粗略理解了一下 Deep Image Matting,CVPR2017,对应的代码实现 - TensorFlow 实现. 该实现的过程,源码作者介绍了大致过程 - Deep Image Matting复现过程总结 这里转载,非常感谢!
博文主要组成:
[1] - 论文梳理
[2] - 创建新的训练集
[3] - 想要训练什么样的网络
[4] - 模型结构和训练技巧
[5] - 损失函数
[6] - 作者在训练过程中的技巧
[7] - 论文阅读阶段遗留的几个问题
[8] - 论文复现
[9] - 数据准备和预处理阶段
[10] - 我们有什么?
[11] - 如何整理数据?
[12] - 为什么先融合再resize会产生ground truth飘移
[13] - 训练阶段
[14] - References
1. 论文梳理
首先需要理清的是,image matting到底是用于解决什么样的问题? matting问题的核心是一个表达式:
$$I_i = \alpha_i F_i + (1 - \alpha_i) B_i, \alpha \in [0, 1] $$ (1)
即通过 alpha 控制透明度来使前景FG和背景BG融合的技术. 有不少人把deep image matting理解为’深度抠图’,其实抠图用到的是 backgournd removal 技术[1],它关注的是如何寻找确定的前景和背景,即alpha等于0和1的部分. matting 想解决的则像是如何完美的将两张图融入到一起,即 alpha 不等于1的部分(我的理解,可能有误). 认识这点对后面损失函数权重的配比至关重要.
1.1. 创建新的训练集
要以深度学习的方式来解决这个问题,就需要寻找大量的训练数据. 已经公开的 matting 领域的 benchmark - alphamatting 2 的训练集只有27张训练样本,远远达不到深度学习的要求. 作者从视频中采取了400多张图,并用PS人工抠出了它的前景图,然后将每一张图分别融合到100个不同的背景里,最后得到了49300个训练样本. (在申请作者数据的时候,得到的文件中会包含一份纠错说明,提到论文的数据有误,实际上并没有那么多).
1.2. 想要训练什么样的网络
文章想要最终实现的效果如下图: 输入原始的RGB图片和对应的trimap(确定的前景alpha=1,确定的背景alpha=0,和不确定的边缘——unknown region, alpha=0.5),输出预测的 alpha,即没有 unknown region 的 trimap.
1.3. 模型结构和训练技巧
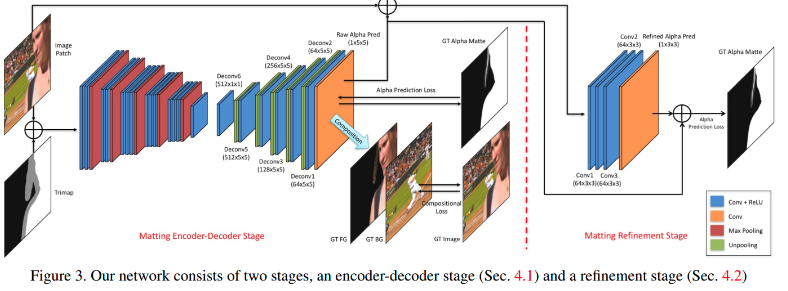
左边为典型的encoder和decoder结构,在 segmentation 和很多以图得图的GAN中比较常见. encoder 用 pre-trained的VGG16,把 fc6 从全连接换成了卷积,并在输入增加了第四通道channel4,用来存放输入的trimap,因为channel4而增加的weights全部初始化为0. decoder 用简单的 unpool 和 convolution 的组合来做 upsampling 和空间结构推断. 右边的 refine network是为了解决第一阶段预测输出边缘 blur 的情况.
1.3.1. 损失函数
损失函数为两个loss的加权组合:alpha loss 和 compositional loss. alpha loss是预测alpha和实际alpha的误差, conpositional loss 是将预测的 alpha 通过公式(1) 与相应的背景和前景融合后,与ground truth RGB图的误差. 只有trimap中 unknown region 区域的预测误差才会被反向传播(这是 matting 与 background removal的区别,matting 需要 trimap 作为用户交互接口,只需预测 matting中不确定的区域,而 backgournd removal则需要将整张图的误差反响传播),即 trimap 中为纯背景和纯前景的部分不计入模型预测范围,只需要把这两部分直接复制到输出的alpha即可.(注意误差都是pixel-wise的)
1.3.2 作者在训练过程中的技巧
[1] - 从原图中随机crop 320,480,640的训练patch,然后统一resize到320,作为网络输入(这里的操作必须对于你训练的那个样本的background,foreground,alpha同步操作)
[2] - 随机翻转(同上)
[3] - trimap 由 alpha 以随机大小 kernel 的 dilation
[4] - 操作生成
[5] - Refinement很好理解,这里不展开解释了.
