原文: The unreasonable effectiveness of Deep Learning Representations
作者:Emmanuel Ameisen
译者: 付腾 王飞 汪鹏 - AI研习社
注:对原译文有一定的校对与修改.

训练电脑以人类的方式去看图片
1. 为什么从相似性搜索做起?
一张图片胜千言,甚至千行代码.
很多的产品是基于我们的感知来吸引我们的. 比如在浏览服装网站上的服装,寻找 Airbnb 上的假期租房,或者领养宠物时,物品的颜值往往是我们做决定的重要因素. 想要预测我们喜欢什么样的东西,看看我们对于事物的感知方法大概就能知道了. 因此,这也是一个非常有价值的考量.
但是,如何让计算机以人类的视角来理解图片长久以来是计算机科学领域的一大挑战. 直到 2012 年,深度学习在某些感知类任务(比如图像分类或者目标探测)中开始慢慢地超过了传统的机器学习方法(比如方向梯度直方图, Histograms of Oriented Gradients,HOG). 关于学界的这次转变,一个主要的原因就要归功于深度学习对于在足够大训练数据集上自动提取出有意义的表征的能力.
这也是为什么很多开发团队,比如 Pinterest,StitchFix 以及 Flickr 等,开始使用深度学习来学习他们获得的图片当中的表征,基于这些提取的表征以及用户对于视觉内容是否欢迎的反馈来为用户提供内容推荐. 类似的,insight 的研究员也使用深度学习来建立一系列的模型,比如帮助用户找到适合领养的猫咪,推荐适合购买的太阳镜,或者搜索具体的艺术风格.
许多推荐系统是基于协同过滤的:利用用户关联来提出建议(“喜欢这个物品的用户可能还喜欢···”). 但是,这类模型需要非常大量的数据才能比较准确,而且这类模型在应对新的还未被用户浏览过的新物品的时候会表现不佳.
物品表征是另一个解决办法,那就是基于内容的推荐系统,这种推荐系统并不会受到上面提到的未被浏览的新物品问题的影响.
