题目:ModaNet: A Large-Scale Street Fashion Dataset with Polygon Annotations - 2018
作者:Shuai Zheng,Fan Yang,M. Hadi Kiapour,Robinson Piramuthu
团队:eBay Inc.
论文主要是介绍了构建的大规模街拍服装图像数据集. 可用于语义分割,实例分割和目标检测等任务.
ModaNet 基于多边形标注的大规模街拍服装数据集 - AIUAI
1. ModaNet 数据集
1.1. 数据集标注
[1] - 首先从 PaperDoll 数据集中收集了一百万(1 million) 张图像.
[2] - 然后,采用在 COCO 数据集上预训练的 Faster R-CNN 模型,检测出图片中只有一个人 的图像,以仅收集单个人的图像.
[3] - 对于所选择的图像中的初始数据集,进一步手工筛选 2000 张由于图片质量低而不适合进行标注的图片,以及 2000 张高质量的图片用于进行标注.
对于这 4000 张图片,采用 ImageNet 上预训练的 ResNet50 模型,并 finetune 模型最后一层,以作为图片质量的分类器.
然后,将分类器对初始数据集中全部图像进行分类,以选取高质量且只包含单个人的图片. 因此,有效的减少了手工标注者所标注的低质量图片量.
[4] - 将筛选出的图片送于手工标注者进行打标.
1.2. 数据集统计
