Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Inception V4 网络结构:
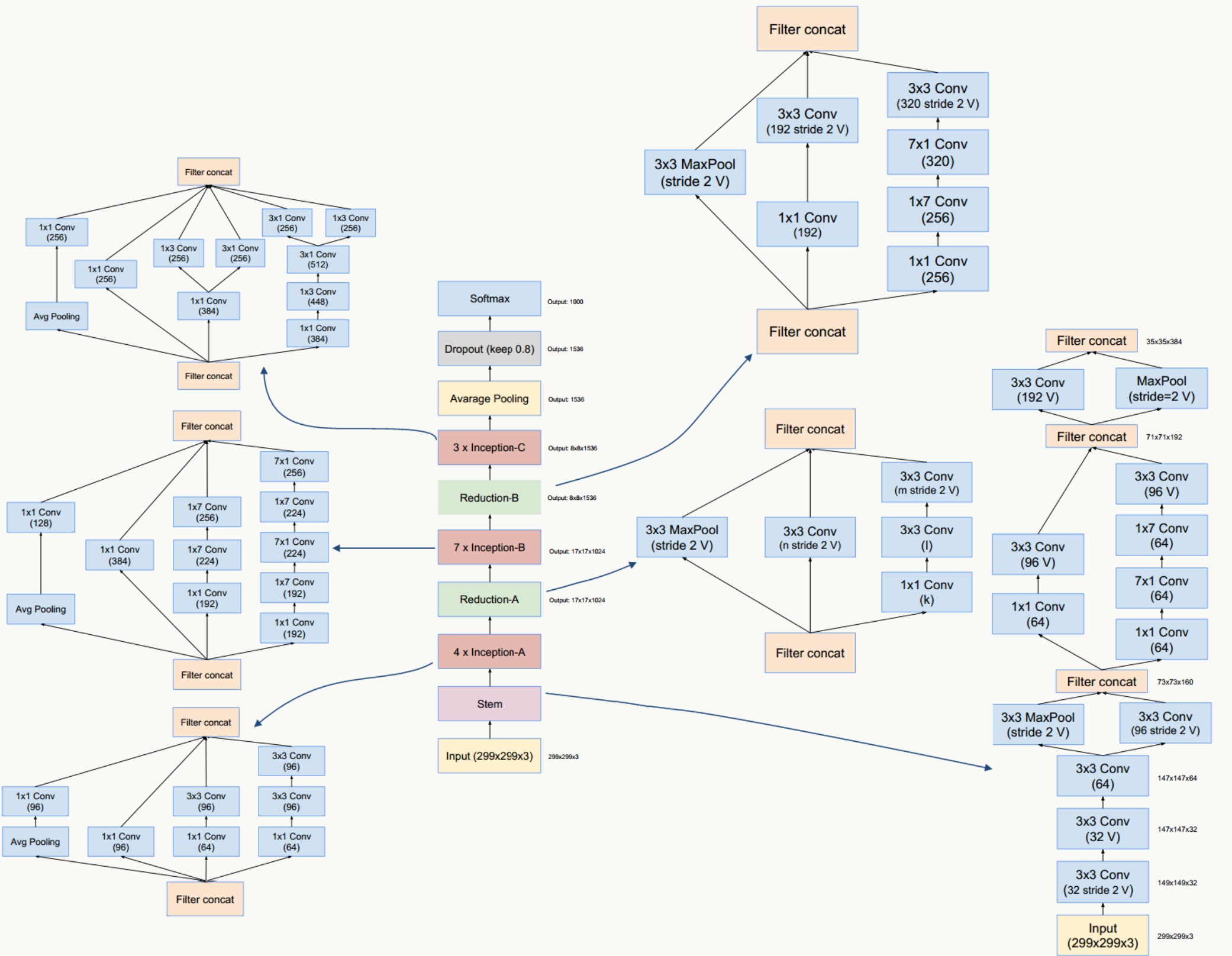
From 【深度学习系列】用PaddlePaddle和Tensorflow实现GoogLeNet InceptionV2/V3/V4

Figure 7 中的,k=192, l=224, m=256, n=384
Tensorflow Slim 的 Inception V4 定义
inception v4
"""
Inception V4 网络结构定义.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
from nets import inception_utils
slim = tf.contrib.slim
def block_inception_a(inputs, scope=None, reuse=None):
"""
Inception V4 的 Inception-A 模块.