此外,这些表征允许消费者有效地搜索图像库,(通过图像查询)来获取与他们刚拍摄的自拍相似的图像,或者搜索某些特定物品的照片,比如汽车(通过文本查询). 这方面的常见示例包括 Google 反向图片搜索服务以及 Google 图片搜索服务.
根据对于许多语义理解项目的技术经验,该博文介绍了如何构建自己的表征模型,包括图像和文本数据,以及如何有效地进行基于相似性的搜索. 以便于能够从零起步构建自己的快速语义搜索模型,无论数据集的大小如何.
Building a Semantic Search Engine - Streamlit Code
2. 计划方案
在机器学习中,有时也和软件工程一样,方法总比问题多,每种方法都有不同的权衡.
如果我们正在进行研究或本地的产品原型设计,我们可以暂时摆脱效率非常低的解决方案.
但是如果我们的目标是要构建一个可维护和可扩展的相似图像搜索引擎,我们必须考虑到两点:
- [1] - 如何适应数据演变(adapt to data evolution)
- [2] - 模型的运行速度(how fast our model can run)
让我们先想象几种解决方案:
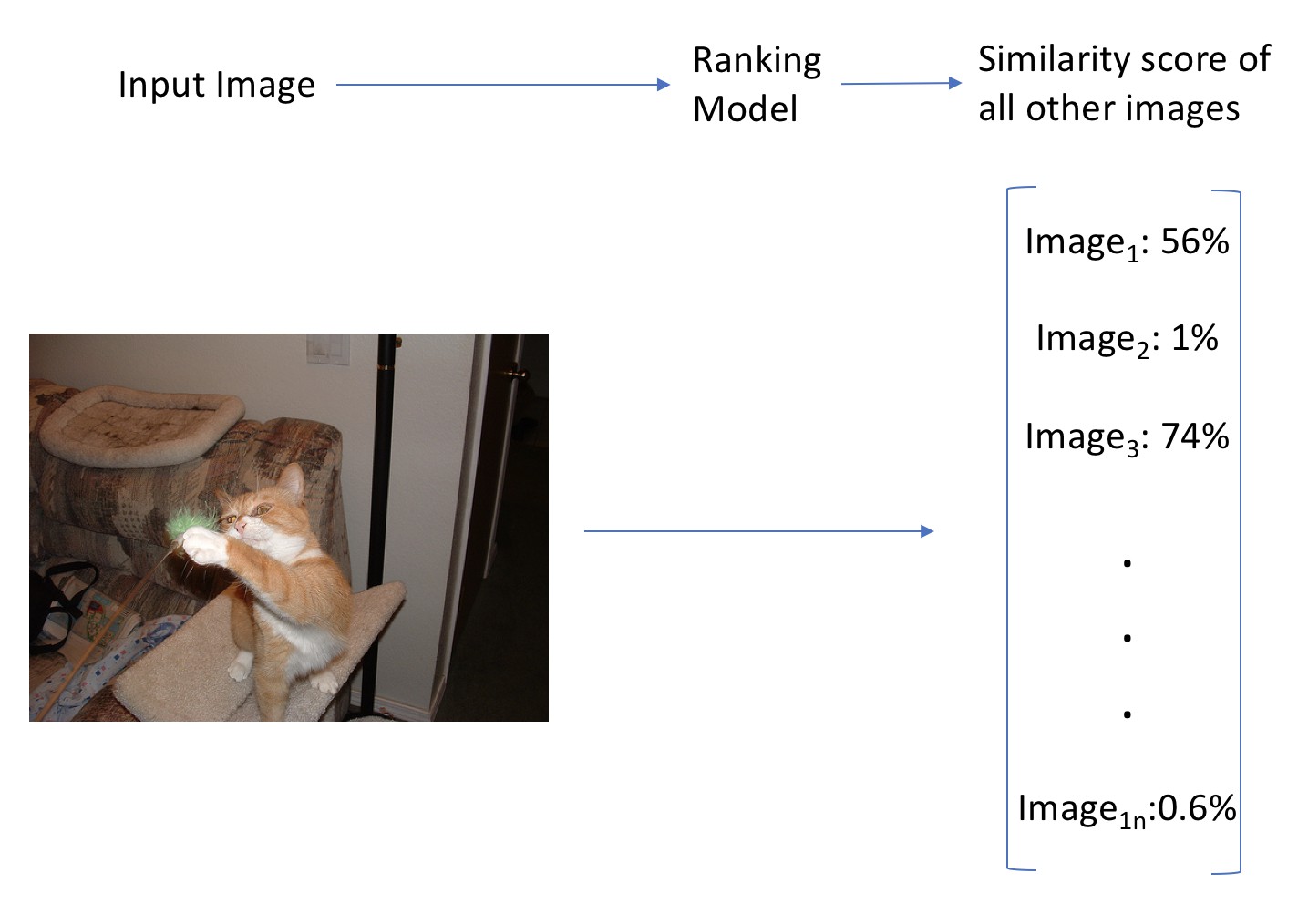
方案 1 的工作流程
方案 1: 构建一个端对端的排名模型(ranking model),对所有图片进行模型训练.
模型的输入是一个图片,并输出所有图片间的相似性值(similarity score) 数组,其表示了输入图片和图片训练集中的每一个图片的相似性数值. 模型的预测运行速度快(只有一次前向计算),但是,当图片训练集中新增了图片时,都需要重新训练新的模型. 而且,模型迭代过程中会遇到一个问题:网络输出包含太多的类别,导致难以正确优化.
虽然该方案运行速度快,但可扩展性受限,不适用于大规模数据集. 此外,还需要手工对训练数据集中图片的相似性进行标定,其是非常耗时繁琐的.
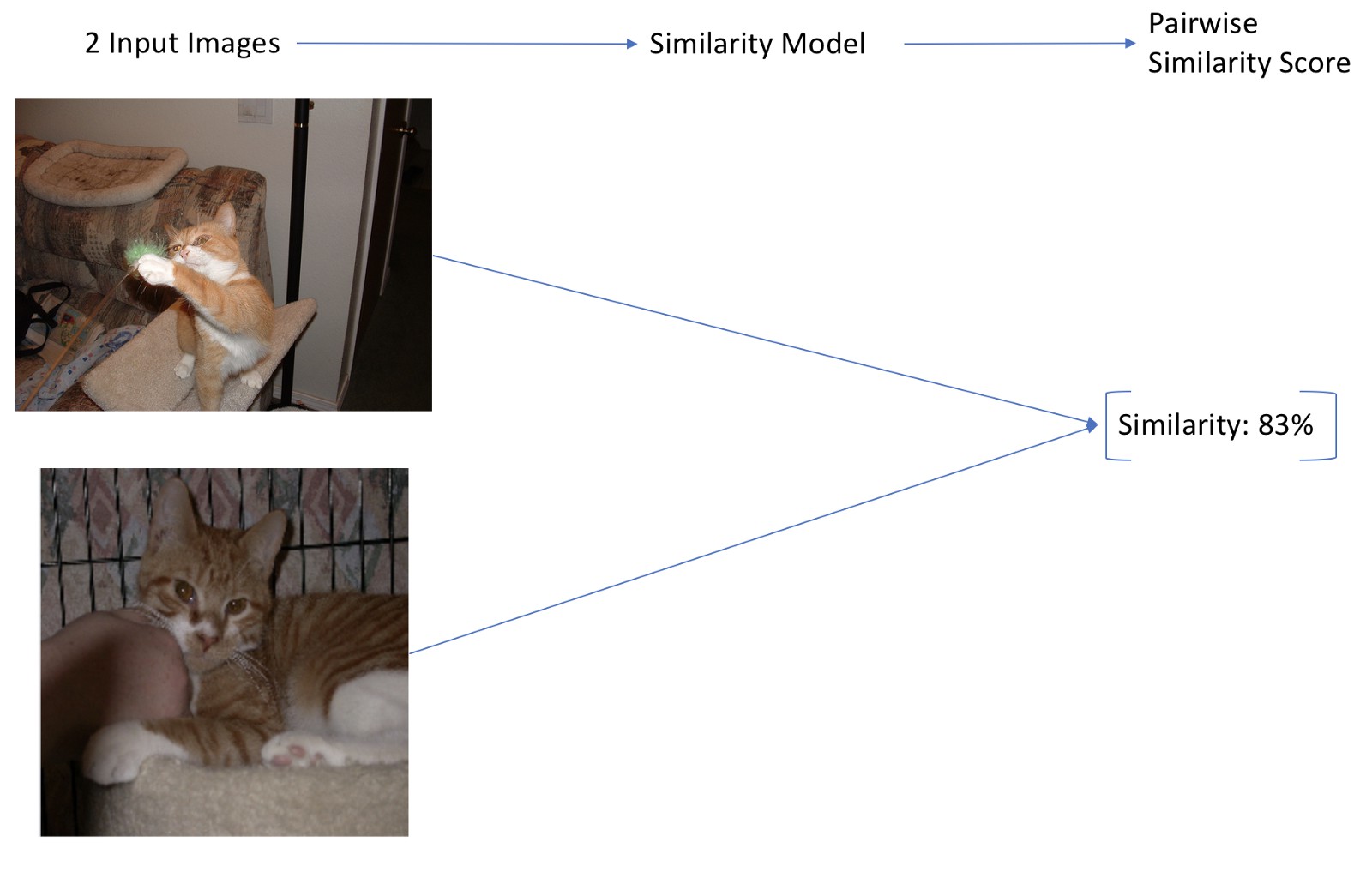
方案 2 的工作流程
方案 2:构建一个相似性预测模型(Similarity Model).
