题目: Multi-Context Attention for Human Pose Estimation - CVPR2017
作者: Xiao Chu, Wei Yang, Wanli Ouyang, Cheng Ma, Alan L. Yuille, Xiaogang Wang
团队: CUHK, Tsinghua University, Johns Hopkins University
整合多内容信息注意力机制(multi-context attention mechanism)到CNN网络,得到人体姿态估计 end-to-end 框架.
采用堆积沙漏网络(stacked hourglass networks) 生成不同分辨率特征的注意力图(attention maps),不同分辨率特征对应着不同的语义.
利用CRF(Conditional Random Field)对注意力图中相邻区域的关联性进行建模.
并同时结合了整体注意力模型和肢体部分注意力模型,整体注意力模型针对的是整体人体的全局一致性,部分注意力模型针对不同身体部分的详细描述. 因此,能够处理从局部显著区域到全局语义空间的不同粒度内容.
另外,设计了新颖的沙漏残差单元(Hourglass Residual Units, HRUs),增加网络的接受野. HRUs 扩展了带分支的残差单元,分支的 filters 具有较大接受野;利用 HRUs 可以学习得到不同尺度的特征.
1. Introduction
人体姿态估计面临的问题:肢体关联性、自遮挡、服装影响、透视(foreshortening)因素、复杂物体背景(尤其与肢体比较相似)及人体的严重遮挡.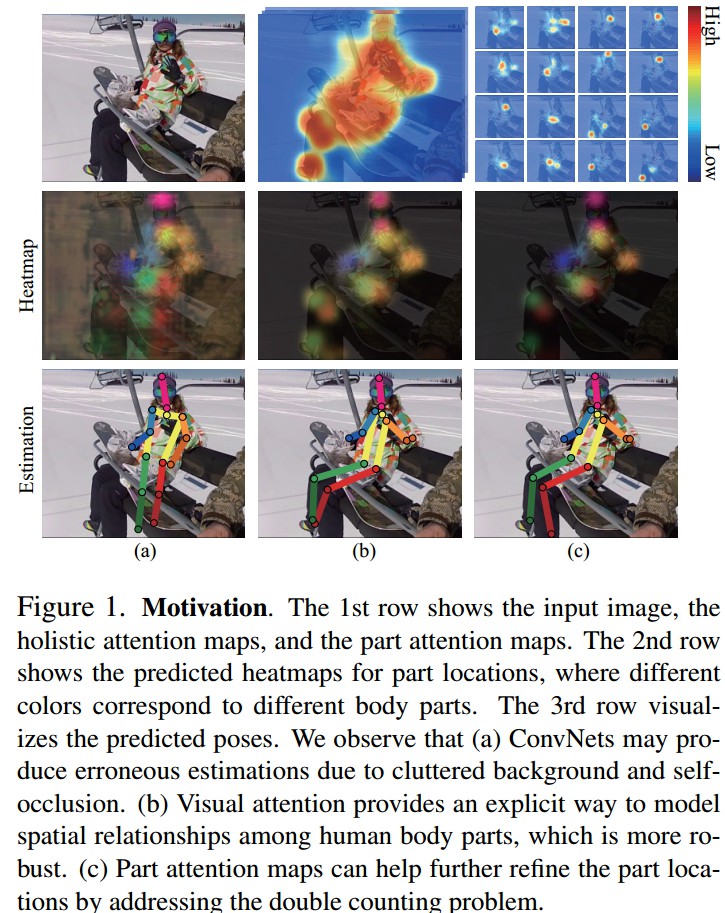
Figure1. 第一行分别是,输入图片、整体注意力图、部分注意力图.
第二行是关节点位置的heatmaps,不同颜色对应不同的关节点.
第三行是预测的姿态可视化结果.
(a)由于背景复杂和自遮挡问题,ConvNets可能得到错误的估计结果.
(b)视觉注意力图对人体关节点的空间关系进行建模,鲁棒性好.
(c)关节点注意力图解决重复计算问题(double counting problem),进一步提高关节点估计结果.
