原文:编写基于TensorFlow的应用之构建数据pipeline - AI 人工智能平台 SigAI
原文微信公众号:SigAI (内容有质量,推荐关注.)
转载,记录备忘.
本文主要以MNIST数据集为例介绍TFRecords文件如何制作以及加载使用.
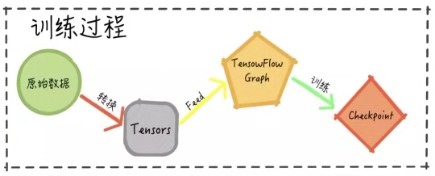
图1 典型的基于TensorFlow 的应用的workflow
通常情况下,一个基于TensorFlow 的应用训练过程中所采用的workflow 如图1 所示.
针对与原始数据的格式,首先采用不同的转换方式在运行过程中生成Tensor格式的数据,然后将其送到TensorFlow Graph中运行,根据设定的目标函数,不断的在训练数据上迭代并周期性地保存checkpoint到文件中,checkpoint文件可以用于后续的模型持久化操作.
TensorFlow框架下训练输入pipeline是一个标准的 ETL (Extract - Transform - Load)过程:
[1] - 提取数据(Extract): 从存储空间内部读取原始数据
[2] - 数据转换(Transform): 使用CPU解析原始数据并执行一些预处理的操作: 文本数据转换为数组,图片大小变换,图片数据增强操作等等
[3] - 数据加载(Load): 加载转换后的数据并传给GPU,FPGA,ASIC等加速芯片进行计算
在TensorFlow框架之下,使用 tf.dataset API 可以完成上述过程中所需的所有操作,其过程如下图所示:
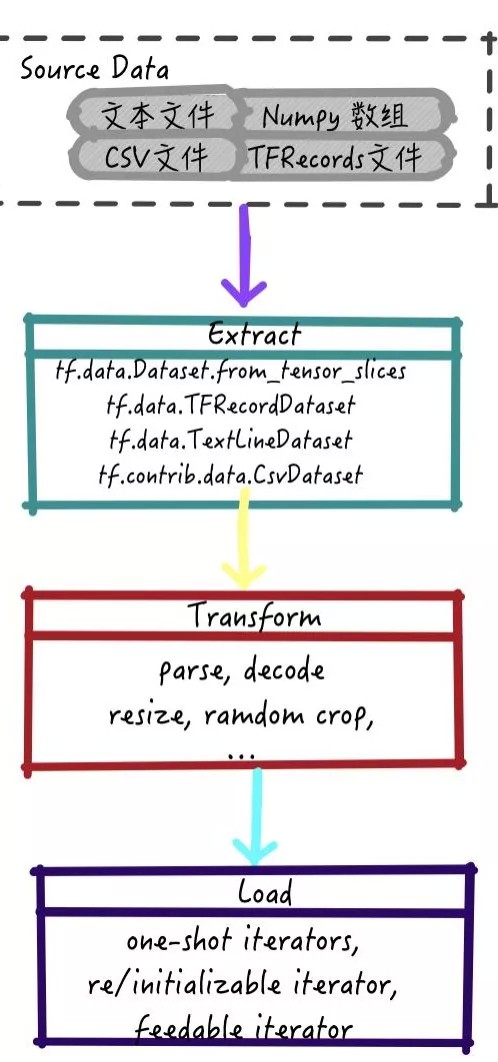
图2 TensorFlow中的ETL过程
相较于TFRecords文件,文本文件,numpy 数组, csv 文件等文件格式更为常见.
接下来,本文将以常用的MNIST数据集为例简要介绍 TFRecord 文件如何生成以及如何从TFrecord构建数据pipeline.
1. TFRecord文件简介
TFRecord文件是基于Google Protocol Buffers的一种保存数据的格式,推荐在数据预处理过程中尽可能使用这种方式将训练数据保存成这种格式.