模型输入是两张图片,输出是成对的 0~1 区间的相似性值.(如Siamese Networks).
该模型对于大规模数据集也比较准确,但,受限于一个可扩展问题: 一般情况下需要从大规模的图片数据集中找出相似图片,因此需要对所有可能的图片对(image pair) 运行一次相似性模型. 如,CNN 模型,对于大规模的图片集,其处理速度太慢.
另外,该方案只能用于基于图片相似性的搜索,而不能扩展到基于文本的相似性搜索.

方案 3 的工作流程图
方案 3: 更简单的方法,类似于字嵌入(word embeddings). 如果可以为图片构建具有代表性的向量表示或嵌入( expressive vector representation, or embedding),则可以通过计算向量距离来计算图片间的相似性.
很多库实现了快速解决方案,如,这里使用的 Annoy .
此外,如果能够预先计算数据集中所有图片的表示向量,则,该方案是既快速(一次前向计算,一次有效的相似性搜索),扩展性又强的.
而且,如果能够为图像和文本建立嵌入(embeddings)表示,则能够进行文本到图像的搜索.
因此,本文采用方案3.
3. 搜索引擎实现过程
如何在实际中使用深度学习表示来创建搜索引擎?
最终目标是拥有一个搜索引擎,它可以接收图像并输出相似的图像或标签,可以接收文本并输出类似的单词或图像. 对此,将经历以下三个连续的步骤:
- 为输入图片寻找相似的图片 (图片 → 图片)
- 为输入的文字寻找相似的文字 (文本 → 文本)
- 为图像生成标签,并使用文本搜索图像 (图像 ↔ 文本)
为此,这里将使用嵌入(embeddings),即,图像和文本的向量表示. 构建嵌入表示后,只需要计算与输入向量接近的向量即可.
计算图像嵌入向量相似性间的方法是,余弦相似度 cosine similarity. 相似图像将具有类似的嵌入表示,即嵌入向量之间的高余弦相似性。