ModaNet 数据集共包含 13 个服饰类别:bag, belt, boots, footwear, outer, dress, sunglasses, pants, top, shorts, skirt, headwear, scarf&tie.
如下:
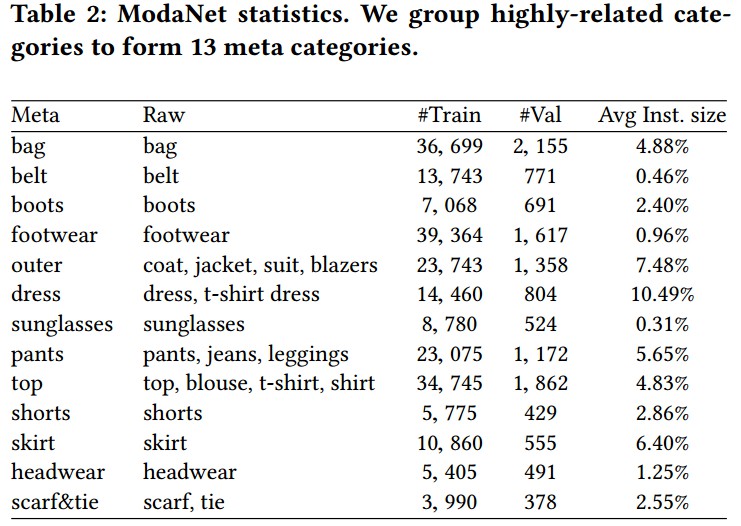
标注结果如:

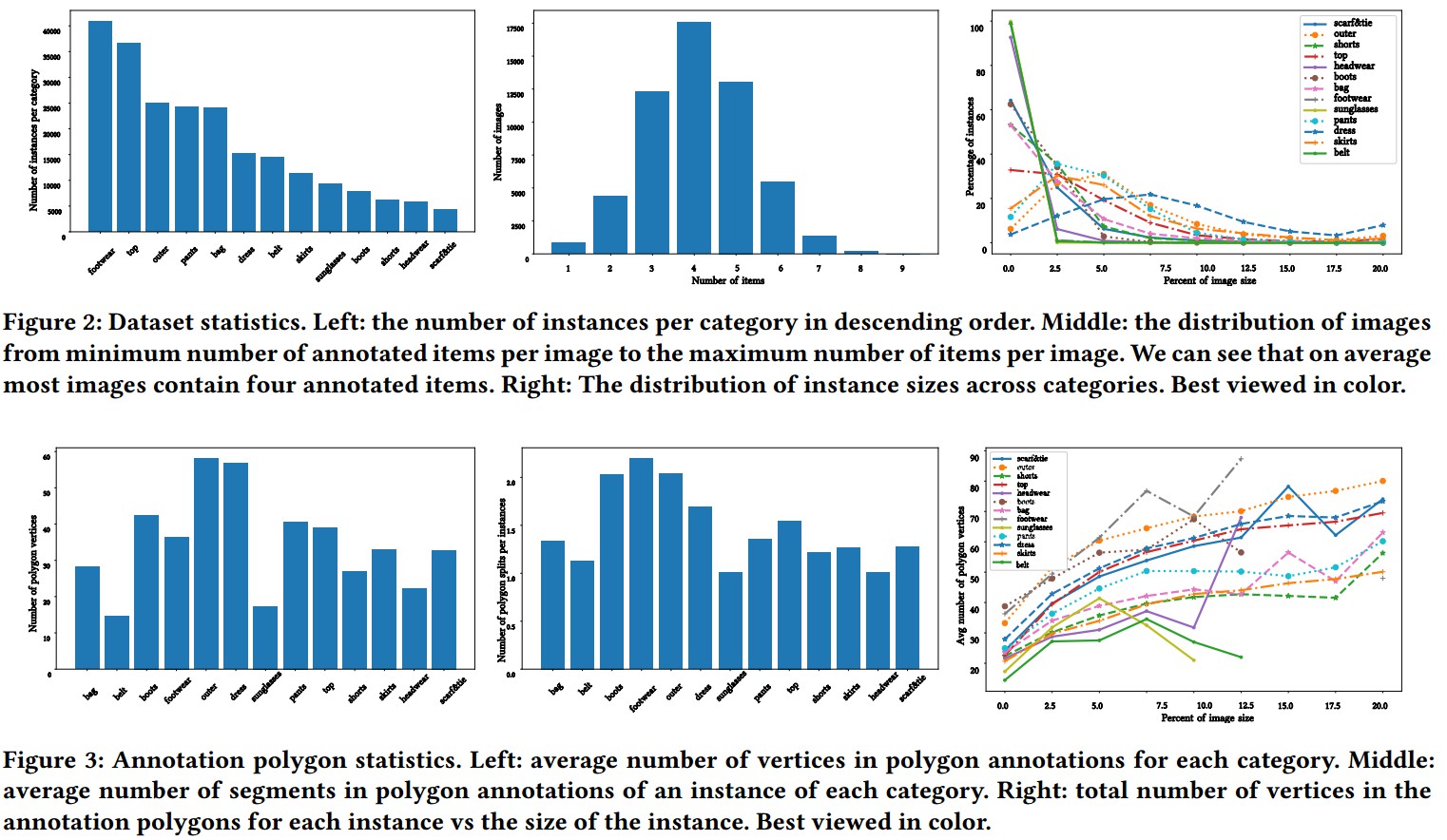
标注的数据分布统计:
1.3. 与其它服饰数据集对比
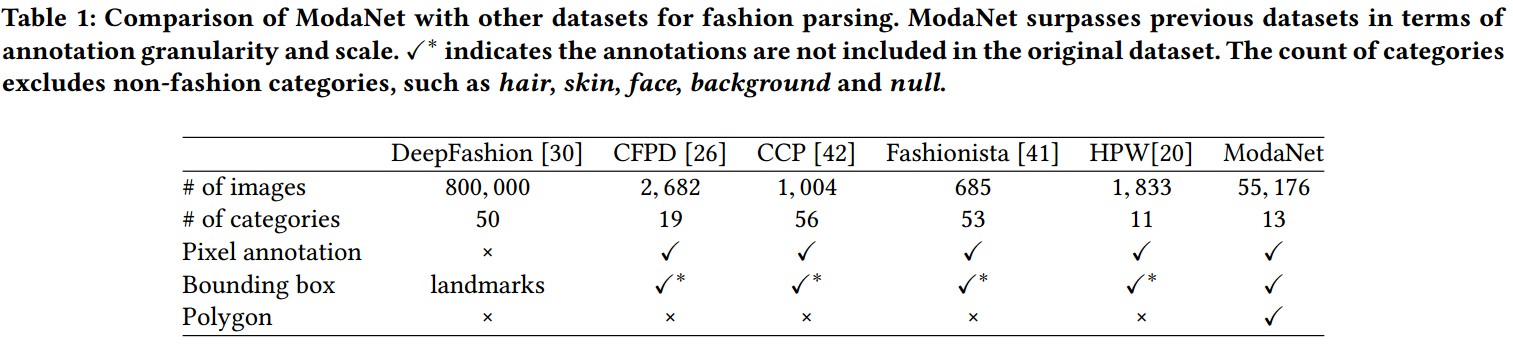
DeepFashion - DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. CVPR - 2016
CFPD - Fashion Parsing With Weak Color-Category Labels. IEEE Trans. Multimedia - 2014
CCP - Clothing Co-parsing by Joint Image Segmentation and Labeling. CVPR - 2014
Fashionista - Parsing clothing in fashion photographs. CVPR - 2012
