作者:成鹏,三七互娱数据挖掘工程师,专注机器学习、深度学习及其在互联网行业的应用.
来源:请关注微信公众号“AI 前线” (ID:ai-front)
AI 前线导读:
标签系统提供了推荐问题和冷启动问题可行方案,广告素材的人工标签主要由美术人员进行添加修改,因此会存在标签描述信息过少,标签选取容易受到主观因素影响的现象. 除了上述广告投放需要素材标签,美术和投放同样需要素材标签来进行素材管理和相似素材查找.
为了解决上述问题,需要一种全新的素材标签生成方法. 作者考虑到素材对人的吸引程度主要是包括内容和风格两方面. 经过技术方案调研,并且结合业务需求,对比传统计算机视觉和深度学习,考虑到 CNN 具有极强大表达能力,本文作者最终采用了深度学习中改进 2-channel network 来生成素材的数字标签.
1. 背 景 - 业务背景
在《每天点击数 100 以内的极小量渠道,如何精准地投放游戏广告?》一文中指出,标签系统提供了推荐问题和冷启动问题可行方案,广告素材的人工标签主要由美术人员进行添加修改,因此会存在标签描述信息过少,标签选取容易受到主观因素影响的现象. 反应到广告投放上会存在下述问题:
[1] - 同一个广告计划下,存在两个不同素材具有一样的标签. 这种情况会使得两个素材计算得到的推荐值 R_m 一样.
[2] - 素材忘记打上标签. 这种情况会使得素材计算得到的推荐值 R_m 为 0,素材不会被推荐.
[3] - 人工标签不准确:风格内容差异较大的素材,人工标签很接近. 这种情况会影响到算法推荐的准确性.
除了上述广告投放需要素材标签,美术和投放同样需要素材标签来进行素材管理和相似素材查找.
为了解决上述问题,需要一种全新的素材标签生成方法. 考虑到素材对人的吸引程度主要是包括内容和风格两方面。经过技术方案调研,并且结合业务需求,对比传统计算机视觉和深度学习,考虑到 CNN 具有极强大表达能力,最终采用了深度学习中改进 2-channel network 来生成素材的数字标签.
2. 算法原理
2.1. 算法概述
标签作为素材特征表现形式的一种,经过 One-Hot Encoding,变为矩阵形式. 作为用于推荐系统的标签,衡量其准确性标准就是:越相似素材的标签距离是否越接近. 因此我们目的是通过比较两类素材是否相似或者说相似度是多少来生成素材标签. 那么构建卷积神经网络输入就是素材图片,然后网络输出是一个相似度距离,如图 2-1.
如果两幅素材图片匹配,输出值标注为 y=0;如果两幅素材图片不匹配,那么训练数据标注为 y=1.
思路如下:
[1] - 用一个网络提出素材图片特征,这个特征要具有足够的鲁棒性和判别性. 也就是说对于同一张图片和同一类素材而言,扭曲,旋转,反转,加噪声等变化后,网络输出图像特征要相似. 而对于不同图片和素材而言,它们特征要不相似.
[2] - 通过一个标准来衡量两张图片相似性,也就是目标输出. 相似度越接近 1,素材越相似.

图 2-1 CNN 网络结构
2.2. 网络结构
如下图 2-2 所示,2-channel network 是 siamese network 的进化版. 从 siamese network 的结构示意图中,可以看到这个网络包括两条分支,待比较两张图片 X1 和 X2 分别从 patch1、patch2 两条分支输入,经过共享权重的 branch network,进行提取特征向量 G(X1),G(X2),然后在最后一层 Lambda 层算出这两个特征向量的欧式距离 D(G(X1),G(X2)).
显而易见,由于目的是对特征进行欧式距离计算,那么只需要一个用于提取特征的网络就够了. 但是,如果只用一个网络的话,两幅图片需要分别调用两次前向运算,然后计算损失函数后,再方向传播,整个流程会比较复杂.
而 2-channel networks 解决了这个问题. 本来 patch1、patch2 是两张单通道灰度图像、它们各不相干,2-channel networks 把 patch1、patch2 进行合并,作为一个多输入的模型,两个输入流经同一个网络获得运算结果,可以看作是共享同一套权重的两个网络,共享权重. 换个方式描述:这两张图片,可以看成是一张双通道的图像. 也就是把两个 (1,64,64) 单通道的图片数据,放在一起,成为了 (2,64,64) 的双通道矩阵,然后把这个矩阵数据作为网络的输入,这就是所谓的:2-channel.