4. 数据集
4.1 图片数据集
数据集 - pascal-sentences
共有 1000 张图像组成,分为 20 个类别,每个类别下 50 张图像. 此数据集包含每个图像的类别和一组标题(captions).
为了使问题的难度增加,并且为了验证方法的泛化性能,这里将只使用类别,而忽略标题.
数据集中总共有 20 个类,如下所示:
aeroplane bicycle bird boat bottle bus car cat chair cow dining_table dog horse motorbike person potted_plant sheep sofa train tv_monitor

图像示例(标签很繁杂(噪声干扰较多))
数据集的标签非常繁杂:许多照片包含多个类别,标签并不总是来自最突出的标签. 例如,在右下角,图像被标记为 chair 而不是 person,虽然 3 人站在图像的中心,椅子几乎看不见.
4.2 文本数据集
此外,加载在 Wikipedia 上预训练的单词嵌入(这里使用 GloVe 模型中的单词嵌入). 并使用这些向量将文本合并到语义搜索中.
有关这些单词向量如何工作的更多信息,请参阅 NLP 教程的第 7 步。
5. 图像 -> 图像(以图搜图)
这里采用在ImageNet 上预训练的 VGG16 模型来生成图像的嵌入向量表示.(这种方法适用于任何 CNN 网络结构)
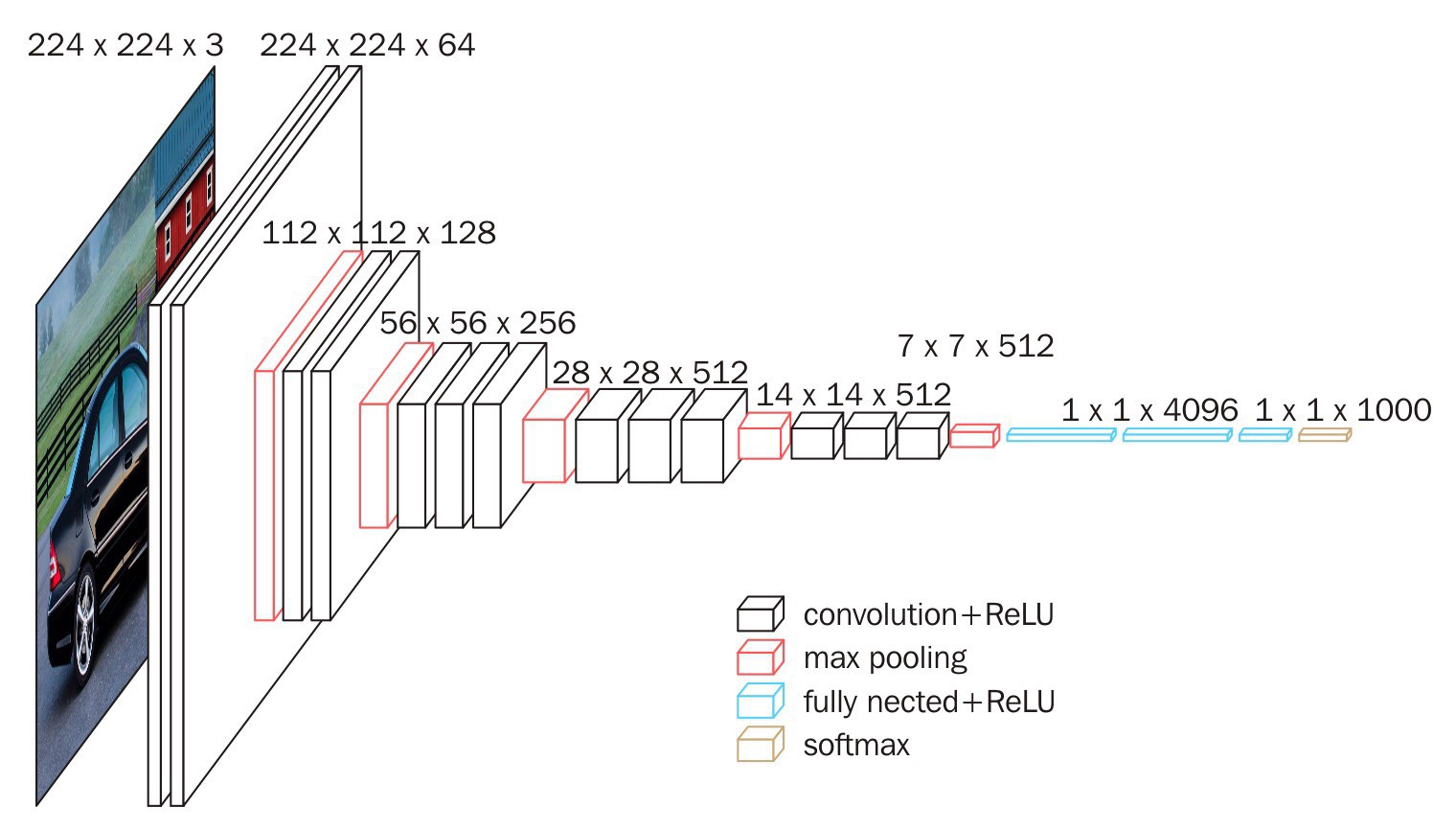
VGG16
将使用预训练的 VGG16 模型直到倒数第二层,并存储激活值. 如图,绿色突出显示的嵌入层表示,该嵌入层位于最终分类层之前.
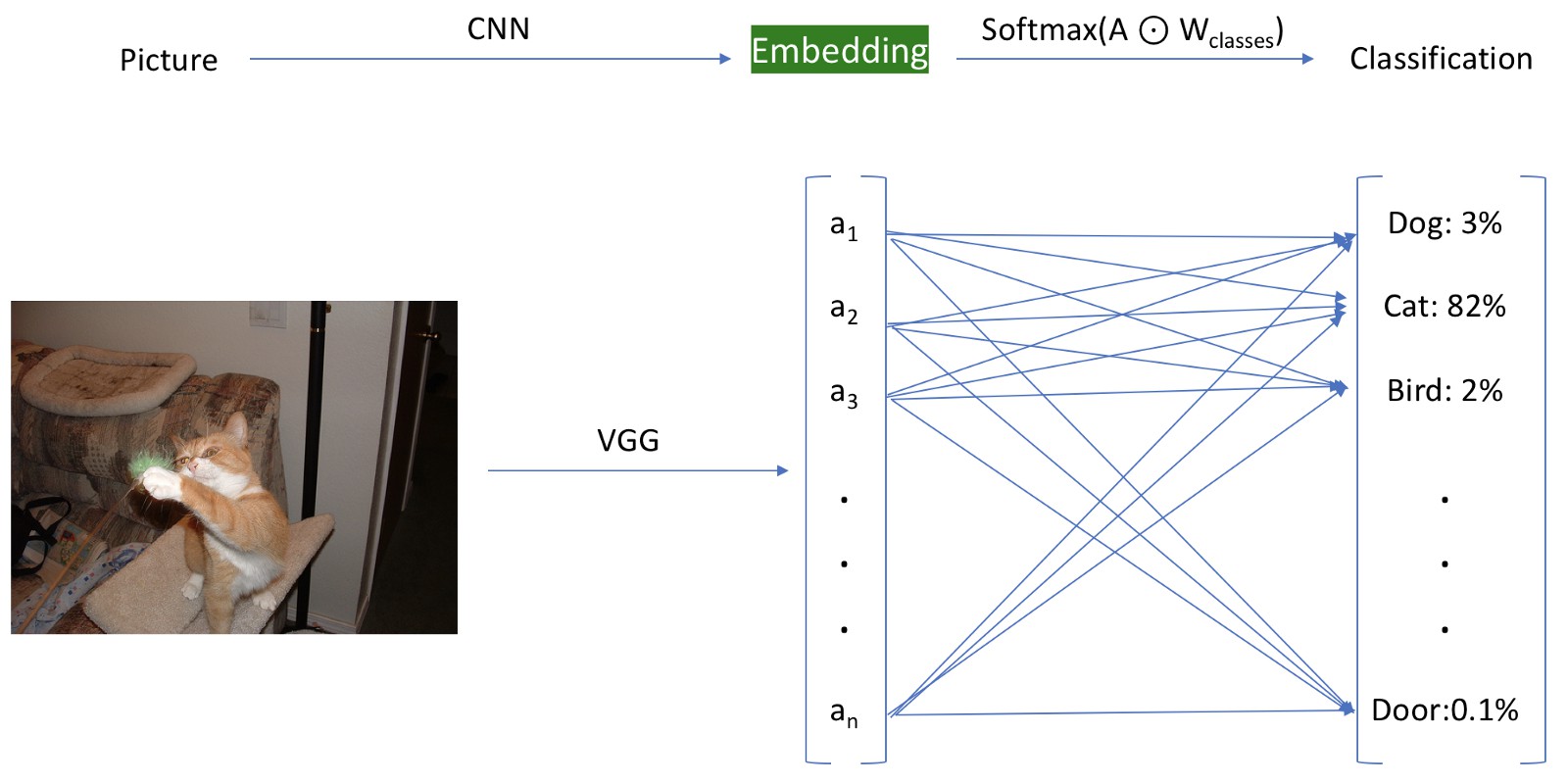
最终分类层之前使用嵌入层.