Protocol Buffers 是一种简洁高效的序列化格式化的方法,其采用了语言无关,平台无关且可扩展的机制. 采用这种方式的优势在于:
[1] - 采用二进制格式存储,减少存储空间,提高读取效率
[2] - 针对TensorFlow框架进行优化,支持合并多个数据源,并且支持TensorFlow内置的其他数据预处理方式
[3] - 支持序列化数据的存储(时序数据或者词向量)
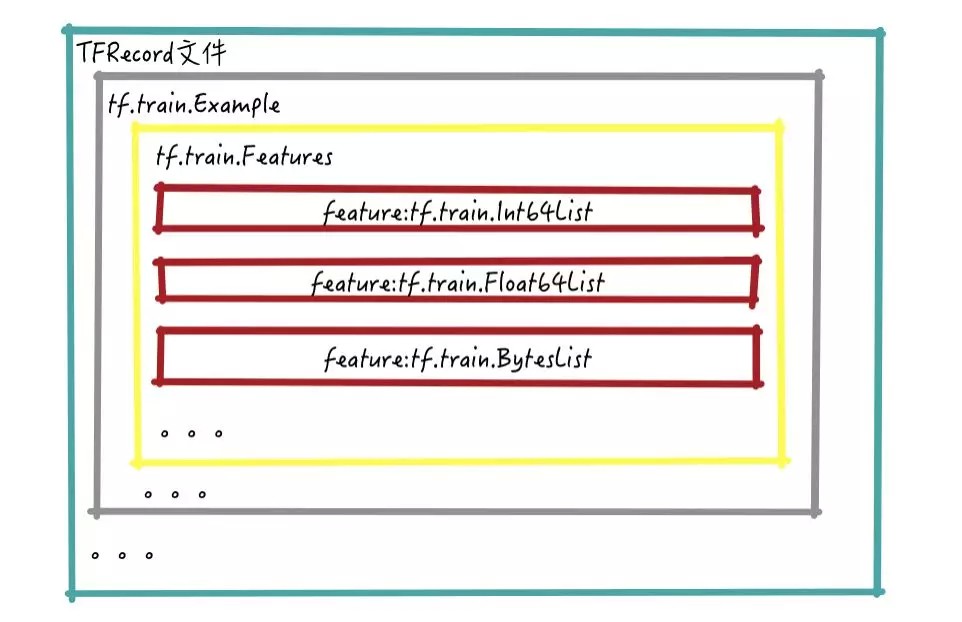
图3 TFRecord文件中存储内容结构
TFRecords中存储的层级如图3所示,从图中可以看到:
[1] - 一个TFRecord文件中包含了多个tf.train.Example, 每个 tf.train.Example 是一个Protocol Buffer
[2] - 每个tf.train.Example包含了tf.train.Features
[3] - 每个tf.train.Features是由多个feature 构成的feature set
2. 以MNIST为例生成TFRecord文件
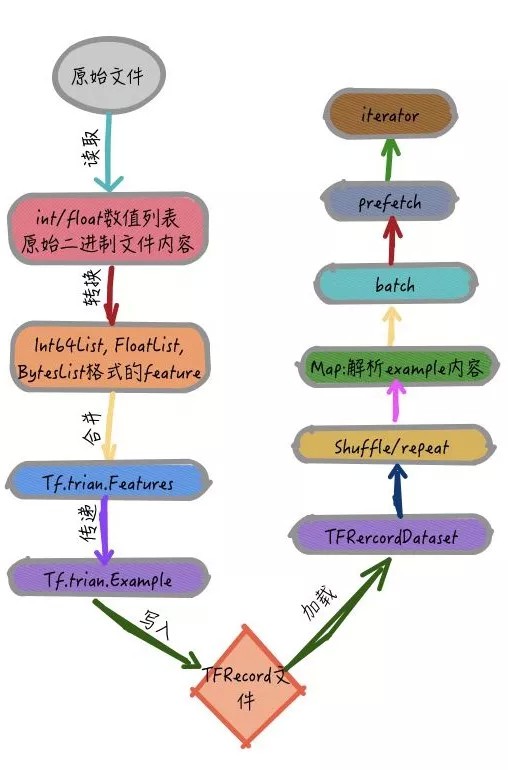
图4 TFRecord文件制作和加载过程
从原始文件生成TFRecord的过程如图4所示:
[1] - 从文件中读取数据信息,如果是类别,长度,高度等数值型数据就转换成Int64List, FloatList格式的特征,如果是图片等raw data,则直接读取其二进制编码内容,再转换成BytesList即可
[2] - 将多个特征合并为 tf.train.Features,并传递到tf.train.Example中
[3] - 最后使用TFRecordWriter写入到文件中
对于MNIST文件,从 http://yann.lecun.com/exdb/mnist/ 网站下载下来的是以二进制方式存储的数据集,这里略过下载并读取MNIST为numpy 数组的过程,有兴趣的可以查看 mnist_data.py 中的read_mnist函数.