视觉注意力是一种人脑有效理解场景的机制. 不同于采用一系列的矩形边界框集合来定义ROI(regions
of interest),采用注意力模型生成注意力图,只依赖图像特征,提供了更有效的方式来关注不同形状的目标区域.
采用堆积沙漏网络结构(stacked hourglass network)来建立multi-context 注意力模型. 每个沙漏单元,特征被降低到非常低的分辨率,然后再上采样并与高分辨率特征相结合. 多次重复该沙漏网络单元,以逐渐捕捉更全局化的特征表示.
利用多个 hourglass stacks 得到的注意力图,能够表示不同语义层次的多语义信息.
2. 方法
Multi-Context Attention:
• Multi-Semantic Attention
• Multi-Resolution Attention
• Hierarchical (holistic/part) Attention
• Tailored Attention Scheme
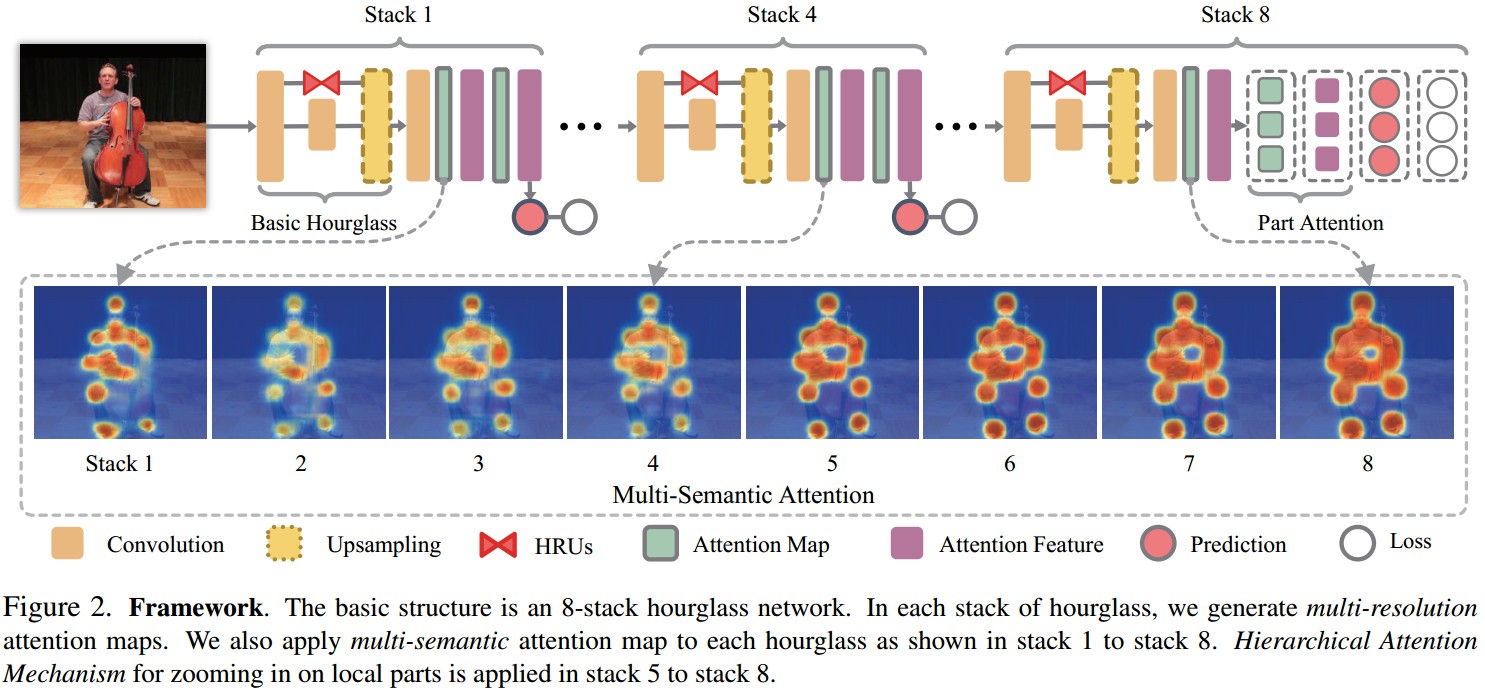
Figure2. 8-stack hourglass网络的基本结构. 各hourglass stack 分别得到多分辨率注意力图. 将多语义注意力图应用到各 hourglass,如 stack 1 - stack 8. 分层注意力机制对局部关节点的缩放应用在 stack 5 - stack 8.