考虑到 VGG 在图像领域的稳定性和可靠性,2-channel networks 的卷积层直接采用训练好 VGG16 网络包含 13 个卷积层,由于全连接层需要重新设计和训练,因此不需要它的全连接,如图 2-4. CNN 后面接上自己设计的全连接层,最后一层全连接层输出即为图片的标签.
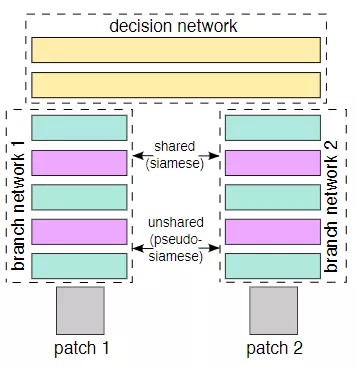
图 2-2 siamese network
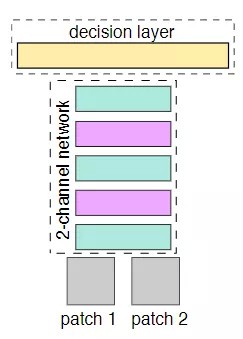
图 2-3 2-channel network
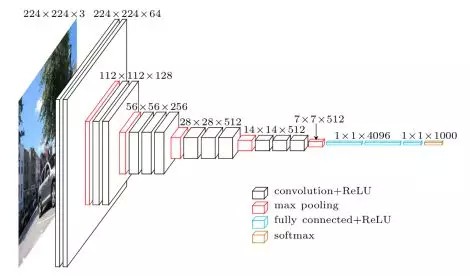
图 2-4 VGG16 网络
2.3. 输入输出
由于 2-channel network 的作用是判断两张输入的图片风格是否相似,那么训练模型需要解决下面问题:
[1] - 正负样本
游戏素材主要是静态图片、Flash、视频,静态图片可以直接作为网络输入,而 Flash 和视频可以通过截取帧数变为静态图片后输入. 由于网络的作用是判断两张输入图片是否相似,很显然需要将风格比较接近一对图片作为正样本输入. 鉴于单个游戏素材风格会很接近,那么单个素材截取帧数后的两张静态图片可以作为正样本输入,Y=1. 反之,两张分别来至不同素材的图片可以作为负样本输入, Y=-1.
[2] - 样本输出**
网络结构的输出的最后一层是全连接层,两张图片 x1, x2 作为输入经过网络得到两个输出特征向量 $G(x_1)$,$G(x_2)$. 接着构造两个特征向量距离度量,作为两张图片的相似距离计算函数:
$$ D(x_1, x_2) = ||G(x_1) - G(x_2)|| $$
2.4. 损失函数
接下来要考虑网络损失函数,损失函数应该满足下面性质:
[1] - 可导
[2] - 正样本中,两张图片风格相似,相似度越大,D(x_1,x_2 ) 越小,损失函数越小.
[3] - 负样本中,两张图片风格不相似,相似度越小,D(x_1,x_2 ) 越大,损失函数也要越小.
综上所述,网络损失函数定义为:

2.5. 风格量化
一般的 CNN 主要用于提取图片内容信息,而业务场景需要的判断图片风格是否类似. 那么如何衡量图片的风格?
举个例子,如图 2-5 左边小狗的内容加上梵高星夜的风格就成为了具有梵高星夜风格的小狗.

图 2-5 图片风格
考虑到 CNN 的本质是对图像特征进行逐层抽象表达,经过层层卷积层的变换,图像的特征变得越来越高级和稳定,对分类问题而已,可以预见网络最后一层的输出是一个具有很强稳定性和语义性的高级特征. 靠前层倾向于表达图片的具体信息,靠后层倾向于表达图片的高级语义信息如类别. 因此一个训练好的网络可以视为是一个良好的特征提取器.