根据构建的该模型生成图像的特征表示,即可保存到磁盘,以便于重新使用,而无需再次进行推断. 这也是嵌入表示在实际应用中如此受欢迎的原因之一,因为其可以实现巨大的效率提升. 除了将嵌入表示存储到磁盘,还可以使用 Annoy 构建嵌入的快速索引,以使得能够非常快速的找到任何给定嵌入表示的最接近的嵌入向量.
如下嵌入表示,每个图像都表示为 4096 的稀疏向量(每一行为一个样本).
注:向量稀疏的原因是,在激活函数之后取了值,会将负数归零.
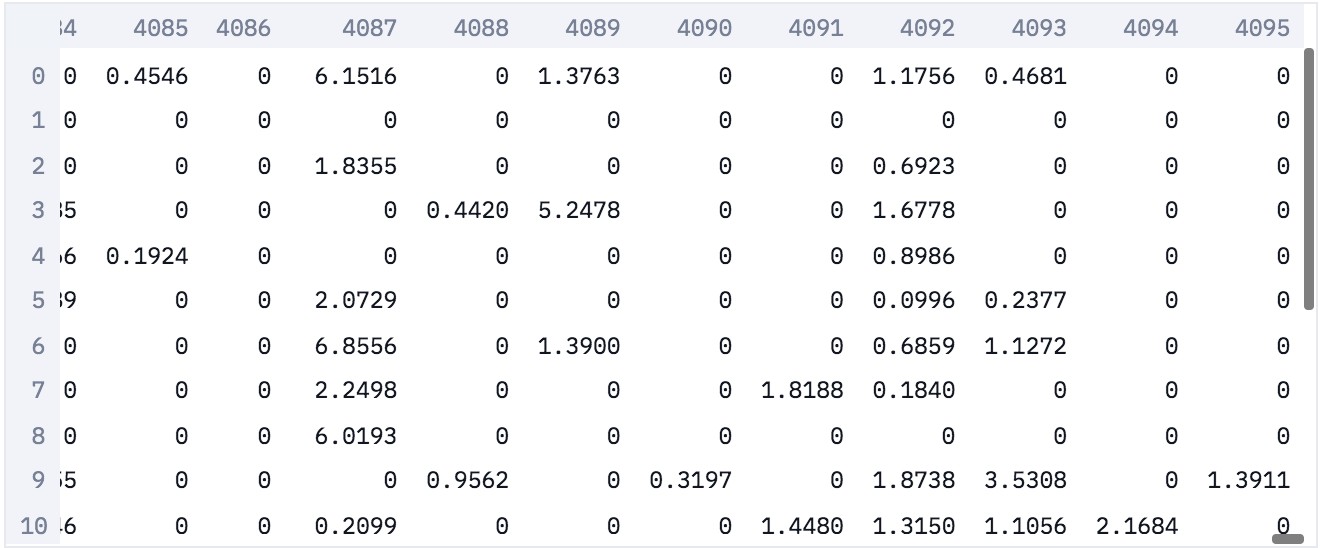
图像嵌入
5.1 基于图像嵌入向量来搜索图像
基于该嵌入表示模型,可以提取输入图像的嵌入向量,并寻找构建的快速索引,以寻找相似的嵌入向量,从而找到相似图像.
图像嵌入向量是信息更丰富的,因为图像标签通常很嘈杂,并且一般来说图像内包含的信息比标签的信息更多.
如,图片数据集中如下图片,有 cat 和 bottle 这两个类,你觉得图片会被标记成哪一个类?

Cat 还是 Bottle? (图像被缩放到了 224x224)
正确答案是瓶子Bottle.
这是实际数据集中经常遇到的问题. 将图像标记为唯一类别的情况是很少的,这也是希望使用更细微的表示的原因.
下面例示,基于嵌入表示的图像搜索,是否比人类标签更有效果.
寻找 dataset/bottle/2008_000112.jpg 的相似图片:

结果很棒,得到的结果大部分为猫的图像,看起来很合理.
预训练的网络模型,经过对各种图像的学习训练,包括 cat 图像,因此,模型能够准确找到相似的图像,哪怕模型之前并未接受过本文特定数据集的训练.
但是,在最后一行的中间图像中,出现了 Bottle. 一般情况下,这种方法能够很好地找到类似的图像,但某些场景下,仅对图像的一部分感兴趣.