2.1 基础网络
采用 8-stack hourglass 网络作为基础网络,该网络在各 hourglass stack的尾部采用中间监督,重复地进行 bottom-up,top-down 跨尺度推断. 输入图片尺寸 $256×256$,输出heatmaps尺度为$K×64×64$,$K$为关节点数目. 网络的损失函数采用 MSE(Mean Squared Error).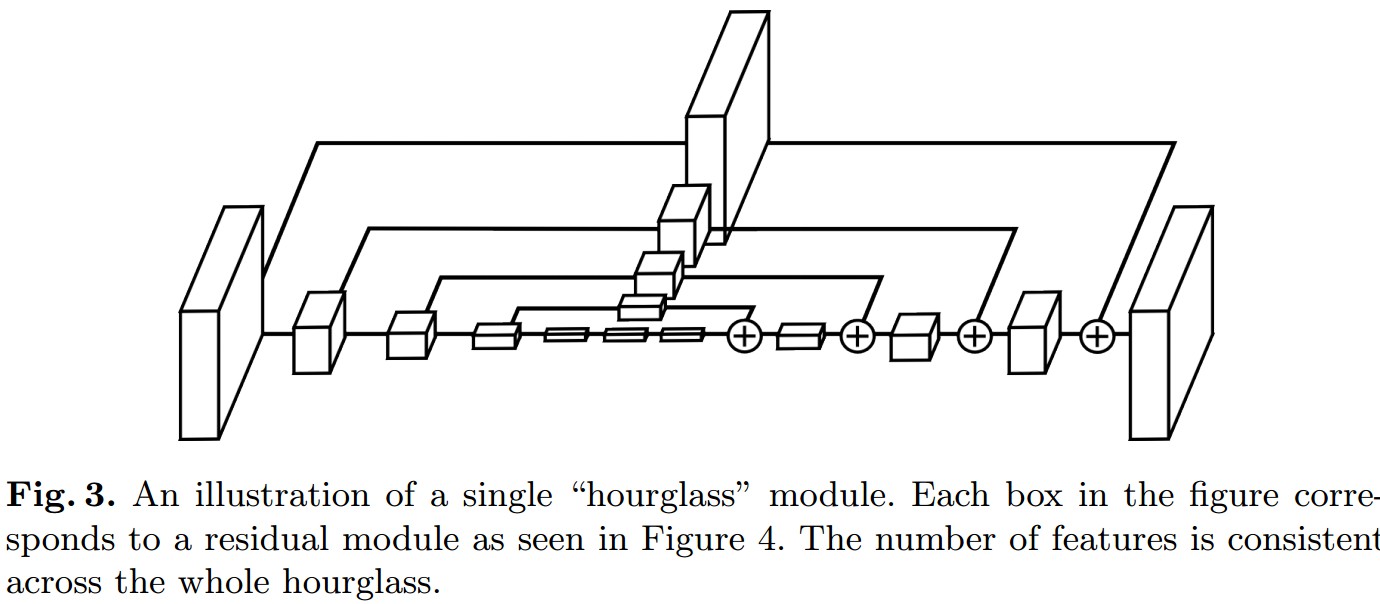
2.2 Nested Hourglass 网络
采用HRUs代替残差单元,得到 nested hourglass network,如图.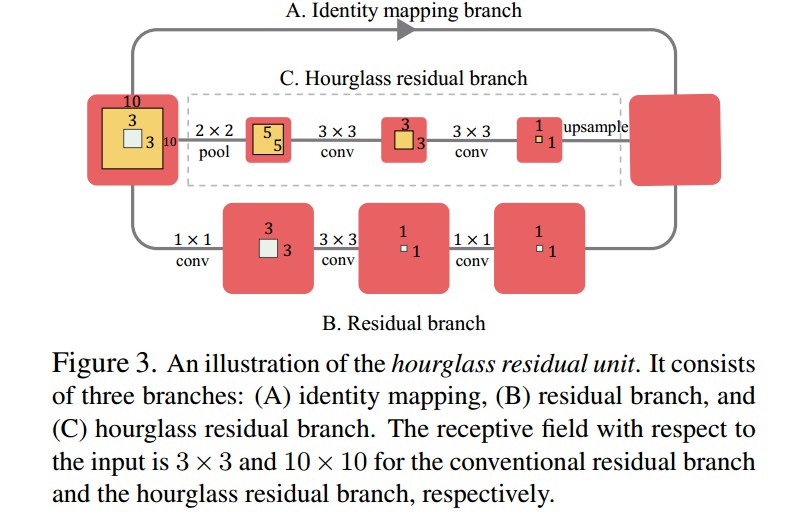
Figure3. HRU例示. 包括三个分支:(A)恒等映射(identity mapping)分支; (B)残差分支;(C)hourglass residual 分支. 卷积残差分支和 hourglass residual 分支输入的接受野分别为 $3×3$ 和 $10×10$.
