange units 来对并行子网络进行信息交换,使得每个子网络能够重复地接收其它并行子网络的信息.
exchange units 的信息交换机制,如图:

将三个 stage 划分为几个 exchange blocks(如,3 个),每个 block 由 3 个并行卷积组成.
图中,$\mathcal{C}_{sr}^b$ 表示第 $s$ 个 stage 的第 $b$ 个 block 的第 $r$ 个分辨率的卷积unit;$\varepsilon _{s}^b$ 表示对应的 exchange unit.
exchange unit 如图 Figure3 所示:

图3. 从左到右分别表示了,exchange unit 聚合高分辨率、中分辨率、低分辨率的信息的过程.
Figure3 的公式化的说明如下(简单起见,简化了下标$s$ 和上标$b$):
输入是 $s$ 个响应图(response maps): $\lbrace \mathbf{X}_1, \mathbf{X}_2, ..., \mathbf{X}_s \rbrace$.
输出也是 $s$ 个响应图:$\lbrace \mathbf{Y}_1, \mathbf{Y}_2,..., \mathbf{Y}_s \rbrace$,其分辨率与其输入相同.
每个输出都是 $s$ 个输入响应图的聚合: $\mathbf{Y}_k = \sum_{i=1}^s a(\mathbf{X}_i, k)$.
跨多个 stages 的exchange unit 还有一个额外输出的响应图:$\mathbf{Y}_{s+1} = a(\mathbf{Y}_s, s+1)$.
函数 $a(\mathbf{X}_i, k)$ 包含 $\mathbf{X}_i$ 从分辨率 $i$ 到分辨率 $k$ 的上采样或降采样处理.
这里,降采样通过 strided $3 \times 3$ 卷积来实现的. 例如,一个步长为 2 的 strided $3 \times 3$ 卷积能够实现 2x 的降采样;两个连续的步长为 2 的 strided $3 \times 3$ 卷积能够实现 4x 降采样.
上采样则采用的是最近邻采样(nearest neighbor sampling),并在其后接 $1 \times 1$ 卷积以对其特征的通道数.
如果 $i = k$,则函数 $a(\cdot, \cdot)$ 即为恒等映射:$a(\mathbf{X}_i, k) = \mathbf{X}_i$.
2.4. Heatmap 估计
Heatmap estimation.
只采用最后一个 exchange unit 输出的高分辨率特征表示,来回归 heatmaps. 其经验性的被证明比较有效.
loss 函数采用的是均方差误差(mean squared error),对预测的 heatmaps 和 groundtruth heatmaps 进行计算.
groundtruth heatmaps 是通过以关键点 groundtruth 坐标(x, y) 为中心,采用 1 pixel 标准差的 2D Gaussian 生成.
2.5. 网络实例化
网络实例化(Network instantiation)
关键点 heatmaps 估计网络的实例化,采用了 ResNet 的设计原则,将网络深度(depth) 分发到每个 stage,将网络通道数(channels) 分发到每个分辨率.
HRNet 的主干网络,包含有 4 个并行子网络的 4 个stages,其分辨率逐渐衰减一半,对应的,网络宽度(width)(通道数) 增加 2 倍.
第一个 stage 包含 4 个残差单元(residual units),与 ResNet50 相同,每个残差单元是由宽度为 64 的 bottleneck 组成,其后接一个 $3 \times 3$ 卷积,以将特征图宽度降低到 $C$.
第 2,3,4 个 stages 中分别包含 1,4,3 个 exchange blocks.
每个 exchange block 包含 4 个残差单元,每个参差单元在每个分别率都包含 2 个 $3 \times 3$ 卷积和一个跨分辨率的 exchange unit. 也就是说,总共包含 8 个 exchange units,共进行了 8 个多尺度融合.
实现中,采用了一个小网络 HRNet-W32 和一个大网络 HRNet-W48. 其中,32 和 48 分别表示在最后三个 stages 中高分辨率子网络的宽度($C$). HRNet-32 的其它三个并行子网络的宽度分别是 64,128,256. HRNet-48 的其它三个并行子网络的宽度分别为 96, 192, 384.
3. Experiments
3.1. COCO Keypoints Detection
数据集:COCO 数据集包含超过 200000 张图片,250000 个标注的人体实例,每个人体包含 17 个关键点. 模型训练采用的 COCO train2017 数据集共有 57K 张图片,150K 人体实例. 在 val2017 和 test-dev2017 数据集上验证模型,其分别包含 5000 张图片和 20K 张图片.
评价度量: COCO 提供的标注评价度量标注是基于 Object Keypoint Similarity(OKS):
$$ \mathbf{OKS} = \frac{\sum_i exp(-\frac{d_i^2}{2s^2k_i^2}) \delta (v_i >0)}{\sum_i \delta (v_i >0)} $$
其中,$d_i$ 是检测的关键点与 groundtruth 关键点之间的欧氏距离;$v_i$ 是 groundtruth 关键点的可见性标志;$s$ 是目标的尺度;$k_i$ 是控制衰减(falloff)的 per-keypoint 常数.
这里采用标准的精度(precision) 和召回分数(recall scores): $AP^{50}$ (AP at OKS=0.50), $AP^{75}$, $AP$(10 个位置的 AP 分数平均,OKS=0.50, 0.55, ..., 0.90, 0.95). $AP^M$ (中型目标),$AP^L$(大目标),$AR$ (at OKS=0.50, 0.55, ..., 0.90. 0.95).
http://cocodataset.org/#keypoints-eval
训练:保持人体检测框的长宽比为固定值:$height:width=4:3$,并从图片中裁剪人体框;并 resize 到固定尺寸,$256 \times 192$ 或 $384 \times 288$.
数据增强包括:随机旋转([-45, +45]); 随机尺度缩放([0.65, 1.35]); 翻转(flipping). 还采用了半身数据增强.
Adam optimizer. base learning rate 为 1e-3,在第 170 和 200 个 epochs 衰减为 1e-4 和 1e-5. 训练总共进行 210 个epochs.
测试: 采用 two-stage 的 top-down 框架,其中,与 Simple Baseline 使用相同的人体检测器. 最终的 heatmap 是原始图片和翻转图片的 heatmaps 的取平均. 每个关键点的位置是通过调整最高响应值位置到最高响应到第二高响应方向的四分之一偏移处.
Each keypoint location is predicted by adjusting the highest heatvalue location with a quarter offset in
the direction from the highest response to the second highest response.
val 数据集上的结果:

test-dev 数据集上的结果:

3.2. MPII Human Pose Estimation
数据集:MPII 人体姿态数据集包含 25K 张图片,40K 个标注实例,其中 12K 用于测试.
训练:训练策略与 COCO 数据集上的训练一致,除了网络输入图片尺寸裁剪为 $256 \times 256$,以便于对比.
测试:测试策略也基本与 COCO 数据集上的一致,除了采用提供的人体框,而不再进行人体框检测.
评价度量:采用标准方式,PCKh(head-normalized probability of correct keypoint) score. 如果关节点位置位于 groundtruth 位置的 $\alpha l$ 个像素位置内,即认为关节点估计正确. 其中,$\alpha$ 为常数,$l$ 为 head 尺寸,其对应于 groundtruth 的头部边界框对角线长度的 60%. 一般采用 PCKh@0.5($\alpha = 0.5$).
test 数据集的结果:

参数与计算量:

3.3. Pose Tracking

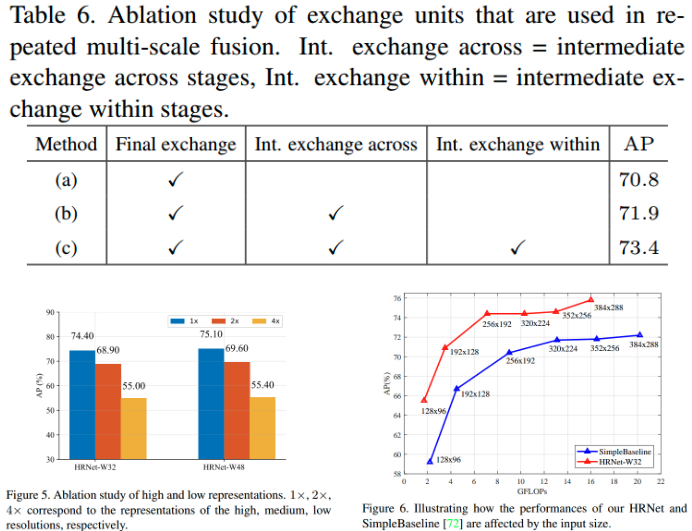
3.4. Ablation Study
3.5. 姿态估计示例

3.6. 其它应用

[1] - High-Resolution Representation Learning for ImageNet Classification
[2] - High-Resolution Representation Learning for Object Detection
39 条评论
博主你好,请问有实现这个代码的demo吗
论文作者开源了代码,可见:https://jingdongwang2017.github.io/Projects/HRNet/index.html
关于进行了 8 个多尺度融合. 这个不是很了解我的理解每个不是每个block包括四个残差单元嘛,就是每个并行层通过相应的四个残差组,然后再每个block末尾通过exchange units把各个尺度(例如第二个stage只有两个尺度) 融合起来,怎么会有8个尺度呢?还望博主有空解答。
8 个尺度,个人理解的是,每个残差单元,涉及到两种类型的特征传递,一个是同一分辨率的 feature maps; 另一种是跨分辨率 feature maps 间的特征传递. 这样的话特征融合实际上就包含了 4x2 八种.
感谢博主的分享,不过博主对于文中的第 2,3,4 个 stages 中分别包含 1,4,3 个 exchange blocks,这个是怎么看的,为什么第四阶段反而比第三阶段少一个
这个网络结构设计可能包含了很多作者的经验,比如最终的 heatmap 只采用最分辨率的,文章就有说明:We regress the heatmaps simply from the high-resolution representations output by the last exchange unit, which empirically works well.
感谢博主的回复,关于您所提及的文章中的这句话我也有看到,首先提一下我觉得8是8次多尺度融合,而不是8个尺度融合,此外,1个exchange blocks包含三个并行的卷积单元和一个跨越并行单元的交换单元,在第四stages ,只采用最高分辨率的信息,它仍然要融合其他3个尺度,而1个exchange blocks只有3个卷积单元,3个exchange blocks是怎么融合4个尺度的
论文里感觉是把每一次的 exchange unit 都作为了一种尺度的特征融合.
博主,我想问下:
def get_final_preds(config, batch_heatmaps, scale):
这个函数中,preds是关键点可能的范围吗?maxvals是该区域关键点的概率?
这个要怎么理解?范围里的概率都是一样的?