例如,给一张猫和瓶子的图像,可能只对相似的猫感兴趣,而不是类似的瓶子.
5.2 半监督搜索
解决此问题的常用方法是,首先使用目标检测模型,检测出猫,然后对原始图像的裁剪版本进行图像搜索.
这增加了巨大的计算开销,如果可能的话,希望避免这种开销.
有一种更简单的 hacky 方法,其包括重新赋予激活的权重. 通过加载最初丢弃的最后一层权重来实现,并且仅使用与正在寻找的类别的索引相关联的权重来重新对嵌入表示进行加权. 这个很棒的方法最初是从 Insight 研究员 Daweon Ryu 发现的.
如,下图中,使用 Siamese cat 类别的权重来重新赋予数据集上的激活值(以绿色突出显示部分)的权重.
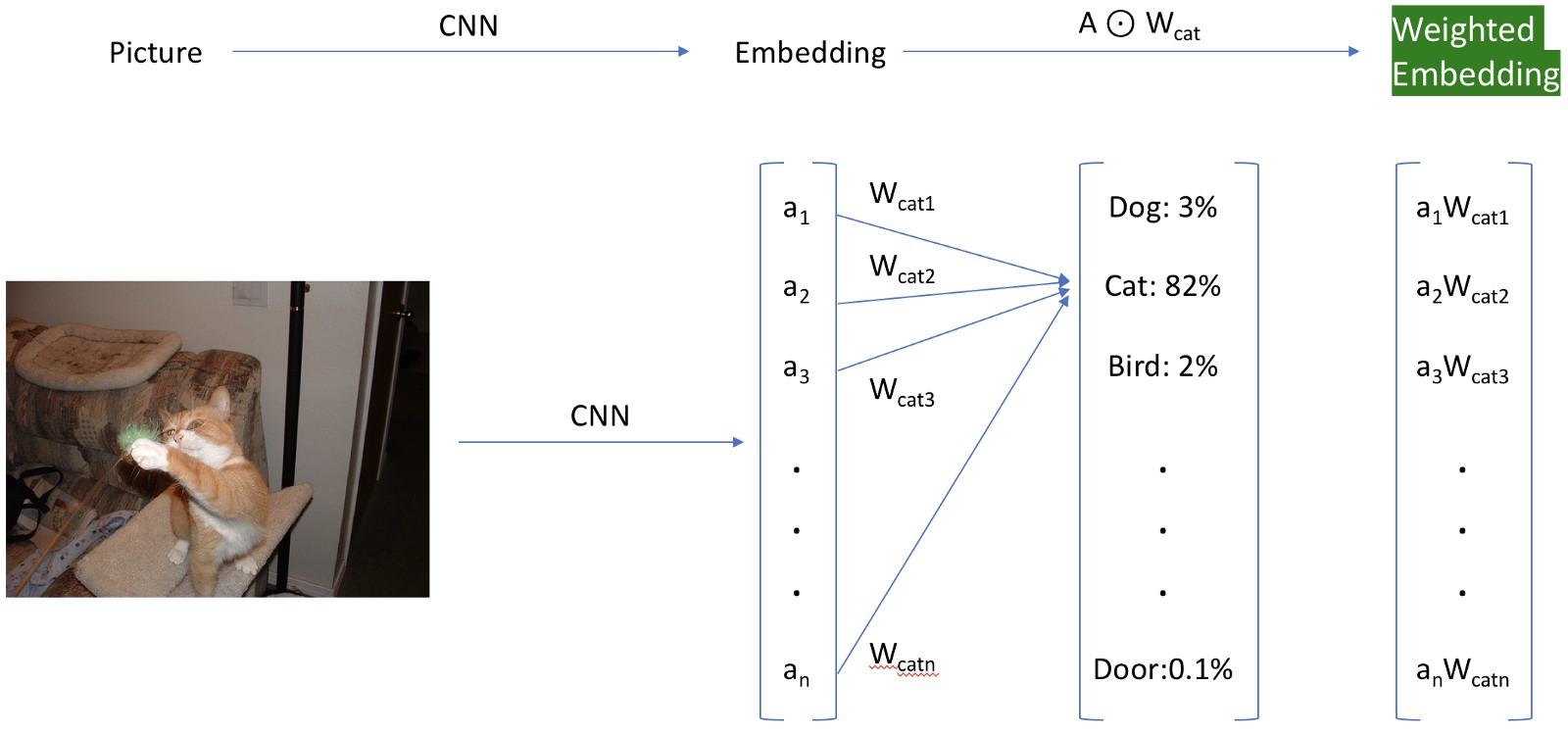
快速获得加权嵌入,分类层仅供参考.
根据 Imagenet 中的第 284 类 Siamese cat 来给嵌入表示的激活值赋予权重,以研究其工作原理.
使用加权后的特征来为 dataset/bottle/2008_000112.jpg 寻找相似的图片.

可以看出,搜索更偏向于寻找 Siamese cat-like 的 cats. 且,不再显示任何 Bottle 图片. 搜索结果很棒.
注意到,最后一张照片是一只羊!这非常有趣,原因更偏向于,训练模型导致了一种不同类型的错误,这更适合当前的数据域(数据分布).
已经看到,可以通过广泛的方式搜索类似的图像,或者通过调整训练模型所训练的特定类.
这是一个非常大的进步,但由于使用的是一个在 Imagenet 上预训练的模型,因此仅限于 1000 个 Imagenet 的类别. 这些类远非包罗万象(如,缺少一个人的类别),所以,希望找到更灵活的方式.