三个分支具有不同的接受野和分辨率,相加作为HRU的输出. HRU 单元增加了网络接受野,同时保持高分辨率信息.
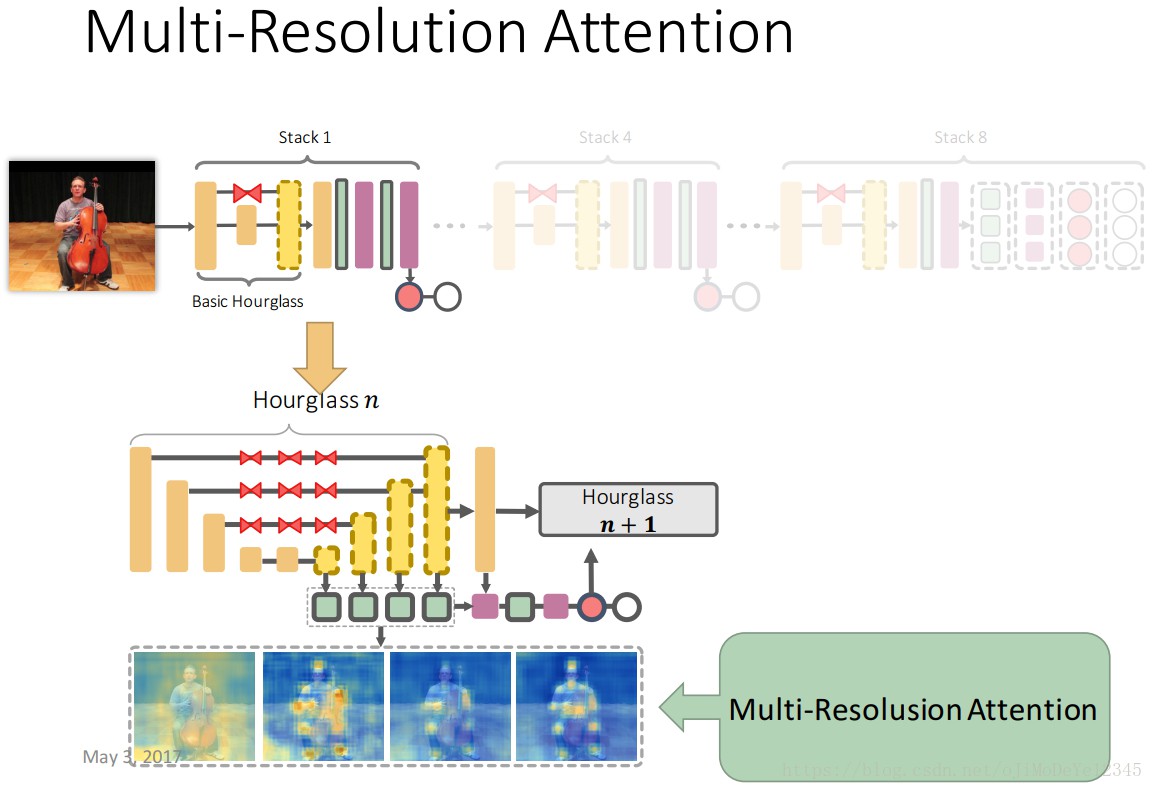
2.3 多分辨率注意力(Multi-Resolution Attention)
各 hourglass 从不同尺度的特征得到多分辨率注意力图 $\Phi _r$,$r$是特征的大小. 如图Figure5. 结合得到的注意力图以改善特征,以进一步用于注意力图和特征的完善,如Figure4.
