原文:业界 | 实时替换视频背景:谷歌展示全新移动端分割技术 - 机器之心公众号
英文原文:Mobile Real-time Video Segmentation - Google AI Blog
转载,备忘学习.为视频中人物实时替换背景的技术能够催生出很多新类型的应用。
谷歌最近提出的机器学习视频分割技术首先被应用在了自家的 YouTube app 上,实现了令人惊艳的效果. 同时,由于模型被高度压缩,其在 iPhone 7 这样的移动端设备上也可以达到 100+ FPS 的高帧率.
视频分割是一项广泛使用的技术,电影导演和视频内容创作者可以用该技术将场景中的前景从背景中分离出来,并将两者作为两个不同的视觉层. 通过修改或替换背景,创作者可以表达特定的情绪、将人放在有趣的位置或强化信息的冲击力.
然而,这项技术的执行在传统上是相当耗时的手工过程 (例如,对每一帧图像抠图),或者需要利用带绿幕的摄影棚环境以满足实时背景移除.
为了让用户能用摄像头实时创造这种效果,谷歌为手机设计了这种实时抠图技术.
今天,通过将该技术整合到 stories,谷歌宣布将给 YouTube app 带来精确、实时、便携的移动视频分割体验.
目前仅限于测试版本,stories 是 YouTube 的新轻量视频格式,是特别为 YouTube 创作者而设计的.该新型分割技术不需要专业设备,让创作者能方便地替换和修改背景,从而轻易地提高视频的制作水准.

在 YouTube stories 中实现神经网络视频分割.
谷歌使用机器学习的卷积神经网络来解决语义分割任务,从而实现该技术. 特别地,通过满足以下的需求和约束,研究人员设计了适合手机的网络架构和训练流程:
- 移动端的解决方案必须是轻量级的,并至少达到当前最佳照片分割模型的 10-30 倍的分割速度. 对于实时推断,这样的模型需要达到每秒 30 帧的分割速度.
- 视频模型需要利用时间冗余度(相邻帧看起来相似),和具备时间一致性(相邻帧得到相似的结果).
- 高质量的分割结果需要高质量的标注.
数据集
研究人员标注了成千上万张捕捉了广泛类型的前景姿态和背景环境的图像,以为新的机器学习流程提供高质量的数据. 这些标注包括前景元素的像素级精确定位,例如头发、眼镜、脖子、皮肤、嘴唇等;而背景标签普遍能达到人类标注质量的 98%(IOU、Intersection-Over-Union)的交叉验证结果.

示例图中,研究人员仔细地标注了 9 个标签,前景元素按不同颜色的色块分割.
网络输入
谷歌设计的分割任务是为每个视频的输入帧(三通道,RGB)计算二进制掩码Mask,以将前景从背景上分割出来. 其中,获得计算掩码在帧上的时间一致性是关键.
当前的方法是使用 LSTM 或 GRUs 来实现,但对于在移动设备上实时应用来说其计算开销太高了.
因此,我们首先将前一帧的计算掩码Mask作为先验知识,并作为第四个通道结合当前的 RGB 输入帧,以获得时间一致性,如下图所示:
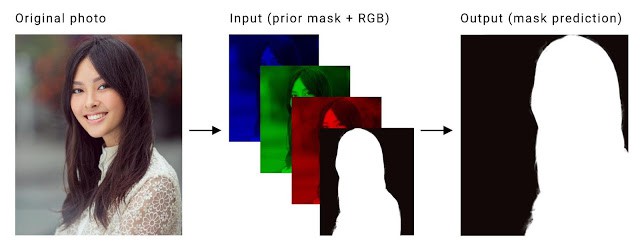
原本的帧(左)分离为三种色彩通道,并且和之前的掩码mask 级联在一起(中). 这就可以用做输入来训练神经网络而预测当前帧的掩码(右).
训练过程
在视频分割中,我们需要实现帧到帧的时间连续性,同时也需要考虑时间的不连续性,例如突然出现在相机镜头前的人.
为了鲁棒地训练模型而解决这些问题,我们需要以多种方式转换每张图片的标注真值,并将其作为前一帧的掩码:
- 清空前面的掩码Mask:训练网络已正确处理第一帧和场景中的新目标,这将模拟某人出现在相机镜头内的场景.
- 标注真值掩码Mask的仿射变换:根据 Minor 转换训练神经网络以传播和调整前一帧的掩码Mask,而 Major 转换训练网络以理解不合适的掩码,并丢弃它们.
- 转换后的图像:谷歌实现了原版图像的薄板样条平滑(thin plate spline smoothing) 以加快相机的移动和旋转.

实时视频分割.
网络架构
通过修正后的输入、输出,研究人员构建了一个标准的沙漏型分割网络(hourglass segmentation network)架构,并增加了以下改进:
- 在新方法中,研究人员通过使用有较大步长(strides=4)的大卷积核以检测高分辨率 RGB 输入帧的目标特征. 卷积层有较少的通道数(在 RGB 作为输入的情况下)从而节约了算力,因此使用较大的卷积核也不会有很大的计算成本.
为了提高速度,研究人员通过较大步幅而积极地采用下采样,并结合跳过连接(如 U-Net) 以在上采样中恢复低级特征. 对于新的分割模型,它相比于不使用跳过连接的模型要提升 5% 的 IOU.
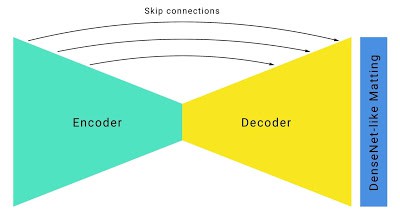
Hourglass 分割网络 w/ skip 连接为进一步提高速度,谷歌研究人员优化了默认 ResNet 瓶颈. 在 ResNet 论文 - Deep Residual Learning for Image Recognition 中,作者将网络中间信道压缩四倍(即将 256 信道通过 64 个不同的卷积核压缩为 64 个). 然而,研究人员注意到在更为激进地压缩至 16 或 32 个信道后,质量并没有显著下降.
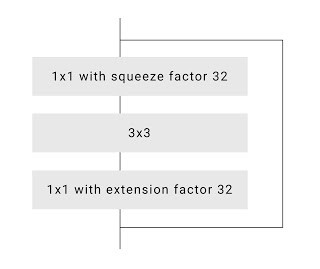
ResNet 瓶颈和大压缩率为了细化和提高边缘的准确性,谷歌研究人员为神经网络上层加入了一些 DenseNet 层,其分辨率与 Neual Matting (论文Deep Image Matting) 相同. 这种技术让模型的整体质量提高了 0.5% IOU,但却显著提高了分割的质量.
这些修改的最终结果是新的神经网络速度很快,并适用于移动端设备. 使用高准确率设置时(在验证数据集上达到 94.8% IOU),它在 iPhone 7 上可以达到 100+ FPS,而在 Pixel 2 上可以达到 40+ FPS,在 YouTube stories 中能够提供各种平滑的展示效果.

谷歌下一步的目标是使用 YouTube 中的 stories 来测试新技术的效果.
随着新方法的改进和扩展,这种分割技术将会适用于更多场景,谷歌计划在未来将其应用于增强现实服务中.
Related
[1] - Portrait mode on the Pixel 2 and Pixel 2 XL smartphones - Google AI Blog
[2] - Semantic Image Segmentation with DeepLab in TensorFlow - Google AI Blog