"""
# By default use stride=1 and SAME padding
with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
stride=1, padding='SAME'):
with tf.variable_scope(scope, 'BlockInceptionA', [inputs], reuse=reuse):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(inputs, 96, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(inputs, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], scope='Conv2d_0b_3x3')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(inputs, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0b_3x3')
branch_2 = slim.conv2d(branch_2, 96, [3, 3], scope='Conv2d_0c_3x3')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(inputs, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 96, [1, 1], scope='Conv2d_0b_1x1')
return tf.concat(axis=3, values=[branch_0, branch_1, branch_2, branch_3])
def block_reduction_a(inputs, scope=None, reuse=None):
"""
Inception V4 的 Reduction-A 模块.
"""
# By default use stride=1 and SAME padding
with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
stride=1, padding='SAME'):
with tf.variable_scope(scope, 'BlockReductionA', [inputs], reuse=reuse):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(inputs, 384, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(inputs, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 224, [3, 3], scope='Conv2d_0b_3x3')
branch_1 = slim.conv2d(branch_1, 256, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_2'):
branch_2 = slim.max_pool2d(inputs, [3, 3], stride=2, padding='VALID',
scope='MaxPool_1a_3x3')
return tf.concat(axis=3, values=[branch_0, branch_1, branch_2])
def block_inception_b(inputs, scope=None, reuse=None):
"""
Inception V4 的 Inception-B 模块.
"""
# By default use stride=1 and SAME padding
with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
stride=1, padding='SAME'):
with tf.variable_scope(scope, 'BlockInceptionB', [inputs], reuse=reuse):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(inputs, 384, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(inputs, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 224, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 256, [7, 1], scope='Conv2d_0c_7x1')
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(inputs, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 192, [7, 1], scope='Conv2d_0b_7x1')
branch_2 = slim.conv2d(branch_2, 224, [1, 7], scope='Conv2d_0c_1x7')
branch_2 = slim.conv2d(branch_2, 224, [7, 1], scope='Conv2d_0d_7x1')
branch_2 = slim.conv2d(branch_2, 256, [1, 7], scope='Conv2d_0e_1x7')
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(inputs, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 128, [1, 1], scope='Conv2d_0b_1x1')
return tf.concat(axis=3, values=[branch_0, branch_1, branch_2, branch_3])
def block_reduction_b(inputs, scope=None, reuse=None):
"""
Inception V4 的 Reduction-B 模块.
"""
# By default use stride=1 and SAME padding
with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
stride=1, padding='SAME'):
with tf.variable_scope(scope, 'BlockReductionB', [inputs], reuse=reuse):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(inputs, 192, [1, 1], scope='Conv2d_0a_1x1')
branch_0 = slim.conv2d(branch_0, 192, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(inputs, 256, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 256, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 320, [7, 1], scope='Conv2d_0c_7x1')
branch_1 = slim.conv2d(branch_1, 320, [3, 3], stride=2,
padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_2'):
branch_2 = slim.max_pool2d(inputs, [3, 3], stride=2, padding='VALID',
scope='MaxPool_1a_3x3')
return tf.concat(axis=3, values=[branch_0, branch_1, branch_2])
def block_inception_c(inputs, scope=None, reuse=None):
"""
Inception V4 的 Reduction-C 模块.
"""
# By default use stride=1 and SAME padding
with slim.arg_scope([slim.conv2d, slim.avg_pool2d, slim.max_pool2d],
stride=1, padding='SAME'):
with tf.variable_scope(scope, 'BlockInceptionC', [inputs], reuse=reuse):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(inputs, 256, [1, 1], scope='Conv2d_0a_1x1')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(inputs, 384, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = tf.concat(axis=3, values=[
slim.conv2d(branch_1, 256, [1, 3], scope='Conv2d_0b_1x3'),
slim.conv2d(branch_1, 256, [3, 1], scope='Conv2d_0c_3x1')])
with tf.variable_scope('Branch_2'):
branch_2 = slim.conv2d(inputs, 384, [1, 1], scope='Conv2d_0a_1x1')
branch_2 = slim.conv2d(branch_2, 448, [3, 1], scope='Conv2d_0b_3x1')
branch_2 = slim.conv2d(branch_2, 512, [1, 3], scope='Conv2d_0c_1x3')
branch_2 = tf.concat(axis=3, values=[
slim.conv2d(branch_2, 256, [1, 3], scope='Conv2d_0d_1x3'),
slim.conv2d(branch_2, 256, [3, 1], scope='Conv2d_0e_3x1')])
with tf.variable_scope('Branch_3'):
branch_3 = slim.avg_pool2d(inputs, [3, 3], scope='AvgPool_0a_3x3')
branch_3 = slim.conv2d(branch_3, 256, [1, 1], scope='Conv2d_0b_1x1')
return tf.concat(axis=3, values=[branch_0, branch_1, branch_2, branch_3])
def inception_v4_base(inputs, final_endpoint='Mixed_7d', scope=None):
"""
给定网络最终节点 final_endpoint,Inception V4 网络创建.