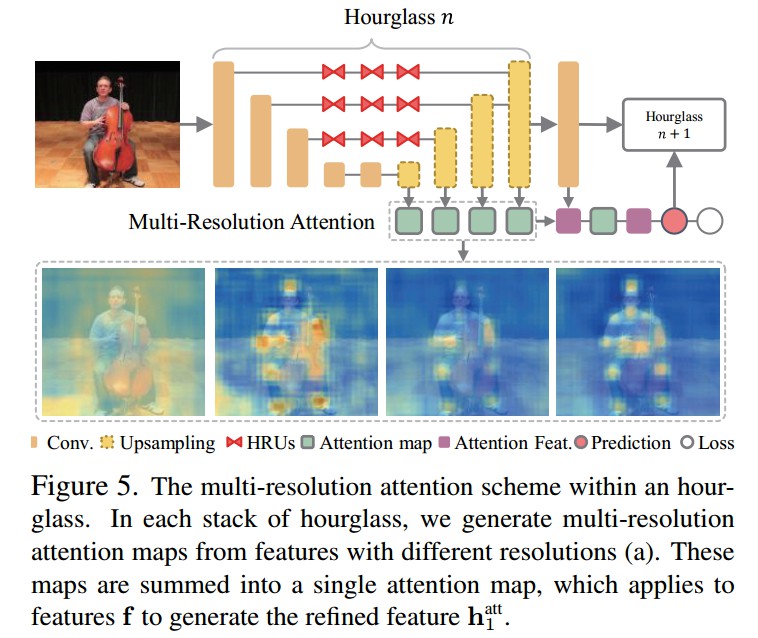
Figure5. hourglass 的多分辨率注意力机制.
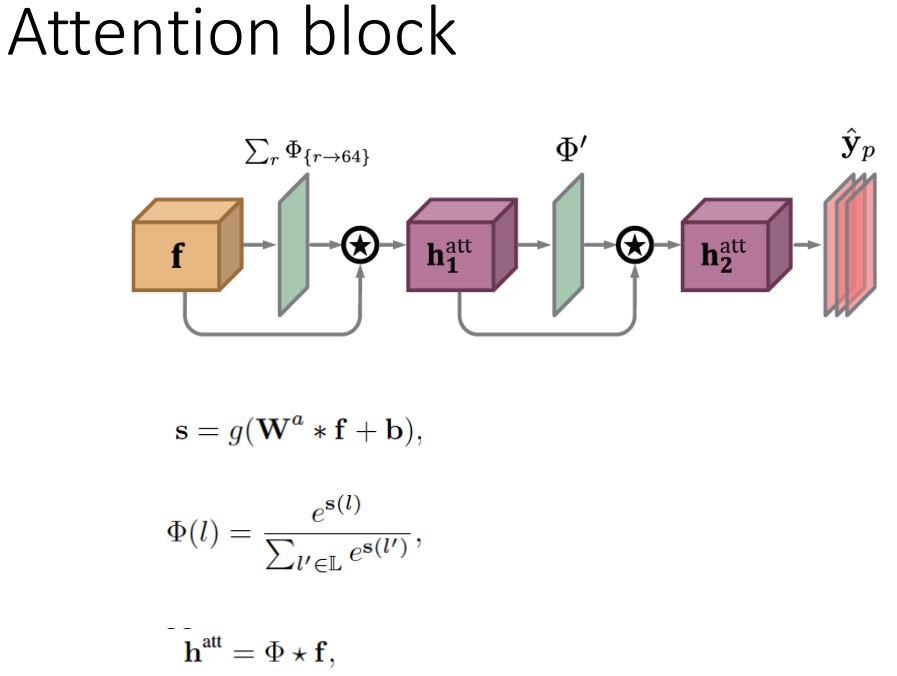
Figure4. 注意力机制例示.