1.4. 论文阅读阶段遗留的几个问题
[1] - 训练mini batch的size
[2] - crop的安全性是怎么解决的?因为以 unknown region 为中心随机crop,很可能会出现crop超出边界的情况
[3] - compositional 值的scale是0~255,而 alpha loss 的 scale 是0~1,如果不对compositional loss除以255的话,会出现loss严重倾向于compositional loss的情况
[4] - 在网络结构上是否有其他技巧,比如 PReLU,batch_normalization
2. 论文复现
2.1. 数据准备和预处理阶段
由于有来自xx公司的数据,所以实验没有建立在作者数据的基础上. 预处理阶段需要注意的很多很多,大致流程如下图:
能离线处理的数据就尽量离线处理,比如把所有的backgournd都提前整理好,具体文件夹结构的组织方式可以去看在github[5] 上上传的data_structure说明. 对这个图简单解释一下:

2.1.1. 我们有什么?
[1] - 训练数据的alpha
[2] - 训练数据的RGB(即图中的eps,这个数据是foreground的来源,需要在程序中与alpha组合产生foreground,再matting到背景上实现真正的输入RGB)
[3] background(来自 pascal voc 和 coco )
2.1.2. 如何整理数据?
[1] - 把 alpha 和 eps 都resize到最长边为640,同时保留长宽比.
[2] - 因为 crop 的最大size为 640x640,所以把 background 都 resize 到最短边为1280,同时保留长宽比.
[3] - 把 alpha 和 eps 都 center padding 到背景里,这样无论怎样 crop,只要是以 trimap 的unknown region为中心,就不会出现crop出边界的情况(另一种解决方案,不 resize 背景,直接将 alpha 和 eps center pad 进背景,假设 crop 出边界,把出界的那条边拉回来即可. 比如 crop 左边出界了,则设置 crop 左边的起始位置为0.作者应该采用的是这种方式,因为从作者分享的代码来看没有针对background做特殊操作).
前三点都是离线准备好的,即不是在网络训练的时候进行,下面的步骤都是在网络训练的时候同时进行.
[1] - 通过对 alpha 进行 random dilation 得到 trimap
[2] - 以 trimap 中的 unknown region 任取一点为中心对 alphap,eps,trimap 进行crop (size也是从320,480,640中随机选择)
[3] - 如果 size 选择到的不是320,则对所有数据 resize 到320作为网络输入. 此时我们拥有了ground truth background, ground truth alpha, ground truth trimap, ground truth eps. 还缺了什么?缺了ground truth foreground
[4] - 通过公式(1)对此时的 alpha 和 eps 进行 composition 得到ground truth foreground.
[5] - 通过公式(1)对此时的 alpha,eps 和 BGcomposition 得到 ground truth RGB.
[6] - ground truth RGB 减去 global mean,然后 concatenate trimap 作为网络的 4 通道输入,剩余的作为计算Loss 的原料.
至此,数据准备和预处理阶段完成. 这里值得提的有四点(我犯过的错误):
[1] - 离线数据不到最后一步千万不要用 jpg 格式保存,用 png,因为 jpg 是有损压缩,对于这种像素级精度都要求很高的项目来说,中间以 jpg 保存一次就非常致命了. 可以在最后一步保存为 jpg 因为即便出现误差,也是ground truth 的整体飘移,飘移后的数据依然保持一致性,不会对网络的训练造成影响.
[2] - 任何 resize 操作不能发生在用公式(1) 之后,这也是为什么要组织上图那样精细的数据预处理的原因. 这样会造成ground truth漂移,会产生训练数据的不一致性. 下面有举例说明.