另外,如果是在不提供输入图像的情况下搜索猫图像呢?
对此,不仅仅使用了一些简单的技巧,还利用了一个能够理解单词语义能力的模型.
6. 文本 -> 文本
6.1 嵌入文本(Embeddings for text)
转到自然语言处理(NLP)领域,可以使用类似的方法来索引和搜索单词.
这里采用 GloVe 模型,加载预训练的向量集合,其通过爬取维基百科的所有内容并学习该数据集中单词之间的语义关系而获得的.
类似于图像的嵌入表示,这里将创建一个包含所有 GloVe 向量的索引. 然后,可以在嵌入层中搜索相似的单词.
如,搜索 said , 将会返回一个形如 [word, distance] 的列表:
- ['said', 0.0]
- ['told', 0.688713550567627]
- ['spokesman', 0.7859575152397156]
- ['asked', 0.872875452041626]
- ['noting', 0.9151610732078552]
- ['warned', 0.915908694267273]
- ['referring', 0.9276227951049805]
- ['reporters', 0.9325974583625793]
- ['stressed', 0.9445104002952576]
- ['tuesday', 0.9446316957473755]
这似乎非常合理,大多数单词在含义上与输入的原始单词非常相似,或代表一个合适的概念.
最后一个结果(tuesday)也表明这个模型远非完美,但它提供了一个好的初始化.
现在,可以尝试在训练的模型中包含单词和图像.
6.2 一个相当大的问题
使用嵌入层之间的向量距离作为搜索方法是一种非常通用的方法,但会让单词和图像的向量表示看起来似乎并不兼容.
图像的嵌入层大小为 4096,而单词的嵌入大小为 300. 如何使用一个来搜索另一个?
此外,即使两个嵌入层都是相同的大小,它们也会以完全不同的方式进行训练,因此图像和与其相关的单词很可能不会随机情况下产生相同的嵌入层.
因此,需要训练一个联合模型.
7. 图像 <-> 文本
图像和文本的碰撞融合.
创建一个混合模型,实现从单词到图像,图像到单词.
本文开始中,从一篇名为 DeViSE 的优秀论文中汲取了灵感,训练定义的模型. 虽然高度借鉴了这篇论文的主要想法,但并不会完整的重新实现(对于另一篇略有不同的论文,请查看 fast.ai 在 lesson 11. 的实现).
想法: 综合通过重新训练得到的图像模型的表示和改变其标签.
通常情况下,图像分类器被训练为从许多类中选择一个类别(Imagenet 的 1000 个种类). 以 Imagenet 为例,网络最后一层是 1000 维向量,分别表示每个类别的概率. 这意味着训练的模型没有语义理解哪些类与其他类相似:将 cat 的图像识别为 dog 将会导致与将其识别为 airplane 一样多的错误.
对于创建的混合模型,采用已知类别的词向量替换模型的最后一层. 以学习图像的语义映射到单词语义的信息,且意,类似的类将彼此更接近(因为 cat 的词向量比 airplane 更靠近 dog).
模型将预测一个大小为 300 维的语义丰富的词向量,而不是除了一个为1,其它均为 0,大小为 1000 维的向量.
通过添加两个全连接层来实现此目的:
- 一个大小为 2000 的中间层.
- 一个大小为 300 的输出层(GloVe 的词向量的大小).
Imagenet 数据集的 VGG16 模型:

定义的新模型:
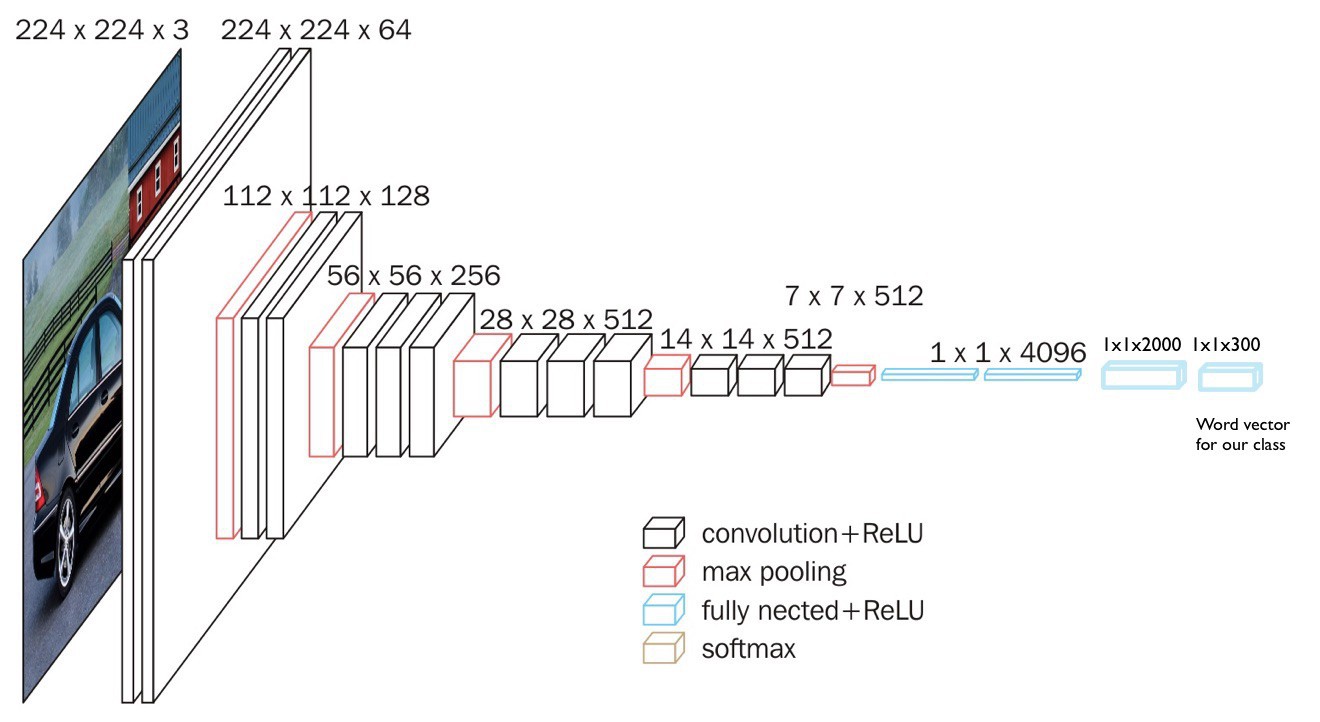
8. 模型训练
在数据集分割的训练集上重新训练定义的模型,以学习预测与图像标签相关联的词向量.
