ConvLayer 是 Caffe Vision 网络层的一种.
Conv 层采用一组待学习的 filters 对输入图片进行卷积操作,每一个 filter 输出一个 feature maps.
Caffe 提供的 Vision 层一般是以 images 为输入,并输出另一种 images,或者是其它类型的数据和维度,也可以是单通道的(1 Channel)的灰度图,或三通道(3 Channel) 的 RGB 彩色图片.
Vision 层一般是对输入 images 的特定区域进行特定处理,得到特定区域对应的输出区域,如,
- Convolution Layer,
- Pooling Layer,
- Spatial Pyramid Pooling (SPP),
- Crop,
- Deconvolution Layer,
- Im2Col 等.
这里主要是卷积层 ConvLayer.

1. prototxt 中的定义
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
# filters 的学习率和衰减率
param {
lr_mult: 1
decay_mult: 1
}
# biases 的学习率和衰减率
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96 # learn 96 filters
kernel_size: 11 # each filter is 11x11
stride: 4 # 步长 4 pixels between each filter application
weight_filler {
type: "gaussian" # 初始化参数 initialize the filters from a Gaussian
std: 0.01 # distribution with stdev 0.01 (default mean: 0)
}
bias_filler {
type: "constant" # initialize the biases to zero (0)
value: 0
}
}
}
2. Caffe ConvLayer 定义
Caffe 提供了 Conv 层的 CPU 和 GPU 实现:
- 头文件 -
./include/caffe/layers/conv_layer.hpp - CPU 实现 -
./src/caffe/layers/conv_layer.cpp - CUDA GPU 实现 -
./src/caffe/layers/conv_layer.cu
其输入输出 data 的维度分别为:
- Input - N × C_i × H_i × W_i
- Output - N × C_o × H_o × W_o
其中,
$${ H_o = \frac{H_i + 2 * Pad_H- Kernel_H}{Stride_H + 1} }$$
$${ W_o = \frac{W_i + 2 * Pad_W- Kernel_W}{Stride_W + 1} }$$
3. caffe.proto 中的定义
message ConvolutionParameter {
optional uint32 num_output = 1; // 网络层输出数
optional bool bias_term = 2 [default = true]; // 是否有 bias 项
// Pad, kernel size, and stride are all given as a single value for equal
// dimensions in all spatial dimensions, or once per spatial dimension.
repeated uint32 pad = 3; // 补零的数量; 默认不补零,即值为 0
repeated uint32 kernel_size = 4; // kernel 大小,如 3-3x3,1-1x1,
repeated uint32 stride = 6; // 步长; 默认值为 1
// Factor used to dilate the kernel, (implicitly) zero-filling the resulting holes.
repeated uint32 dilation = 18; // The dilation; defaults to 1 用于带孔卷积(dilation)
// For 2D convolution only, the *_h and *_w versions may also be used to
// specify both spatial dimensions.
optional uint32 pad_h = 9 [default = 0]; // The padding height (2D only)
optional uint32 pad_w = 10 [default = 0]; // The padding width (2D only)
optional uint32 kernel_h = 11; // The kernel height (2D only)
optional uint32 kernel_w = 12; // The kernel width (2D only)
optional uint32 stride_h = 13; // The stride height (2D only)
optional uint32 stride_w = 14; // The stride width (2D only)
// 将输入通道和输出通道数分组
optional uint32 group = 5 [default = 1]; // The group size for group conv
optional FillerParameter weight_filler = 7; // The filler for the weight
optional FillerParameter bias_filler = 8; // The filler for the bias
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 15 [default = DEFAULT];
// The axis to interpret as "channels" when performing convolution.
// Preceding dimensions are treated as independent inputs;
// succeeding dimensions are treated as "spatial".
// With (N, C, H, W) inputs, and axis == 1 (the default), we perform
// N independent 2D convolutions, sliding C-channel (or (C/g)-channels, for
// groups g>1) filters across the spatial axes (H, W) of the input.
// With (N, C, D, H, W) inputs, and axis == 1, we perform
// N independent 3D convolutions, sliding (C/g)-channels
// filters across the spatial axes (D, H, W) of the input.
optional int32 axis = 16 [default = 1];
// Whether to force use of the general ND convolution, even if a specific
// implementation for blobs of the appropriate number of spatial dimensions
// is available. (Currently, there is only a 2D-specific convolution
// implementation; for input blobs with num_axes != 2, this option is
// ignored and the ND implementation will be used.)
optional bool force_nd_im2col = 17 [default = false];
}
4. ConvLayer 涉及的参数说明
Conv 层在 Caffe 定义中涉及的参数:convolution_param.
- num_output(C_o) - filters 数
- kernel_size - 指定的每个 filter 的 height 和 width,也可以定义为
kernel_h和kernel_w - weight_filler - 权重初始化
- type: 'constant' value: 0 默认值
- type: "gaussian"
- type: "positive_unitball"
- type: "uniform"
- type: "msra"
- type: "bilinear"
- bias_term - 可选参数(默认
True),指定是否学习 bias,在 filter 输出上添加额外的 biases. - pad - 补零,可选参数(默认为 0),也可以是
pad_h和pad_w. - stride - 步长,可选参数(默认为 1),也可以是
stride_h和stride_w. - group - 分组,可选参数(默认为 1),如果 group>1,则限制每个 filter 的连续性,分组到输入的一个子集subset 中. 即:
输入和输出通道被分为 group 个组,第 i 个输出通道组仅与第 i 个输入通道组相连接.
4.1 group 参数
根据 Caffe 官方给出的说明:
group (g) [default 1]: If g > 1, we restrict the connectivity of each filter to a subset of the input. Specifically, the input and output channels are separated into g groups, and the i-th output group channels will be only connected to the i-th input group channels.
group - 分组,可选参数(默认为 1),如果 group>1,则限制每个 filter 的连续性,分组到输入的一个子集subset 中. 即:
输入和输出通道被分为 group 个组,第 i 个输出通道组仅与第 i 个输入通道组相连接.
例如:
假设卷积层输入数据大小为 128×32×100×100,图像数据尺寸为 100×100,通道数为 32,假设卷积 filters 为 1024 ×3 ×3,
在 group 默认为 1 时,即为常见的全连接的卷积层.
当 group 大于 1 时,如 group=2,则卷积层输入 32 通道会被分组为 2 个 16 通道,而输出的 1024 个通道会被分组为 2 个 512 通道. 第一个 512 通道仅与对应的第一个 16 通道进行卷积操作,而第二个 512 通道仅与对应的第二个 16 通道进行卷积操作.
在极端情况下,如,输入输出通道数相同,如都为 32 个通道,group 值也为 32,则,每个输出卷积核 fliter 仅与其对应的输入通道进行卷积操作.
group conv
ResNeXt - Aggregated Residual Transformations for Deep Neural Networks 论文有关于 Group Convolution 的介绍.
论文阅读理解 - ResNeXt - Aggregated Residual Transformations for DNN
4.2 dilation 参数
[论文阅读理解 - Dilated Convolution]
5. gif 图示
Github - conv_arithmetic 给出的动图展示效果很不错.
以下图中,蓝色 maps 是输入,青色 maps 是输出.
Blue maps are inputs, and cyan maps are outputs.No padding, no strides