[3] - 其他 resize 可以采用默认的双线性插值. 但是trimap最好用 nearest 插值的方式resize,因为其他方式几乎都会改变像素值,而对于 trimap 必须保证 unknown region 为128,而 nearest 插值不会生成新的像素值,只会在原始图像的像素中提取,而且 trimap 对 nearest 插值带来的锯齿不敏感(因为trimap本身就是非常语义模糊的),所以对于 trimap,nearest 是最理想的resize方式.
[4] - resize alpha 的时候,先把数据类型转换成uint8,resize过后再转换回 float32,因为 misc.imresize 操作会对 float 型的数据 rescale,所以你输入图片最大的像素值是32,输出可能直接就被 rescale 到 255了.
2.1.3. 为什么先融合再resize会产生ground truth飘移
先融合再 resize 和先resize再融合的结果分别为: 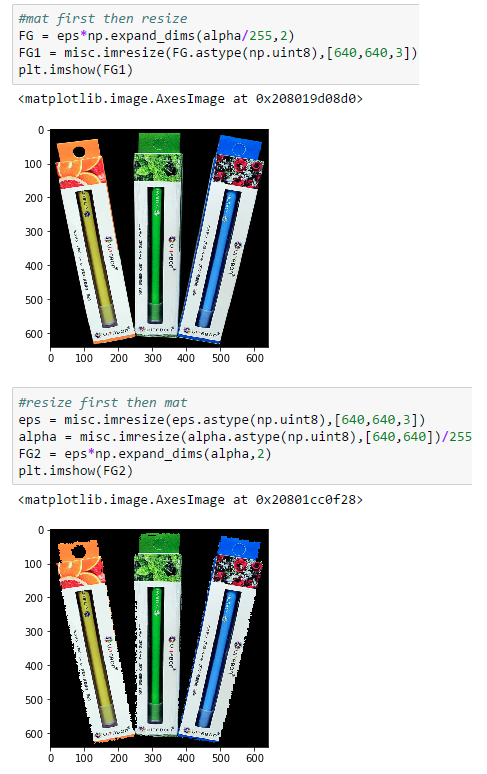
两张图看似一样,但是一作差就会发现: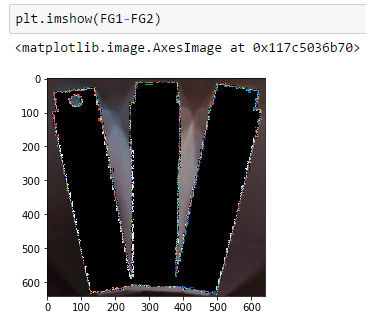
所以如果先融合,再 resize,此时你得到的 foreground 对应的都不是当初原原本本的 alpha 了(resize产生的误差),这对于神经网络的训练极为不利,因为网络努力拟合的方向不是真正它应该去的方向(出现了些许飘移). 从 adobe 公司提供的组合 compositional 的代码可以发现,ground truth RGB是提前离线生成的,也就是说先mat了,而在后面的预处理阶段还有resize操作. 假设作者真的犯了这个错误而没意识到,那可能是文章中模型需要第二阶段refinement的原因. 也就是说如果不犯这个错误的话,可能就不需要第二阶段的refinement网络了(这是我个人的推测).
2.2. 训练阶段
训练阶段没有太多可以谈的. 谈谈我实现过程中与作者不一致的地方.
[1] - 一开始我选择用 deconvolution 代替 unpool 操作,因为 tensorflow 没有现成的unpool函数,虽然有opensource 的,但是都会对网络输入的 batch size产生限制. 即你训练用mini batch size为 5,那么预测阶段也只能 5 个一起预测,非常不便. 但是实验中发现,虽然用 deconvolution 能对单一的有样本过拟合,但是却很难在整个训练集上拟合,考虑到用 deconvolution 后,网络的复杂度其实是高于作者用的网络的,所以不能在整个网络上拟合是非常奇怪的事. 我能想到唯一的解释就是训练时间不够. 最终 deconvolution 的实验在学习率为1e-5 的情况下跑了5天,模型能非常好的预测 general shape,但是一直无法拟合边缘,后来放弃了deconvolution 的做法.
[2] - 用了batch normalization. 虽然原文没提到这一点,但是仅仅是因为不用 batch norm,模型最后都会预测出全黑的结果,所以加上了这个正则化方法,相应的把学习率调整到了1e-4,拟合变得非常快. 用了unpool之后拟合只需要7小时.