HPW - Deep Human Parsing with Active Template Regression - 2015
2. ModaNet 应用场景
2.1. 服饰目标检测
服饰目标检测,其可以定位服饰单品的位置bbox,并给出 bbox 的服饰类别. 还可进一步应用于搜索与商品推荐.
2.1.1. 服饰 Groundtruth bbox 生成
在对图像进行了像素级和多边形标注后,可以很方便地推断出训练图片的边界框.
这里,采用从多边形标注数据生成的边界框作为边界信息. 处理后,将整个数据集划分为训练数据集(52337 张图片)和验证数据集(2799 张图片). 保证了 验证集内每个类别至少包含 500 个实例.
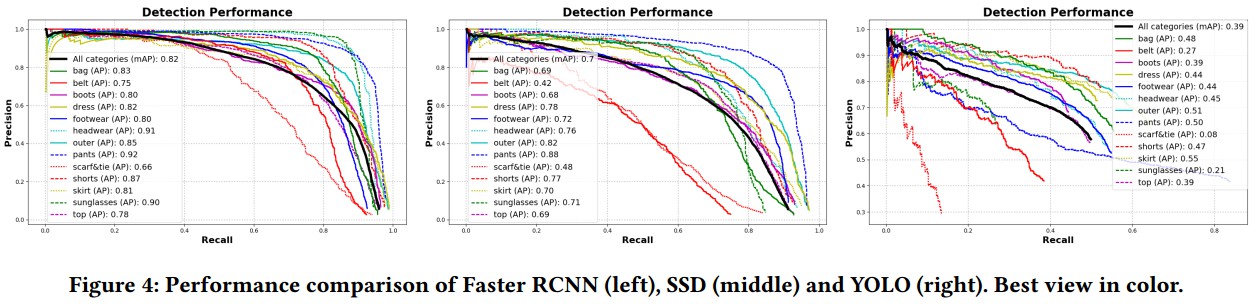
2.1.2. 不同服饰检测方法对比
对于数据集采用了 Faster RCNN(基础网络 Inception-ResNet), SSD(基于 InceptionV2) 和 YOLO(基于 InceptionV2) 三种模型,训练目标检测器.
目标检测器结果对比:

2.2. 服饰语义分割
服饰语义分割,是对图像中服饰的像素级理解.
2.2.1. 服饰 Groundtruth segmentation
基于图片的多边形标注,可以生成图像的像素级标注.
对于覆盖了单个目标的多边形标注,可以直接转换为对应的像素级标注.
处理后,将整个数据集划分为训练数据集(52337 张图片)和验证数据集(2799 张图片).