接下来重要讲解从一个 numpy 数组到tfrecord文件需要执行的主要步骤:
[1] - 对于整个数组,需要遍历整个数组并依次将其转换成一个tf.train.Example
with TFRecordWriter(output_file) as writer:
for (img, label) in tqdm(zip(imgs, labels)):
mnist_example = feature_to_example(img, label)
writer.write(mnist_example.SerializeToString())[2] - 对于每个图片来说,需要做如下转换
def feature_to_example(img, label):
"""
convert numpy array to a `tf.train.example`
Args:
img : An `np.ndarray`. Img in numpy array format
label : An `np.int32`. label of the image
"""
# convert raw data corresponding to the numpy array in memory into pytho bytes
img = img.tostring()
return tf.train.Example(
features=tf.train.Features(
feature={'img': bytes_feature(img),
'label': int_feature(label)
}
)
)这其中使用到的 bytes_feature 和 int_feature 分别是用来将图片和标签转换成二进制的 feature 和 int 列表的特征的函数.
def int_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))[3] - 在使用SerializeToString函数将protocol buffer中的内容序列化之后, 将其内容写入到文件中.
至此,MNIST的tfrecord文件就制作完成了.
由于MNIST中涉及到的特征仅有数组和标签两类内容,如果使用TensorFlow过程中可能会遇到的其他数据格式,建议参考 https://github.com/tensorflow/models/blob/master/research/object_detection/dataset_tools/create_pascal_tf_record.py 文件编写适合自己数据集内容的函数.
3. 加载TFRecord文件并构建数据pipeline
从图4中,可以看到加载一个TFRrecord文件需要执行的步骤,其过程中使用了TensorFlow dataset类提供的函数:
[1] - shuffle:打乱输入数据的顺序
[2] - repeat: 重复数据集内容若干次
[3] - map: 对数据集中的每个数据使用map函数中传入的方法进行变换,这个过程中可以包含解析tf.train.Example内容,数据归一化以及data augmentation等其他操作
[4] - batch: 根据需要设置每次训练采用多少数据
[5] - prefetch:提前加载n个数据,保证每个session运行之前数据是可以立即使用的.
在 mnist_tfrecords.py 文件中有两个不同的加载数据的方式,建议使用第二种优化过的加载方式,其优点在于:
[1] - shuffle_and_repeat 可以保证加载数据的速度以及确保数据之间的顺序正确
[2] - map_and_batch 整合了map和batch 过程,提高了效率
经过优化过的加载TFRecord文件函数如下:
def load_data_optimized(cache_dir='data/cache',
split='train',
batch_size=64,
epochs_between_evals=3):
tfrecord_file = os.path.join(cache_dir,
'mnist_{}.tfrecord'.format(split))
# load the tfrecord data
dataset = tf.data.TFRecordDataset(tfrecord_file)
# shuffle and repeat data
if split == 'train':
dataset = dataset.apply(shuffle_and_repeat(60000, epochs_between_evals))
else:
dataset = dataset.apply(shuffle_and_repeat(10000, epochs_between_evals))
# fuse map and batch
dataset = dataset.apply(map_and_batch(parse_example,
batch_size=batch_size,
drop_remainder=True,
num_parallel_calls=8))
dataset = dataset.prefetch(1)
return dataset在SIGAI提供的实验过程中,验证读取数据的内容如下图所示:
# make one shot iterator to create access to elements for data
mnist_iter = mnist.make_on_shot_iterator()
# 获取一个 batch 的数据内容
imgs, labels = mnist_iter.get_next()
# 转换 EagerTensor 为 numpy 数组
# 从 [-1.0, 1.0] 到 [0, 255]
img_content = (imgs.numpy() + 1.0)*255.0/2
# 将一维图片向量转换为二维数组
img_content = np.reshape(img_content, (-1, 28, 28))
# 将一个 batch 内的所有图片拼接在一起
img_merged = grid_imgs(img_content, grid_size=10)
# 将 numpy 数组转换为图片
img_viz = Image.fromarray(np.uint8(img_merged), mode='L')
# 可视化图片
img_viz.show()
本文主要介绍了TFRecord文件,然后以MNIST数据集为例讲解了如何制作MNIST数据集的TFRecord文件,接着讲述了如何加载文件并构建数据 pipeline.
4.create_pascal_tf_record.py
https://github.com/tensorflow/models/blob/master/research/object_detection/dataset_tools/create_pascal_tf_record.py
create__pascal_tf_record.py 用法:
python object_detection/dataset_tools/create_pascal_tf_record.py \
--data_dir=/home/user/VOCdevkit \
--year=VOC2012 \
--output_path=/home/user/pascal.record"""
Convert raw PASCAL dataset to TFRecord for object_detection.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import hashlib
import io
import logging
import os
from lxml import etree
import PIL.Image
import tensorflow as tf
from object_detection.utils import dataset_util
from object_detection.utils import label_map_util
flags = tf.app.flags
flags.DEFINE_string('data_dir', '',
'Root directory to raw PASCAL VOC dataset.')