[3] - 之前说 unpool 有限制输入 batch size 的问题,后来为什么又用 unpool 了?因为参考了 segmentation 的论文发现,其实在这种以图预测图的任务中,可以认为每一个像素都是一个训练样本,这样即便 batch size 为一,模型在一次训练中也进行了大量的预测,这点是与 classification 任务不同的地方. 所以最后索性设置batch size 为 1,将 deconvolution 换成了unpool, 模型成功拟合了,泛化略微没有作者表现的那么好. 具体请参考我关于这个项目的github页面[5].
[4] - 出于某些原因,在github上的代码里对纯背景和纯前景的地方也进行了误差的反向传播,权重设为了0.5. 实验证明,是否对 bg 和 fg 区域进行反向传播对模型的上限没有影响. 如果不想那两部分的误差有影响,只需将权重设置为0.
这篇论文的复现恐怕要到此为止了,训练阶段的第一点,即 “排除了作者预处理上的失误后,我们能不能不用refinement 网络而达到原论文的水平”暂时没时间去验证也因为公司接下来不会用这个项目,所以才能以博客和开源的方式在这里把复现过程分享给各位,欢迎大家发表自己的意见.
Github 页面 - https://github.com/Joker316701882/Deep-Image-Matting
3. Reference
[1] - https://clippingmagic.com/
[2] - http://alphamatting.com/
[3] - http://www.juew.org/publication/CVPR09\_evaluation\_final\_HQ.pdf
[4] - http://docs.opencv.org/2.4/doc/tutorials/imgproc/erosion\_dilatation/erosion_dilatation.html
48 条评论
博主您好,请问可不可以代为分享数据集。已经向原作者请求多次未获回信。可以提供edu邮箱来验证学术目的
你好,想问可以分享一下数据集么,我的邮箱2402193334@qq.com,一直没有搞到...
数据集需要邮件 DIM 作者
你好,请问可以把你做的先resize后融合,先融合后resize的代码分享给我可以吗?我想实现以下原是否有不一样,邮箱已留
你好,非常感谢你的转载与解答。我希望不再重新训练出模型,使用原模型,直接应用,但是需要两个输入rgb和trimap,rgb是原图容易得到,但是很困惑trimap如何得到,另外原模型只能输入320x320,我只能resize之后才能输入,输出再resize原尺寸,请问是否可以调整参数使其能接受任意尺寸的输入。
trimp 有不同的生成方法,一个基于手工交互式的;以及基于语义分割+膨胀腐蚀的. 如果想处理任意尺寸的输入,需要自己设计网络,重新进行训练.
博主您好,我在复现这个工作,跟作者申请数据集没有回我,能不能麻烦您把数据集给我发一下呢?万分感激~
你好,你复现成功了吗?我也没有得到作者的数据集,如果有的话可以分享一下吗?邮箱1556988284@qq.com
没有作者的数据集,只是理解和实现下原理.
你好,我想请问一下,原文中Figure 2(c)图中的前景图,跟(b)中的alpha matte的形状怎么不大一样?
你好,请问如果要测试一张自己的照片是否也要输入一张Trimp图,而Trimp图是由Alpha产生的,Alpha怎么获取(疑问:Alpha怎么获取,如果有Alpha图不就可以直接进行抠图啦吗)
输入的 alpha 图不一定是很精确的,matting 是进一步将 alpha 图精细化.
您好,我正在复现代码,我有几个不懂得问题需要您的帮助
1.在跑之前需要修改代码中所有的.py文件的路径吗?我大概只看到修改训练集的的路径,测试数据的路径在哪里改呢?
2.我想先试一下跑少量数据,在训练数据中fg和alpha数据1:1,bg数据有很多,我最少需要挑出100张吗?还是可以随意呢?
3.我准备ok的话自己做一些数据集,是要通过opencv来生成alpha图对吗?
matting 一般需要准备训练的前景图片、背景图片和 trimap.
您好该程训练数据集中的eps是个什么,谁能给我讲解下,如何生成,谢谢!OωO
前景目标RGB图片
请问这个程序怎么运行?是要在GitHub上下载程序后,在自己另外下载数据集吗?新手小白第一次使用github上的代码,不太懂,求教,用的是win10+anaconda3.7+pycharm
需要有 Matting 数据集.