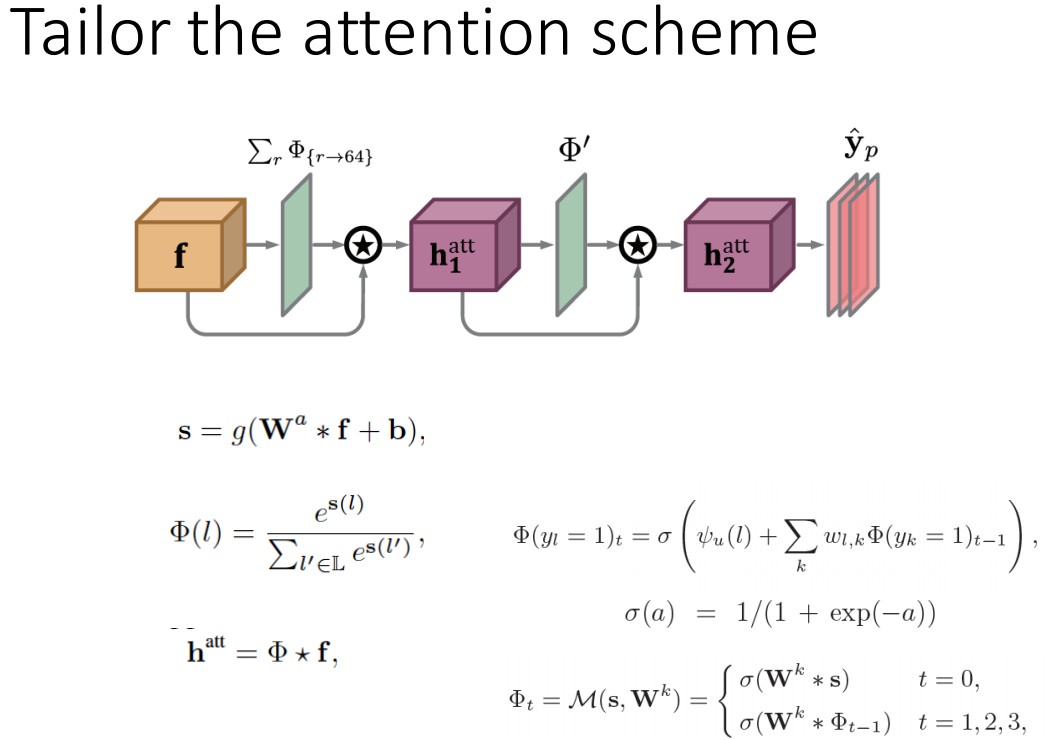
2.4 多语义注意力(Multi-Semantics Attention )
不同的 stack 具有不同的语义 —— 底层 stacks 对应局部特征,高层 stacks 对应全局特征. 因此,不同 stacks 生成的注意力图编码着不同的语义. 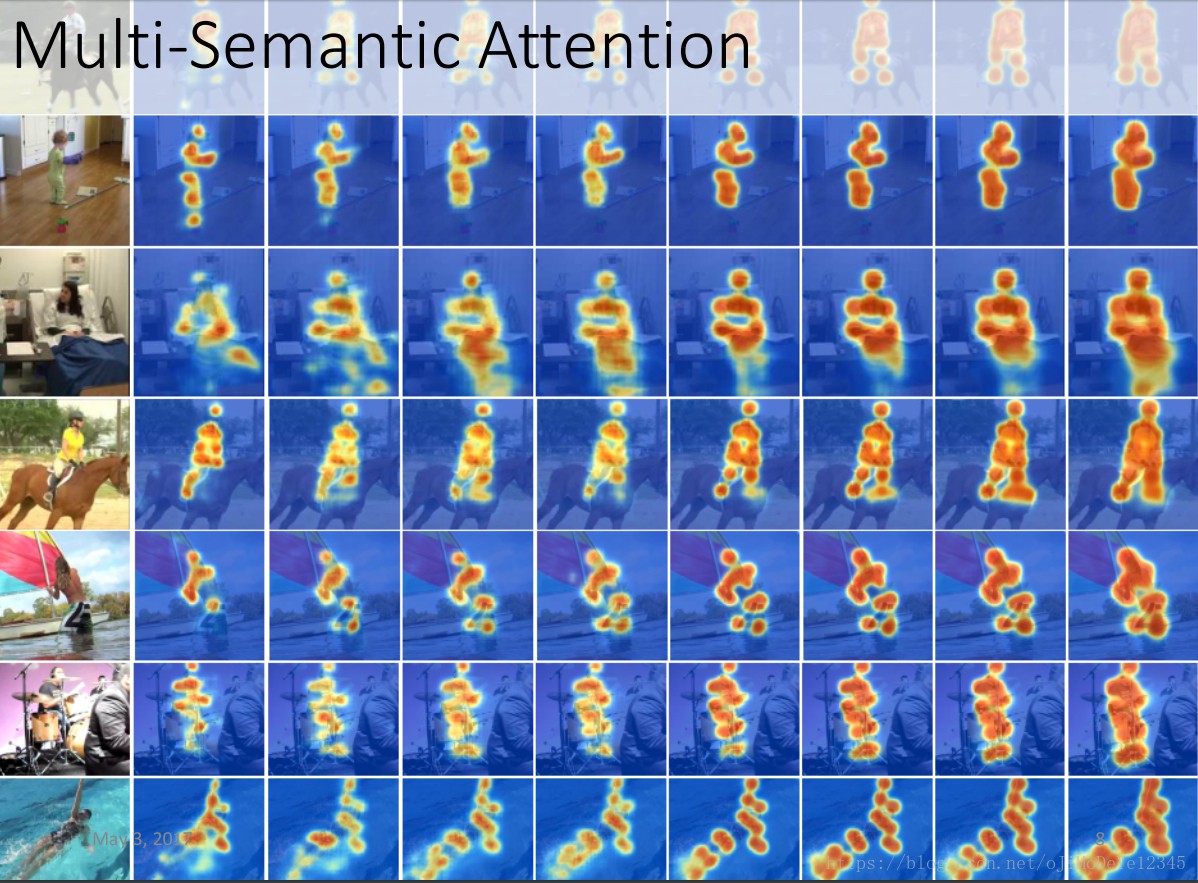
2.5 分层注意力机制(Hierarchical Attention Mechanism)