例如,对于一张属于类别 cat 的图像,尝试预测与 cat 相关联的 300 长度的词向量.
这种训练需要花费一些时间,但仍然比在 Imagenet 上快得多. 作为参考,没有 GPU 的笔记本电脑上, 需要大约 6-7 个小时.
注:这种方法有点浪费资源的. 与通常的数据集相比,在这里使用的训练数据(图像数据集的 80%,共有 800 张图像) 是比较小的,如 Imagenet 有一百万张图像,大 3 个数量级. 如果使用传统的分类训练技术,不能指望定义的模型在测试集上表现得非常好,并且肯定不会期望它在全新的示例图像上表现出色.
一旦模型训练完成,就可以获得 GloVe 的单词索引,并通过运行数据集中的所有图像,将它保存到磁盘,构建新的关于图像特征的快速索引.
8.1 Tagging
现在,只需将输入图像提供给训练的网络模型,即可轻松地从任何图像中提取标签,并保存输出成大小为 300 维的向量,并从 GloVe 中找到英语单词索引中最接近的单词.
试试这张图片——虽然它包含各种各样的物品,但它在 bottle 类中。

以下是生成的标签:
- [6676, 'bottle', 0.3879561722278595]
- [7494, 'bottles', 0.7513495683670044]
- [12780, 'cans', 0.9817070364952087]
- [16883, 'vodka', 0.9828150272369385]
- [16720, 'jar', 1.0084964036941528]
- [12714, 'soda', 1.0182772874832153]
- [23279, 'jars', 1.0454961061477661]
- [3754, 'plastic', 1.0530102252960205]
- [19045, 'whiskey', 1.061428427696228]
- [4769, 'bag', 1.0815287828445435]
这是一个非常优秀的结果,因为大多数标签都非常相关.
这种方法虽然还有很大的成长空间,但它现在已经可以很好地掌握图像中的大多数内容.
这个模型学习提取许多相关标签,甚至从那些未经过训练的类别中提取!
8.2 使用文本搜索图像
最重要的是,可以使用网络的联合嵌入层来使用任何单词搜索图像数据库.
只需从 GloVe 获取预先训练好的单词嵌入层,并找到具有最相似嵌入层的图像.
8.2.1 使用最少数据进行广义图像搜索.
首先,搜索训练集中的“dog”:

搜索 “dog"的结果
可以,相当不错的结果——但是可以从任何一个经由这些标签训练的分类器中得到这个.
搜索更困难的关键字 “ocean”,其不在训练的图片数据集中.

搜索 "ocean"的结果
这太棒了——我们的模型理解到 ocean 与 water 类似,并从 boat 类中返回了许多物品。
搜索 "street"的结果又如何呢?

搜索 "street"的结果
在这里,返回的图像来自许多不同的类别(car, dog, bicycles, bus, person),但大多数都包含或靠近街道,尽管在训练模型时从未使用过这个概念. 因为通过预先训练的词向量来利用外部知识库来学习从图像到比简单类别在语义上更丰富的向量的映射,所以得到的模型可以很好地理解外部知识.
8.3 可意会不可言传(Beyond words)
英语已经发展了很久,但还不足以为任何东西都发明一个词. 例如,在发表这篇文章时,没有英文单词用来形容"a cat lying on a sofa",这是一个输入搜索引擎的完全有效的查询. 如果想要同时搜索多个单词,可以使用一种非常简单的方法,利用词向量的算术属性(arithmetic properties of word vectors). 事实证明,总结两个词向量通常非常有效.
因此,如果只是通过使用 cat 和 sofa 的平均词向量来搜索图像,希望获得一张非常像猫,非常像沙发一样的图像,或者在沙发上有猫的图像。

获得多个单词的混合嵌入层
尝试使用这种混合嵌入层并进行搜索:

搜索"cat"+"sofa"的结果
这是一个很棒的结果,因为大多数这些图像都包含一些毛茸茸的动物和一个沙发(第二排最左边的图像,看起来像沙发旁边的一堆毛巾).
训练的模型只训练单个单词,但可以处理两个单词的组合. 虽然没有构建像谷歌搜图这样的大工程,但对于相对简单的架构来说,这绝对令人印象深刻.
这种方法实际上可以很自然地扩展到各种领域.