有链接吗?只需要下载matting和vgg16就可以直接运行了?
还上面的链接2?里面有好多东西要下载哪个
没有数据集链接,需要的话可能需要与论文作者联系.
博主没有运行过?
简单测试过.对于我要用的场景不适用.
怎么简单测试一下,求教
参考源码里的 test.py - https://github.com/Joker316701882/Deep-Image-Matting/blob/master/test.py
运行了报错
报错总要有错误原因吧,可以贴一下吗,干巴巴的说报错的话,错误日志呢
你放数据集对于错误提示都是不相关的.
D:\Anaconda3\envs\tensorflow\python.exe C:/Users/admin/Desktop/Deep-Image-Matting-master/test.py
2019-06-11 09:46:26.172279: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
2019-06-11 09:46:26.208250: I tensorflow/core/common_runtime/process_util.cc:71] Creating new thread pool with default inter op setting: 4. Tune using inter_op_parallelism_threads for best performance.
WARNING:tensorflow:From D:\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\training\queue_runner_impl.py:391: QueueRunner.__init__ (from tensorflow.python.training.queue_runner_impl) is deprecated and will be removed in a future version.
Instructions for updating:
To construct input pipelines, use the
tf.datamodule.Traceback (most recent call last):
File "C:/Users/admin/Desktop/Deep-Image-Matting-master/test.py", line 47, in
File "C:/Users/admin/Desktop/Deep-Image-Matting-master/test.py", line 16, in main
File "D:\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\training\saver.py", line 1264, in restore
ValueError: Can't load save_path when it is None.
Process finished with exit code 1
这错误提示貌似很明显,没有训练的 checkpoint路径和文件.
tensorflow) C:\Users\admin\Desktop\Deep-Image-Matting-master>python test.py --alpha --rgb
usage: test.py [-h] [--alpha ALPHA] [--rgb RGB] [--gpu_fraction GPU_FRACTION]
test.py: error: argument --alpha: expected one argument
(tensorflow) C:\Users\admin\Desktop\Deep-Image-Matting-master>
要怎么修改
不是修改的问题,是需要有训练的 checkpoint 文件. 代码里是固定写好了. 建议仔细阅读论文及相关实现的代码,不要急着去用代码.
tensorflow/core/grappler/clusters/utils.cc:83] Failed to get device properties, error code: 30请问这个错误怎么解决
可能是 CUDA 版本错误
你好,我想自己做点数据,所以想问一下,用ps对原图扣出前景后,怎么产生alpha图呢
膨胀腐蚀
腐蚀膨胀是产生trimap吗,我想要产生alpha图,能详细说一下吗
是的,把 mask 用膨胀腐蚀处理一下就可以得到 alpha
博主,您那里有复现的代码的预训练模型吗?这边的中文版实现过程博客打不开,预训练模型也找不到下载地址了,我下载了那个VGG16的,但是好像格式不太对每一次运行的时候都会报错
预训练模型?是 VGG 16 的吗? https://www.cs.toronto.edu/~frossard/post/vgg16/. 中文版博客内容原作者的链接挂掉了,这里转载的内容与原文一致. 记录备忘用了.
博主你好,请问那模型训练完,我们在使用的时候,输入是同时需要rgb_image 和trimap是吗。必须有这两个才能得出预测结果是吧。
是的.
看了文章,我理解训练数据有三部分:
1-原始图片
2-alpha_matte图
3-trimap图
其中2是使用1通过PHOTOSHOP工具生产,3是通过编程通过OPENCV使用2通过膨胀运算生成,不知道这么理解是否正确
另外,1和2的数目应该是1:1的,3的数据数目一般是多少啊
可以这样理解. 图片:alpha_matte:trimap 应该都是 1:1:1的.
您好,请问这个网络在test time怎么在一整张图片上跑?因为train的时候只是random crop的。我尝试了将整张图分成小块,一个个跑,在拼在一起。但是crop的中心不一定是未知区域 (和training data不符),另外拼接的边界会有明显的边界线
测试网络的输入是 rgb 图像 + trimap,即:feed_dict = {image_batch:rgb,GT_trimap:trimap};pred_alpha = sess.run(pred_mattes,feed_dict = feed_dict);final_alpha = misc.imresize(np.squeeze(pred_alpha),origin_shape)