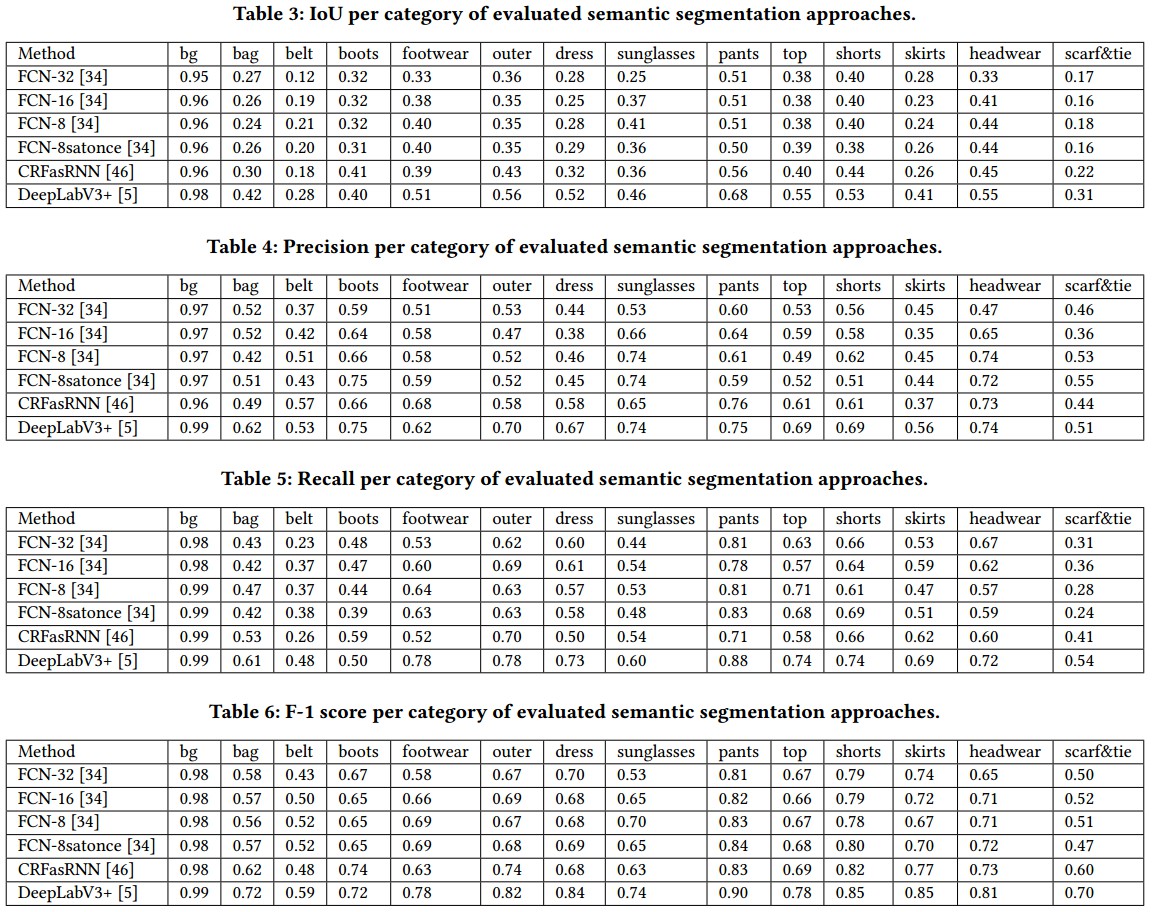
2.2.2. 不同服饰分割方法对比
采用了 FCNs, CRFasRNN 和 DeepLabv3+ 语义分割方法.
FCNs,基于 VGG+BN 和 Caffe 框架(https://github.com/shelhamer/fcn.berkeleyvision.org).
CRFasRNN,基于 Caffe 框架(https://github.com/torrvision/crfasrnn).
DeepLabv3+,基于TensorFlow 框架和 ImageNet 预训练的 Xception-65 模型(https://github.com/tensorflow/models/tree/master/research/deeplab).
不同语义分割方法结果对比:

2.3. 服饰多边形预测及颜色属性预测原型
服饰多边形预测 - PolygonRNN 和 Polygon-RNN++ 方法.
服饰语义分割的一个应用是,预测给定服饰商品的颜色属性名. 首先对服饰进行语义分割,然后对于分割的每块求取颜色平均 RGB 值,并映射到细分类的颜色命名空间. 方法原型预测结果如:
