千问开源的 8 个最新模型,Qwen3,LLMs 系列.
其中,
Qwen3-235B-A22B, 大模型,benchmarks 超过了 DeepSeek-R1, OpenAI’s o1, o3-mini, Grok 3, 和 Gemini 2.5-Pro 等模型.
Qwen3-30B-A3B,小模型,性能超过了 QWQ-32B ,后者的激活参数是前者的 10 倍.
八个模型的对比,
| Models | Layers | Heads (Q/KV) | Tie Embedding | Context Length |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16/8 | Yes | 32K |
| Qwen3-1.7B | 28 | 16/8 | Yes | 32K |
| Qwen3-4B | 36 | 32/8 | Yes | 32K |
| Qwen3-8B | 36 | 32/8 | No | 128K |
| Qwen3-14B | 40 | 40/8 | No | 128K |
| Qwen3-32B | 64 | 64/8 | No | 128K |
| Qwen3-30B-A3B | 48 | 32/4 | No | 128K |
| Qwen3-235B-A22B | 94 | 64/4 | No | 128K |
其中,6 个模型是 dense,即,在推理和训练时,所有的参数都会被激活;2 个是 open-weighted.
- Qwen3-235B-A22B: 235B 参数的大模型,其中会被激活 22B 参数
- Qwen3-30B-A3B: 30B 参数的 MoE 模型,3B 参数会被激活.
说明:
- Layers: 表示 transformer blocks 的个数. 其包含 multi-head self-attention mechanism、feed forward networks、positional encoding、layer normalization 以及 residual connections. 例如,Qwen3-30B-A3B 有 48 个 Layers,表示模型采用了串联的 48 个 transformer blocks.
Heads:Transformers 采用了 multi-head attention,其将 attention mechanism 划分为多个 heads,每个分别学习数据的一部分特征. 这里,Q/KV 表示,
- Q (Query heads) - 用于生成 queries 的 attention heads 的总数
- KV(Key and Value) - 每个 attention block 的 key/value heads 的总数
Qwen3 的关键点
1. Pre-training
pre-training 包含三个阶段:
- 第一阶段,模型在 30 trillion tokens 上训练,上下文长度 4k tokens. 让模型具备基本的语言技能和通用知识;
- 第二阶段,通过增加知识密集型数据的比例,如STEM、Coding、Reasoning task等,提升数据的质量。模型再在 5 trillion tokens 上进行训练。
- 第三阶段,通过增加上下文长度到 32K tokens,来提升高质量的上下文数据。确保模型能够有效处理更长的输入。
2. Post-training
为了开发能够逐步推理和快速响应的混合模型,实施了 4 阶段的训练流程:
- Long chain-of-thoughts(CoT)
- 基于 reinforcement learning 的推理
- Thinking mode fusion
- General RL
3. Hybrid Thinking Modes
Qwen3 采用混合方法,有两种模式:
- Thinking Mode: 这种模式,模型花时间将复杂问题分解为小的、程序化的步骤来处理;
- Non-Thinking Mode:模型提供快速结构,适用于简单问题
4. Multilingual Support
Qwen3 支持119 种语言
5. 提升 Agentic 能力
Qwen3 优化了 Coding 和 Agentic 能力,支持MCP
Qwen3 构建 AI Agent
代码实现,如,
'''
pip install langchain langchain-community openai duckduckgo-search
'''
from langchain.chat_models import ChatOpenAI
from langchain.agents import Tool
from langchain.tools import DuckDuckGoSearchRun
from langchain.agents import initialize_agent
llm = ChatOpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key",
model="qwen/qwen3-235b-a22b:free"
)
# Web Search Tool,搜索Tool
search = DuckDuckGoSearchRun()
# Tool for DestinationAgent,目的Tool
def get_destinations(destination):
return search.run(f"Top 3 tourist spots in {destination}")
DestinationTool = Tool(
name="Destination Recommender",
func=get_destinations,
description="Finds top places to visit in a city"
)
# Tool for CurrencyAgent, 货币Tool
def convert_usd_to_inr(query):
amount = [float(s) for s in query.split() if s.replace('.', '', 1).isdigit()]
if amount:
return f"{amount[0]} USD = {amount[0] * 83.2:.2f} INR"
return "Couldn't parse amount."
CurrencyTool = Tool(
name="Currency Converter",
func=convert_usd_to_inr,
description="Converts USD to inr based on static rate"
)
'''
构建Agent
'''
tools = [DestinationTool, CurrencyTool]
agent = initialize_agent(
tools=tools,
llm=llm,
agent_type="zero-shot-react-description",
verbose=True
)
def trip_planner(city, usd_budget):
dest = get_destinations(city)
inr_budget = convert_usd_to_inr(f"{usd_budget} USD to INR")
return f"""Here is your travel plan:
*Top spots in {city}*:
{dest}
*Budget*:
{inr_budget}
Enjoy your day trip!"""
'''
初始化Agent
'''
# Initialize the Agent
city = "Delhi"
usd_budget = 8500
# Run the multi-agent planner
response = agent.run(f"Plan a day trip to {city} with a budget of {usd_budget} USD")打印输出,如:
from IPython.display import Markdown, display
display(Markdown(response))
Qwen3 构建 RAG System
代码实现,如,
'''
!pip install langchain langchain-community langchain-core openai tiktoken chromadb sentence-transformers duckduckgo-search
'''
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
# Load your document
loader = TextLoader("/content/my_docs.txt")
docs = loader.load()
'''
创建 Embeddings
'''
# Split into chunks
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=50)
chunks = splitter.split_documents(docs)
# Embed with HuggingFace model
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
db = Chroma.from_documents(chunks, embedding=embeddings)