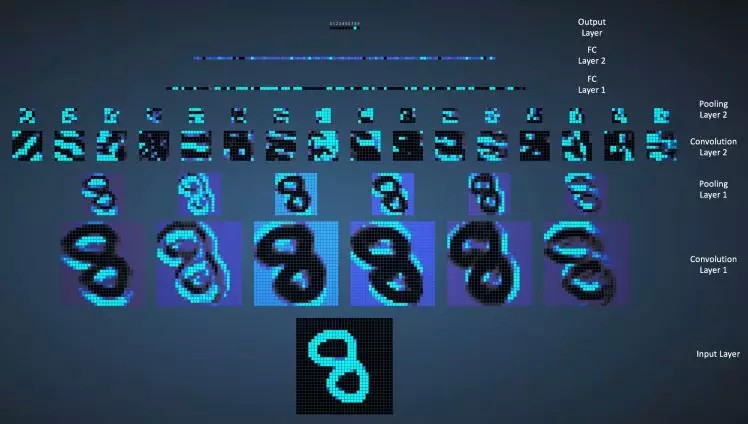
图 2-6 CNN 可视化
对于风格,用训练好的 VGG16 某一层输出特征的 Gram 矩阵进行表达,Gram 矩阵的数学形式如下:
$$ G_j(x) = A*A^T $$
Gram 矩阵之所以能表征图像风格是因为 CNN 卷积层提取和组合图像的特征并输出 feature map,随着层数的增多,提取到的特征越来越抽象和具有语义信息.
Gram 矩阵实际上是矩阵内积运算,其计算的是 feature map 之间偏心协方差,在 feature map 包含着图像的特征,每个数字表示特征的强度,Gram 矩阵代表着特征两两之间相关性.
3. 算法实现
3.1. 系统结构
整个系统的流程如下图所示:
[1] - 利用 FFmpeg 对素材进行截帧处理,得到 JPG 图片文件.
[2] - 素材截图文件通过 rsync 传输至用于深度学习机器,经过数据预处理后,作为模型输入.
[3] - 利用 Tensorflow 后端的 Keras 实现 2-channel network 生成素材标签.
[4] - 计算并存储素材相似度.
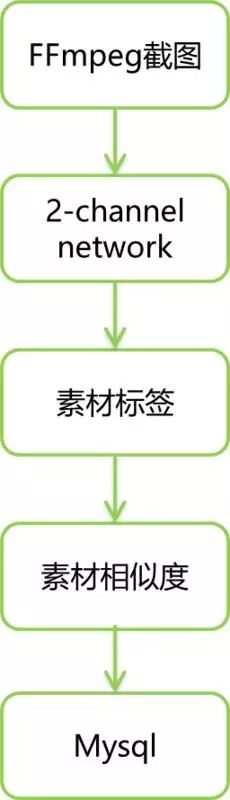
图 3-1 系统结构图
3.2. 数据准备
[1] - 素材截帧
对于动态素材利用 FFmpeg 进行截图处理,得到截图文件,如下图 3-2:

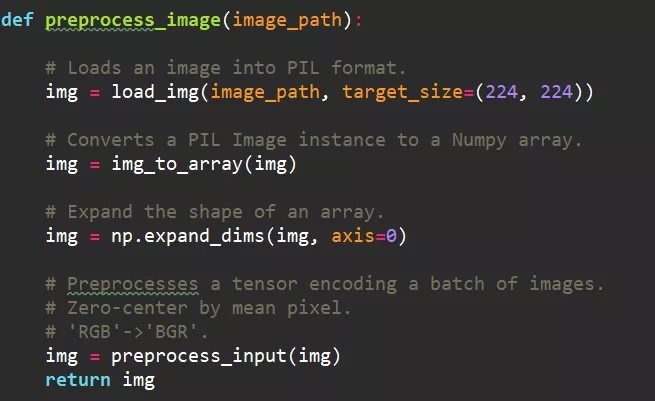
[2] - 图片预处理
由于采用的是 VGG16 网络结构,因此图片需要预处理成满足 VGG16 的要求,也就是形如(batch_size, channels, width, height)的四阶张量.
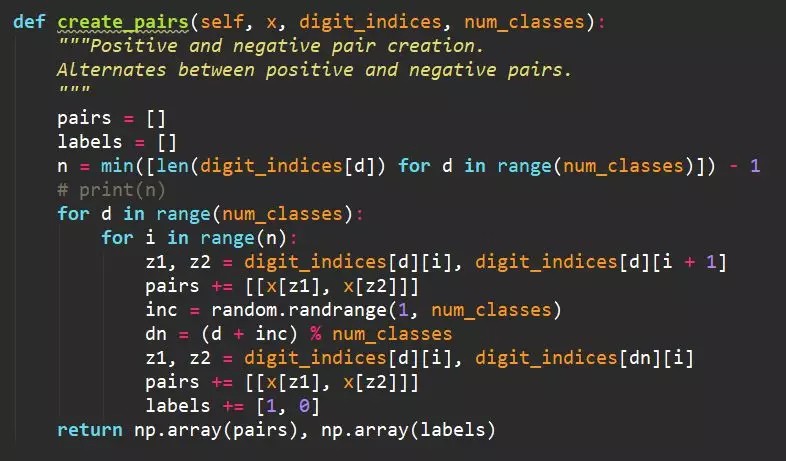
[3] - 正负样本
经过上面图片预处理后,接下来需要生成一对对的正负样本用于模型训练. 正样本从同个素材截图集合内抽取,负样本从不同素材截图集和内抽取.
