论文:Variational Transformer Networks for Layout Generation - CVPR2021
Blog:Using Variational Transformer Networks to Automate Document Layout Design - Google AI Blog
Code:暂无
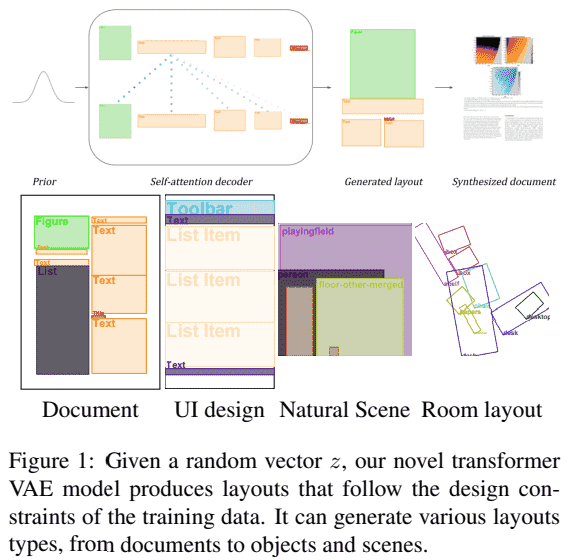
设计领域生成模型,以合成不同类型的布局,如文档、用户界面、家具布局等.
主要是基于自注意力(self-attention) 层,捕捉布局中不同元素间的高层关系,并基于变分自编码器(VAE) ,构建变分Transformer 网络(VTN).
VTN 能够在没有明确监督的情况下,学习边距、对齐和其他全局设计规则.
布局生成往往依赖于贪婪搜索算法(greedy search algorithms),如beam search, nucleus sampling or top-k sampling,其生成的多样性不能保证.
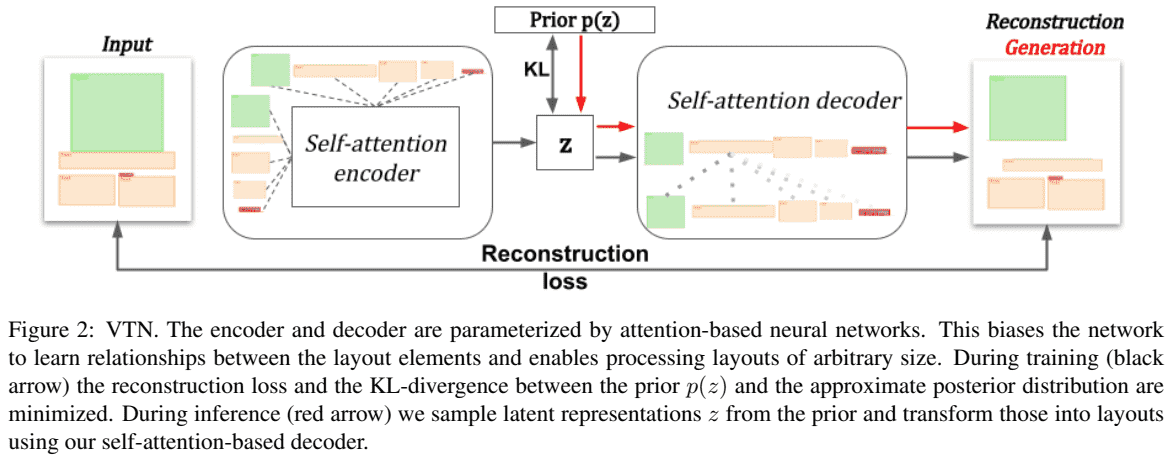
1. VTN 结构
如图:
动态版,如:

1.1. 变分建模的瓶颈层
VAE 的瓶颈层(bottleneck layer)往往被建模为用向量来表示输入.
由于 Self-Attention 层是 sequence-to-sequence 结构,如,一个包含 n 个输入元素的序列,被映射到 n 个输出元素.
基于 BERT 的启发,在序列的起始出添加了一个辅助标记(token),并将其看作为自编码器瓶颈向量(autoencoder bottleneck vector) z. 训练阶段,与该标记相关的向量是传递给编码器的唯一信息,因此,编码器需要学习如何压缩该向量中的整个文档信息. 而解码器学习从该向量推断文档中的元素数量以及输入序列中每个元素的位置.
1.2. 布局转换为输入数据
一个文档往往是由多种设计元素组成,如,段落、表格、图像、标题、脚注等.
设计中的布局元素一般通过各元素边界框坐标来表示.
为了便于神经网络理解这些信息,将每个元素通过四个变量(x, y, width, height) 来分别表示元素在页面的位置(x,y),大小为 (width, height).
2. Results
如,
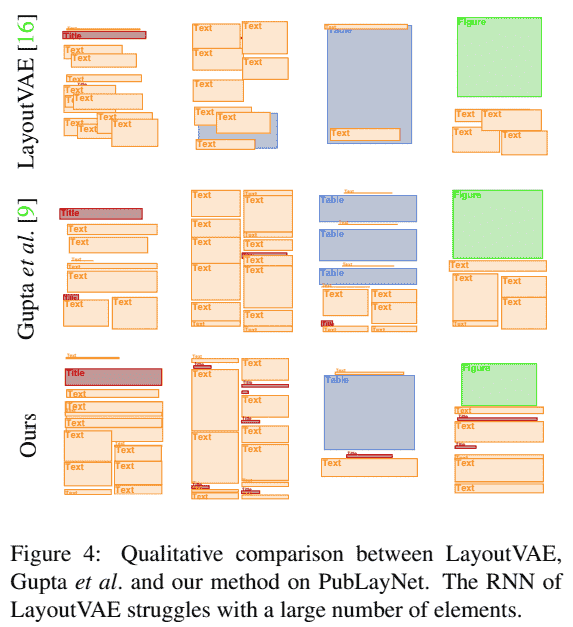
更多可见论文附加材料.