flags.DEFINE_string('set', 'train',
'Convert training set, validation set or merged set.')
flags.DEFINE_string('annotations_dir', 'Annotations',
'(Relative) path to annotations directory.')
flags.DEFINE_string('year', 'VOC2007', 'Desired challenge year.')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
flags.DEFINE_string('label_map_path', 'data/pascal_label_map.pbtxt',
'Path to label map proto')
flags.DEFINE_boolean('ignore_difficult_instances', False,
'Whether to ignore difficult instances')
FLAGS = flags.FLAGS
SETS = ['train', 'val', 'trainval', 'test']
YEARS = ['VOC2007', 'VOC2012', 'merged']
def dict_to_tf_example(data,
dataset_directory,
label_map_dict,
ignore_difficult_instances=False,
image_subdirectory='JPEGImages'):
"""
Convert XML derived dict to tf.Example proto.
Notice that this function normalizes the bounding box coordinates provided
by the raw data.
Args:
data: dict holding PASCAL XML fields for a single image (obtained by
running dataset_util.recursive_parse_xml_to_dict)
dataset_directory: Path to root directory holding PASCAL dataset
label_map_dict: A map from string label names to integers ids.
ignore_difficult_instances: Whether to skip difficult instances in the
dataset (default: False).
image_subdirectory: String specifying subdirectory within the
PASCAL dataset directory holding the actual image data.
Returns:
example: The converted tf.Example.
Raises:
ValueError: if the image pointed to by data['filename'] is not a valid JPEG
"""
img_path = os.path.join(data['folder'], image_subdirectory, data['filename'])
full_path = os.path.join(dataset_directory, img_path)
with tf.gfile.GFile(full_path, 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = PIL.Image.open(encoded_jpg_io)
if image.format != 'JPEG':
raise ValueError('Image format not JPEG')
key = hashlib.sha256(encoded_jpg).hexdigest()
width = int(data['size']['width'])
height = int(data['size']['height'])
xmin = []
ymin = []
xmax = []
ymax = []
classes = []
classes_text = []
truncated = []
poses = []
difficult_obj = []
if 'object' in data:
for obj in data['object']:
difficult = bool(int(obj['difficult']))
if ignore_difficult_instances and difficult:
continue
difficult_obj.append(int(difficult))
xmin.append(float(obj['bndbox']['xmin']) / width)
ymin.append(float(obj['bndbox']['ymin']) / height)
xmax.append(float(obj['bndbox']['xmax']) / width)
ymax.append(float(obj['bndbox']['ymax']) / height)
classes_text.append(obj['name'].encode('utf8'))
classes.append(label_map_dict[obj['name']])
truncated.append(int(obj['truncated']))
poses.append(obj['pose'].encode('utf8'))
example = tf.train.Example(
features=tf.train.Features(
feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/source_id': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/key/sha256': dataset_util.bytes_feature(key.encode('utf8')),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmin),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmax),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymin),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymax),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
'image/object/difficult': dataset_util.int64_list_feature(difficult_obj),
'image/object/truncated': dataset_util.int64_list_feature(truncated),
'image/object/view': dataset_util.bytes_list_feature(poses),
}
)
)
return example
def main(_):
if FLAGS.set not in SETS:
raise ValueError('set must be in : {}'.format(SETS))
if FLAGS.year not in YEARS:
raise ValueError('year must be in : {}'.format(YEARS))
data_dir = FLAGS.data_dir
years = ['VOC2007', 'VOC2012']
if FLAGS.year != 'merged':
years = [FLAGS.year]
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
label_map_dict = label_map_util.get_label_map_dict(FLAGS.label_map_path)
for year in years:
logging.info('Reading from PASCAL %s dataset.', year)
examples_path = os.path.join(data_dir, year, 'ImageSets', 'Main',
'aeroplane_' + FLAGS.set + '.txt')
annotations_dir = os.path.join(data_dir, year, FLAGS.annotations_dir)
examples_list = dataset_util.read_examples_list(examples_path)
for idx, example in enumerate(examples_list):
if idx % 100 == 0:
logging.info('On image %d of %d', idx, len(examples_list))
path = os.path.join(annotations_dir, example + '.xml')
with tf.gfile.GFile(path, 'r') as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = dataset_util.recursive_parse_xml_to_dict(xml)['annotation']
tf_example = dict_to_tf_example(data,
FLAGS.data_dir,
label_map_dict,
FLAGS.ignore_difficult_instances)
writer.write(tf_example.SerializeToString())
writer.close()
if __name__ == '__main__':
tf.app.run()