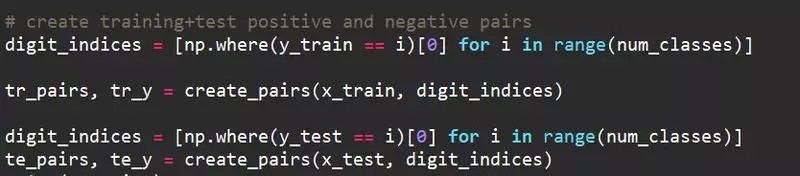
[4] - 训练集和测试集
3.3. 模型搭建
2-channel network 的 CNN 层采用不含 3 层全连接层并且训练好的 VGG16:

接下来的搭建需要训练 3 层全连接层,这里的激活函数采用 relu,因为对比与 sigmoid 函数和 tanh 函数,其具用以下性质:
[1] - 激活稀疏性.
[2] - 更加有效率的梯度下降以及反向传播:避免了梯度爆炸和梯度消失问题.
简化计算过程:没有了其他复杂激活函数中诸如指数函数的影响;同时活跃度的分散性使得神经网络整体计算成本下降.
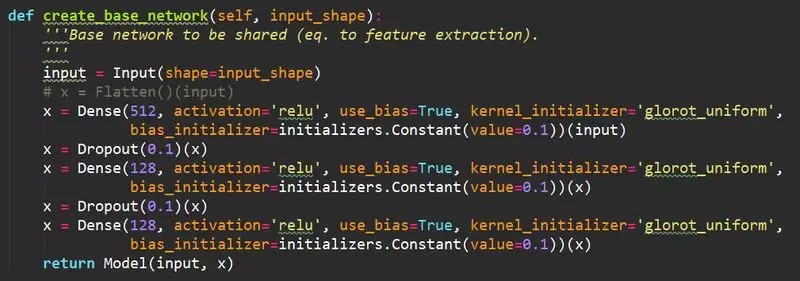
3.4. 模型训练
模型搭建完毕后,利用训练数据进行训练. 训练结果如下:

可以看到模型经过 20 次训练轮数,最后训练集 Accuracy 达到 99.60%,测试集 Accuracy 达到 97.47%.
训练完后,将模型的参数保存起来,便于后续线上使用.

3.5. 模型上线
服务器搭建线上 Tensorflow 以及 Keras 环境. 线上模型不需要在进行训练,只需要载入之前的参数配置文件即可.

然后提取网络最后一层全连接层,作为素材的标签. 然后计算素材之间两两的相似度,也就是欧式距离.
$$ D(x_1, x_2) = ||G(x_1) - G(x_2)|| $$
这里有个小技巧可以加快素材标签的加载速度:将素材标签文本序列化. 存储时:

读取时:

4. 算法应用
4.1. 广告投放
生成素材标签后,用于页游端极小量渠道游戏广告精准投放算法,用算法标签替换人工标签进行投放 AB 测试,测试计划中,68% 的投放计划算法标签是优于人工标签.
此外对于移动端,在对接今日头条 PMP 私有交易市场中,用户拿到更多属性如年龄,手机型号等,同样可以运用素材标签进行推荐.
4.2. 素材管理
素材管理分为两个应用:
[1] - 查找与优秀素材风格相似素材
在广告投放过程中,对于一些投放指标较好素材,业务方需要找到与它风格比较接近素材集合用于素材轮换. 那么根据业务方要求,考虑到渠道,游戏,渠道,投放效果等多种因素,根据素材的标签可以进行合理推荐,如图 4-1,4-2.
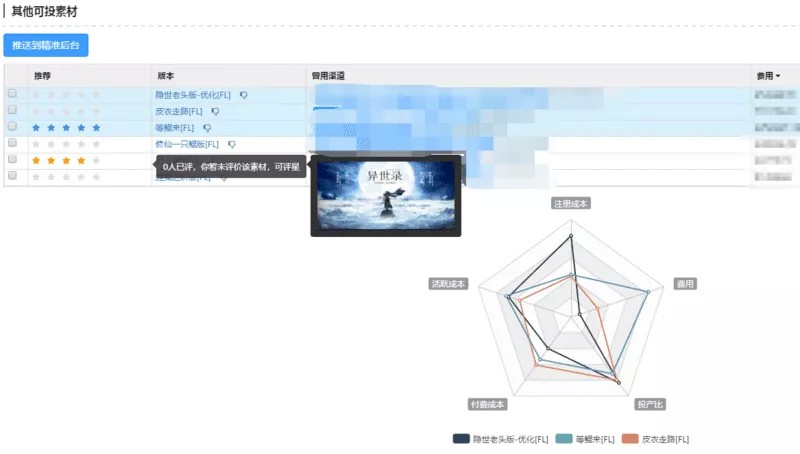
图 4-1 优秀素材风格相似素材推荐业务
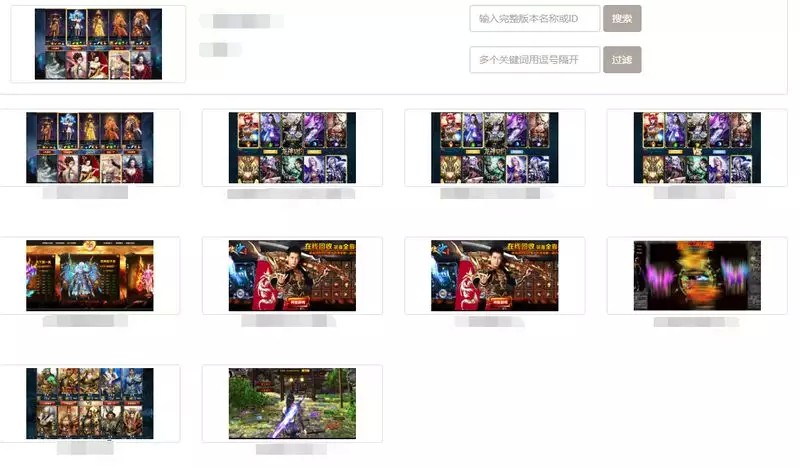
图 4-2 相似素材查找界面
[2] - 素材文件批量上传并自动识别归类包流
公司行销和美术在日常素材管理上经常会遇到以下情况:将不同的素材文件归类到准确的创意包中. 以前人工一个个查找对应的创意包然后添加,效率较低.
拥有自动化标签算法后,可以直接自动化生成素材标签,然后进行素材以图找图 (图 4-3),即可将素材准确地匹配至对应创意包,整个过程全部自动在数秒内完成,如图 4-4,4-5.
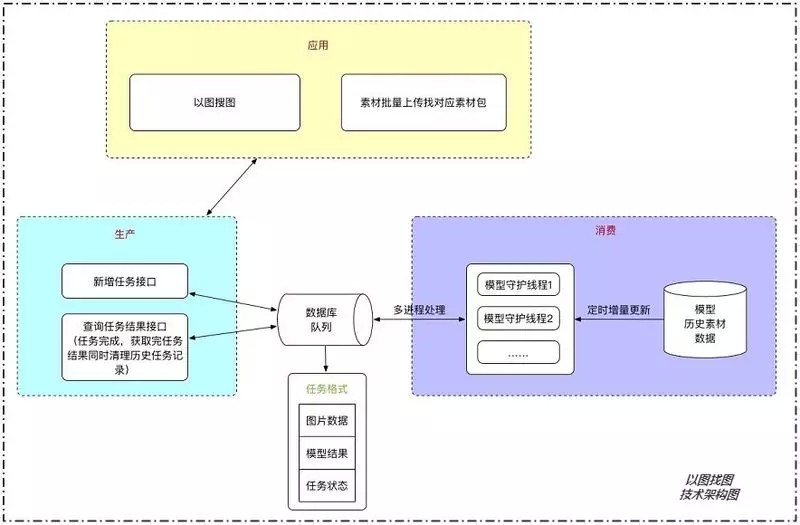
图 4-3 以图找图技术流程
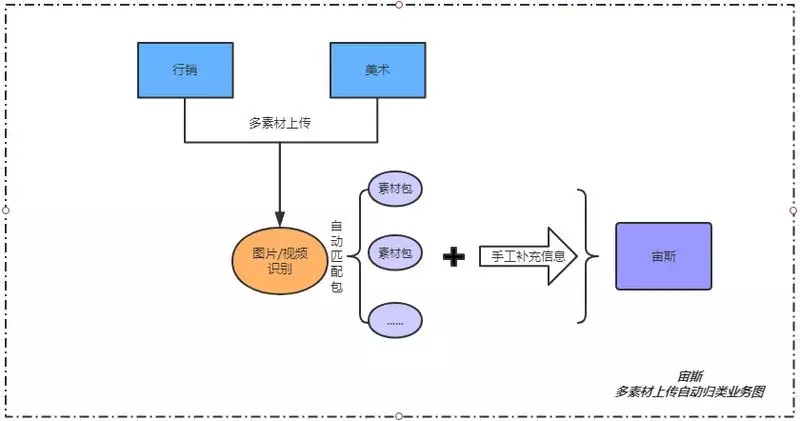
图 4-4 多素材上传自动归类业务流程
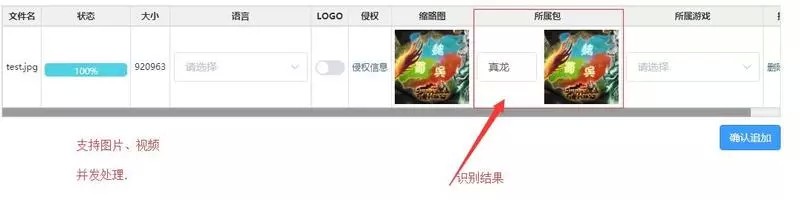
图 4-5 多素材上传自动归类界面
5. 算法现状以及展望
5.1. 算法的现状
目前素材标签生成算法中还存在一些问题:
[1] - 视频素材语义识别
一些长视频广告中大部分承载的是人物 + 场景 + 动作 + 语音的内容信息,如何用有效的特征对其内容进行表达是进行该类视频理解的关键.
目前算法只能基于多帧静态风格识别. 学习视频时间域上表达还做不到.
[2] - 素材风格变化过快
一般而言 Flash 素材前后风格会比较一致,或动漫,或国风,或暗黑等. 但是部分视频类素材前后风格变化,例如前几秒为真人出演,后面变为游戏类画面,而算法标签是获取素材多帧截图标签的均值. 平均以后对于素材推荐会有所影响.
[3] - 未考虑素材题材限定
用于广告投放的素材,部分广告所选素材受到游戏 IP 限定,素材推荐结果不一定符合业务需求.
5.2. 算法的展望
由于存在上面所述的一些问题,因此接下来算法的优化方向也在这三个方面:
[1] - 视频素材时域表达