# Setup Qwen LLM from OpenRouter
llm = ChatOpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="YOUR_API_KEY",
model="qwen/qwen3-235b-a22b:free"
)
# Create RAG chain
retriever = db.as_retriever(search_kwargs={"k": 2})
rag_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
'''
初始化RAG
'''
# Ask a question
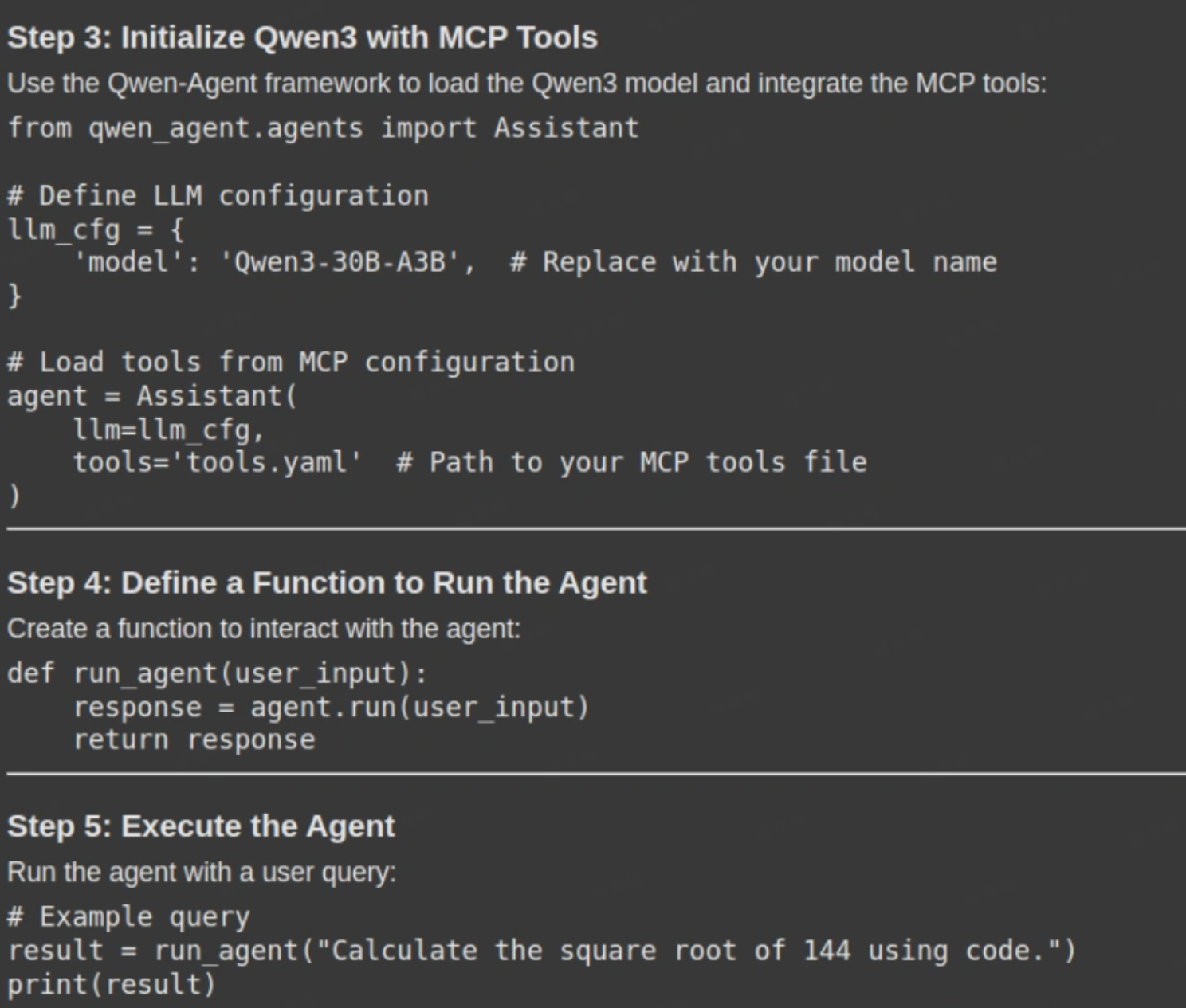
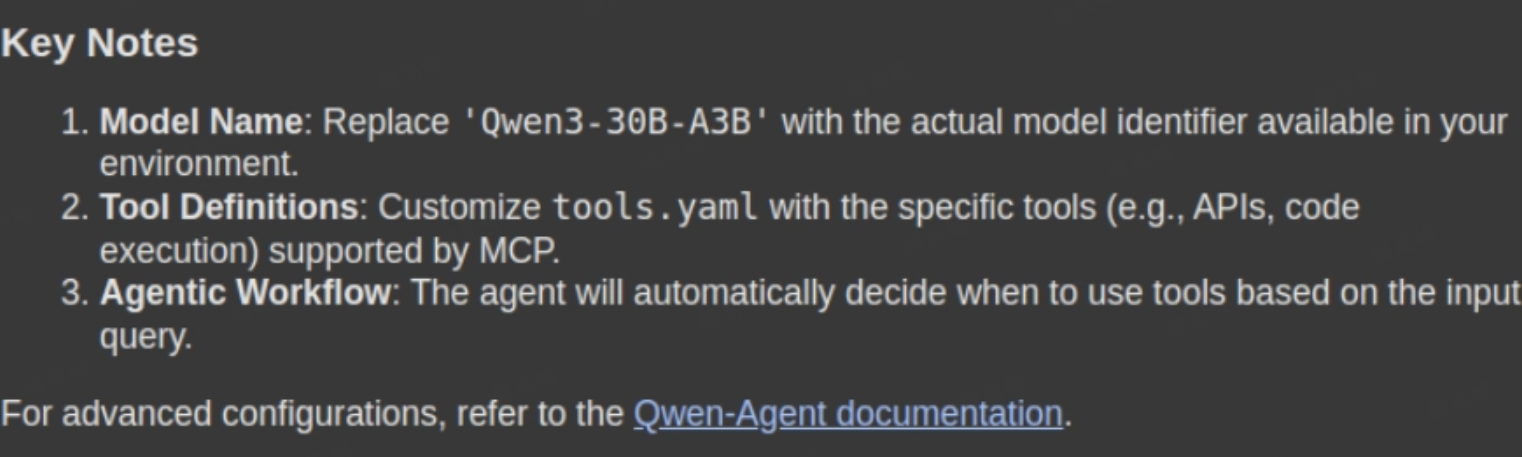
response = rag_chain.invoke({"query": "How can i use Qwen with MCP. Please give me a stepwise guide along with the necessary code snippets"})打印输出,如
display(Markdown(response['result']))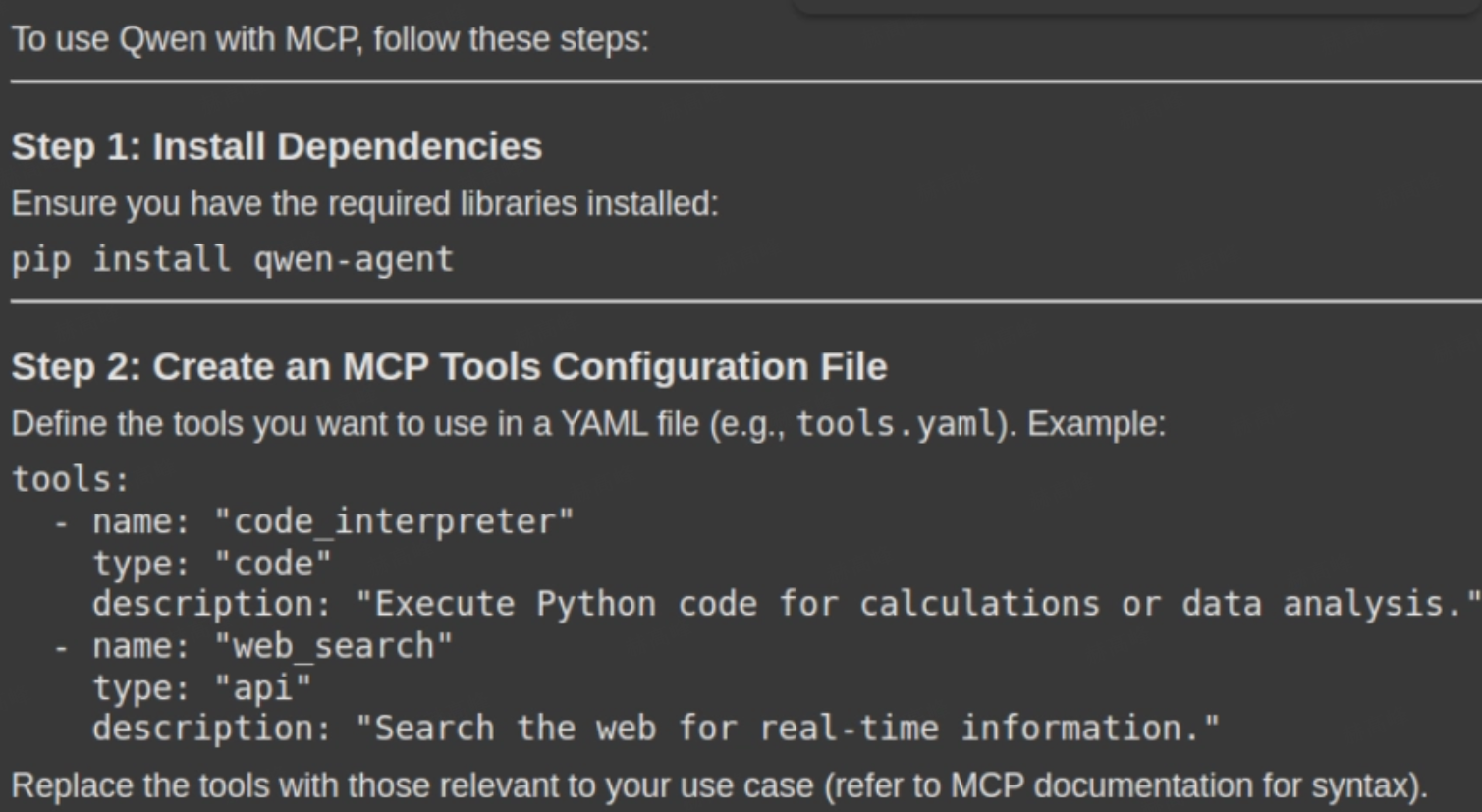
Qwen3 应用场景
- Automated Coding
- Education and Research
- Agent-Based Tool Integration
- Advanced Reasoning Tasks