Args:
inputs: a 4-D tensor of size [batch_size, height, width, 3].
final_endpoint: specifies the endpoint to construct the network up to.
It can be one of [ 'Conv2d_1a_3x3', 'Conv2d_2a_3x3', 'Conv2d_2b_3x3',
'Mixed_3a', 'Mixed_4a', 'Mixed_5a', 'Mixed_5b', 'Mixed_5c', 'Mixed_5d',
'Mixed_5e', 'Mixed_6a', 'Mixed_6b', 'Mixed_6c', 'Mixed_6d', 'Mixed_6e',
'Mixed_6f', 'Mixed_6g', 'Mixed_6h', 'Mixed_7a', 'Mixed_7b', 'Mixed_7c',
'Mixed_7d']
scope: Optional variable_scope.
Returns:
logits: the logits outputs of the model.
end_points: the set of end_points from the inception model.
Raises:
ValueError: if final_endpoint is not set to one of the predefined values,
"""
end_points = {}
def add_and_check_final(name, net):
end_points[name] = net
return name == final_endpoint
with tf.variable_scope(scope, 'InceptionV4', [inputs]):
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='SAME'):
# 299 x 299 x 3
net = slim.conv2d(inputs, 32, [3, 3], stride=2, padding='VALID', scope='Conv2d_1a_3x3')
if add_and_check_final('Conv2d_1a_3x3', net): return net, end_points
# 149 x 149 x 32
net = slim.conv2d(net, 32, [3, 3], padding='VALID', scope='Conv2d_2a_3x3')
if add_and_check_final('Conv2d_2a_3x3', net): return net, end_points
# 147 x 147 x 32
net = slim.conv2d(net, 64, [3, 3], scope='Conv2d_2b_3x3')
if add_and_check_final('Conv2d_2b_3x3', net): return net, end_points
# 147 x 147 x 64
with tf.variable_scope('Mixed_3a'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID', scope='MaxPool_0a_3x3')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 96, [3, 3], stride=2, padding='VALID', scope='Conv2d_0a_3x3')
net = tf.concat(axis=3, values=[branch_0, branch_1])
if add_and_check_final('Mixed_3a', net): return net, end_points
# 73 x 73 x 160
with tf.variable_scope('Mixed_4a'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_0 = slim.conv2d(branch_0, 96, [3, 3], padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_1'):
branch_1 = slim.conv2d(net, 64, [1, 1], scope='Conv2d_0a_1x1')
branch_1 = slim.conv2d(branch_1, 64, [1, 7], scope='Conv2d_0b_1x7')
branch_1 = slim.conv2d(branch_1, 64, [7, 1], scope='Conv2d_0c_7x1')
branch_1 = slim.conv2d(branch_1, 96, [3, 3], padding='VALID', scope='Conv2d_1a_3x3')
net = tf.concat(axis=3, values=[branch_0, branch_1])
if add_and_check_final('Mixed_4a', net): return net, end_points
# 71 x 71 x 192
with tf.variable_scope('Mixed_5a'):
with tf.variable_scope('Branch_0'):
branch_0 = slim.conv2d(net, 192, [3, 3], stride=2, padding='VALID', scope='Conv2d_1a_3x3')
with tf.variable_scope('Branch_1'):
branch_1 = slim.max_pool2d(net, [3, 3], stride=2, padding='VALID', scope='MaxPool_1a_3x3')
net = tf.concat(axis=3, values=[branch_0, branch_1])
if add_and_check_final('Mixed_5a', net): return net, end_points
# 35 x 35 x 384
# 4 x Inception-A blocks
for idx in range(4):
block_scope = 'Mixed_5' + chr(ord('b') + idx)
net = block_inception_a(net, block_scope)
if add_and_check_final(block_scope, net): return net, end_points
# 35 x 35 x 384
# Reduction-A block
net = block_reduction_a(net, 'Mixed_6a')
if add_and_check_final('Mixed_6a', net): return net, end_points
# 17 x 17 x 1024
# 7 x Inception-B blocks
for idx in range(7):
block_scope = 'Mixed_6' + chr(ord('b') + idx)
net = block_inception_b(net, block_scope)
if add_and_check_final(block_scope, net): return net, end_points
# 17 x 17 x 1024
# Reduction-B block
net = block_reduction_b(net, 'Mixed_7a')
if add_and_check_final('Mixed_7a', net): return net, end_points
# 8 x 8 x 1536
# 3 x Inception-C blocks
for idx in range(3):
block_scope = 'Mixed_7' + chr(ord('b') + idx)
net = block_inception_c(net, block_scope)
if add_and_check_final(block_scope, net): return net, end_points
raise ValueError('Unknown final endpoint %s' % final_endpoint)
def inception_v4(inputs, num_classes=1001, is_training=True,
dropout_keep_prob=0.8,
reuse=None,
scope='InceptionV4',
create_aux_logits=True):
"""
创建 Inception V4 模型.