底层 stacks (stack1 - stack4),采用两个整体注意力图 ${ \mathbf{h}_{1}^{att} }$ 和 ${ \mathbf{h}_{2}^{att} }$ 来对整体人体进行编码.
高层 stacks (stack5 - stack8),设计分层的 coarse-to-fine 注意力机制对局部关节点进行缩放处理.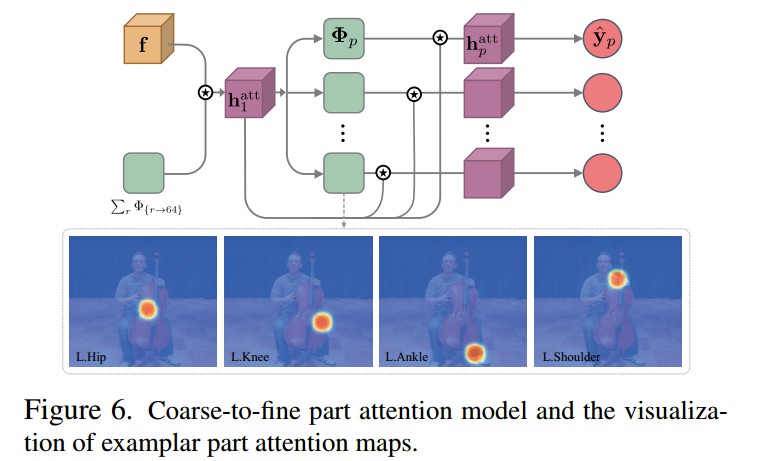
${ \mathbf{f} }$ 是Figure5中 hourglass stack 的最后一层的输出特征,${ \Phi }$ 上采样的注意力图.