对于视频素材可以扩展网络结构,采用基于 CNN 扩展网络识别方法,如图 5-1 所示,它总共有三层,在第一层对 10 帧 (大概三分之一秒)图像序列进行 M×N×3×T 的卷积(其中 M×N 是图像的分辨率,3 是图像的 3 个颜色通道,T 取 4,是参与计算的帧数,从而形成在时间轴上 4 个响应),在第 2、3 层上进行 T=2 的时间卷积,那么在第 3 层包含了这 10 帧图片的所有的时空信息. 该网络在不同时间上的同一层网络参数是共享参数的.
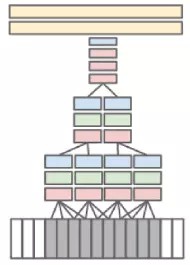
图 5-1 CNN 扩展网络
[2] - 素材风格变化过
对于素材可以采取截取更多帧数,并且可以考虑,视频帧与帧之间的变化作为素材特征之一. 用 CNN 提取每帧图像的特征,之后用 LSTM 挖掘它们之间的时序关系.
[3]- 加入素材题材限定
针对特定 IP 游戏,可以构建 IP 数据库,然后通过 CNN 进行指定 IP 人物或者物品识别. 当然更为简单的方式是找出相似素材后通过人工筛选出能用于此 IP 素材集.
6. 参考文献
[1] - Gatys L A , Ecker A S , Bethge M . Texture Synthesis Using Convolutional Neural Networks[J]. 2015.
[2] - L. Gatys, A. Ecker, and M. Bethge. A neural algorithm ofartistic style.Nature Communications, 2015.
[3]- https://www.cs.toronto.edu/~frossard/post/vgg16/
[4] - Karpathy A , Toderici G , Shetty S , et al. Large-Scale Video Classification with Convolutional Neural Networks[C]// 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, 2014.