Args:
inputs: a 4-D tensor of size [batch_size, height, width, 3].
num_classes: number of predicted classes. If 0 or None, the logits layer
is omitted and the input features to the logits layer (before dropout)
are returned instead.
is_training: whether is training or not.
dropout_keep_prob: float, the fraction to keep before final layer.
reuse: whether or not the network and its variables should be reused. To be
able to reuse 'scope' must be given.
scope: Optional variable_scope.
create_aux_logits: Whether to include the auxiliary logits.
Returns:
net: a Tensor with the logits (pre-softmax activations) if num_classes
is a non-zero integer, or the non-dropped input to the logits layer
if num_classes is 0 or None.
end_points: the set of end_points from the inception model.
"""
end_points = {}
with tf.variable_scope(scope, 'InceptionV4', [inputs], reuse=reuse) as scope:
with slim.arg_scope([slim.batch_norm, slim.dropout],
is_training=is_training):
net, end_points = inception_v4_base(inputs, scope=scope)
with slim.arg_scope([slim.conv2d, slim.max_pool2d, slim.avg_pool2d],
stride=1, padding='SAME'):
# Auxiliary Head logits
if create_aux_logits and num_classes:
with tf.variable_scope('AuxLogits'):
# 17 x 17 x 1024
aux_logits = end_points['Mixed_6h']
aux_logits = slim.avg_pool2d(aux_logits, [5, 5], stride=3,
padding='VALID',
scope='AvgPool_1a_5x5')
aux_logits = slim.conv2d(aux_logits, 128, [1, 1],
scope='Conv2d_1b_1x1')
aux_logits = slim.conv2d(aux_logits, 768,
aux_logits.get_shape()[1:3],
padding='VALID', scope='Conv2d_2a')
aux_logits = slim.flatten(aux_logits)
aux_logits = slim.fully_connected(aux_logits, num_classes,
activation_fn=None,
scope='Aux_logits')
end_points['AuxLogits'] = aux_logits
# Final pooling and prediction
# TODO(sguada,arnoegw): Consider adding a parameter global_pool which
# can be set to False to disable pooling here (as in resnet_*()).
with tf.variable_scope('Logits'):
# 8 x 8 x 1536
kernel_size = net.get_shape()[1:3]
if kernel_size.is_fully_defined():
net = slim.avg_pool2d(net, kernel_size, padding='VALID',
scope='AvgPool_1a')
else:
net = tf.reduce_mean(net, [1, 2], keep_dims=True,
name='global_pool')
end_points['global_pool'] = net
if not num_classes:
return net, end_points
# 1 x 1 x 1536
net = slim.dropout(net, dropout_keep_prob, scope='Dropout_1b')
net = slim.flatten(net, scope='PreLogitsFlatten')
end_points['PreLogitsFlatten'] = net
# 1536
logits = slim.fully_connected(net, num_classes, activation_fn=None,
scope='Logits')
end_points['Logits'] = logits
end_points['Predictions'] = tf.nn.softmax(logits, name='Predictions')
return logits, end_points
inception_v4.default_image_size = 299
inception_v4_arg_scope = inception_utils.inception_arg_scope