Arbitrary padding, no strides
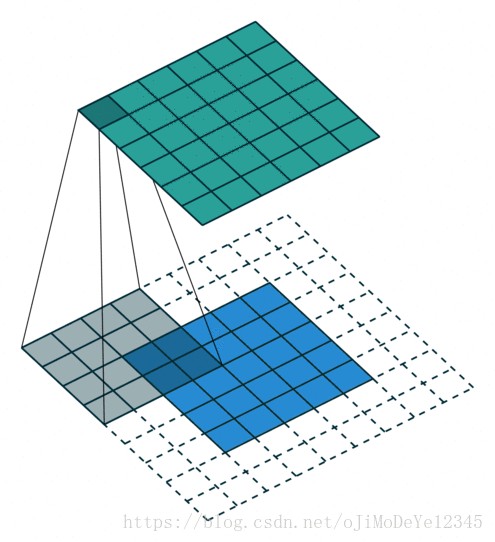
Half padding, no strides
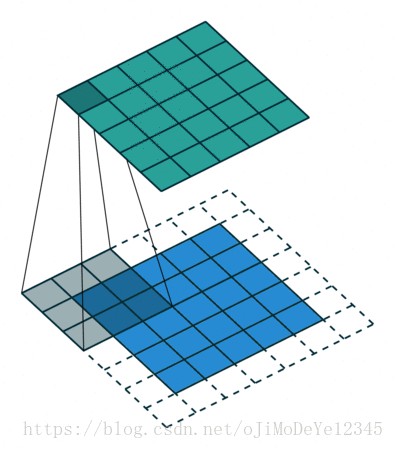
Full padding, no strides

No padding, strides

Padding, strides

Padding, strides (odd)
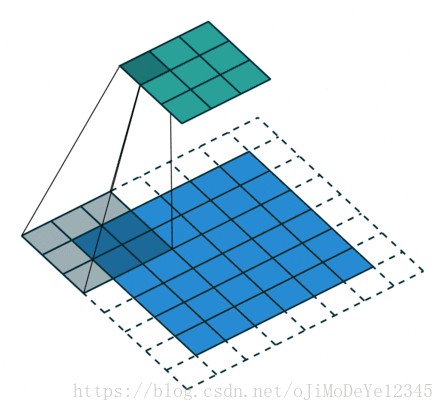
Dilated convolution - No padding, no stride, dilation