preds 是预测结果,maxvals 是 heatmap 的最大响应值吧. 可视化一下中间结果,会清晰很多.
谢谢回复!但是抱歉。。。。我还是不是很理解ORZ,我可视化了一下
preds=[[[607.5 622.5] [522.5 617.5]]],maxvals= 0.019440623
这里的preds 有四个坐标值,所以是个矩形范围吗
maxvals最大相应过于小了,就说明估计得很差,偏离groudtruth?
这个相应值是在估计范围的中心点吗?
preds 是joint 坐标值(x, y).
嗯嗯,谢谢楼主。我还想问下这个最大响应值maxvals是用来做什么的?我们不是已经获得了关键的坐标了吗?
这个具体用途建议参考源码作者所调用该函数的地方,如https://github.com/leoxiaobin/deep-high-resolution-net.pytorch/blob/master/lib/core/function.py.
好的,非常感谢
我最近在跑这个代码,但是在MPII数据集上怎样都到不了92,不知道问题出在哪里。
这个我倒是没有验证,在 MPII 上你得到最高的结果是多少
这篇文章源码 单张图前向结果1X16X64X64看不懂啊,怎么对应到pose啊 16是16个关键点可以理解
一楼是南理工的吗
batchsize x num_joints x heatmap_size1 x heatmap_size2,比如取每个 heatmap 的最大响应值就是关键点的 (x, y) 坐标.
pre似乎就是pose关键点在heatmap上的坐标
heatmap的size是64X64 就是原图长、宽除以64 得到的2个值分别乘上 上面得到的坐标值 映射回原图的坐标了?
根据 heatmap 得到 (x, y) 坐标,再映射回原始图片.
(xw, yh)你看我这样映射回原图有什么问题吗
x、y是pre, maxval = get_max_preds(result.detach().cpu().numpy())的返回值pre
https://www.aiuai.cn/aifarm943.html 这里的代码实现里有关于 heatmap 得到 xy 坐标的部分.
你这个是openpose的 和这个HRNET一样吗?作者说用inference.py里面的
get_final_preds()函数,得到原图中的坐标,但是效果好像不太行
原理是相似的,由 heatmap 得到 xy 坐标,一般是取最大响应值;或者是取最大响应值到第二响应值四分之一方向处. HRNET 我也尝试了自己写了 demo 实现,但效果确实不太行,所以没总结发出来,也在等 HRNET 开源个 demo .
我直接用的get_max_preds() 前向输入图直接resize(256,256) pytorch归一话到(0-1)
我直接用的get_max_preds() 前向输入图直接resize(256,256) pytorch归一话到(0-1)
得到的结果比get_final_preds()好,get_final_preds里面的center和scale我是用
yolov3检测计算的
嗯,前面有一个人体检测步骤.
如果是比例缩放了原始图片,这样是可以的.
pre, maxval = get_max_preds(result.detach().cpu().numpy())
我这样似乎得到坐标值了
up主 very good ,我要有up主这么强的文献阅读分析能力就好了
速度好快, 今天我刚看完这篇文章
只是略读一下,学习一下
博主 主要做 human pose estimation的吗?
图像分析类涉及的和相关的,比如,pose estimation, semantic segmentation, fashion && clothes, etc.
在读PhD or researcher?
researcher and engineer.