${ \mathbf{h}_{1}^{att} }$ 是 hourglass stack 输出特征和注意力模型得到的注意力图;
${ \mathbf{h}_{2}^{att} }$ 是注意力图 ${ \mathbf{h}_{1}^{att} }$ 结合各关节点注意力模型得到的refined后注意力图特征.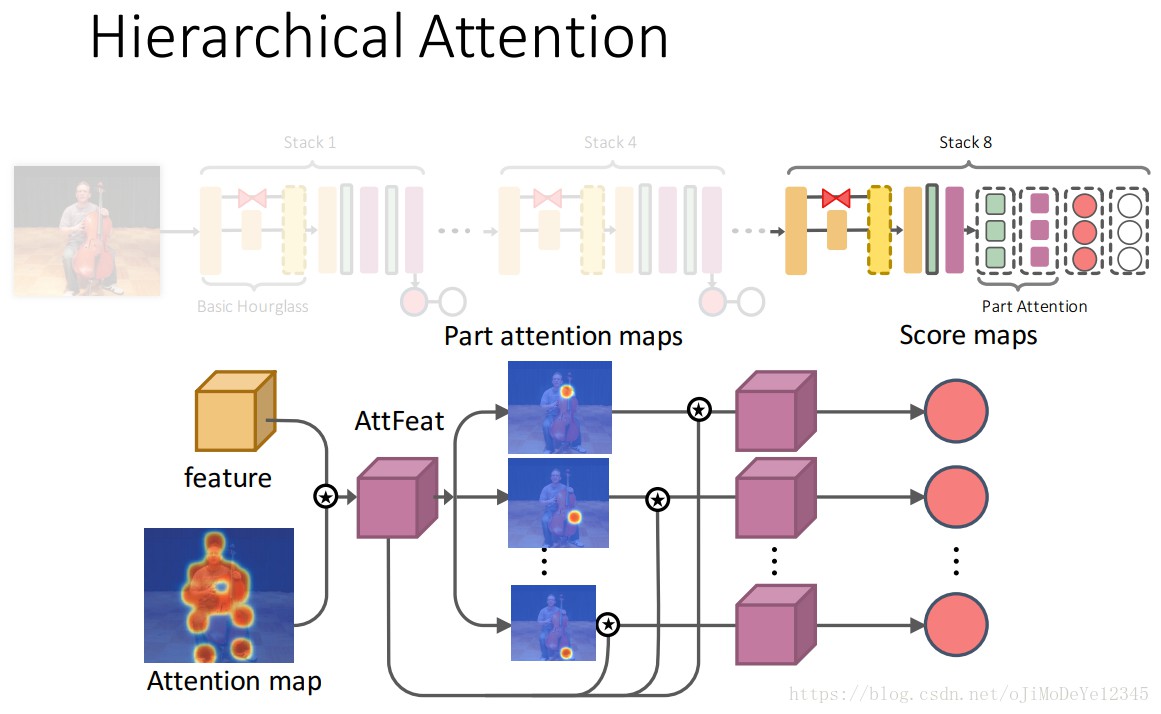
2.6 模型训练
Hourglass stack 网络估计人体关节点的heatmaps.
均方差误差(MSE)损失函数:
${ L = \sum_{p=1}^{P} \sum_{l \in \mathbf{L}} ||\breve{y}_p(l)- y_p(l)||_2^2 }$
${ p }$ 为第 ${ p }$ 个关节点,${ l }$ 为第 ${ l }$ 个位置.
${ \breve{y}_p }$ 为关节点 ${ p }$ 的预测heatmap;
${ y_p }$ 为对应的GT heatmap,是以关节点位置为中心的 2-D Gaussian.
注意力图有益于将网络关注于 hard negative samples. 网络训练了几个阶段后,注意力图集中在人体区域,注意力图将 true positive samples 突出化. 整体注意力图的特征用于训练人体区域的分类器,通过学习的注意力图来区分背景区域. 之后,关节点的注意力图,得到的分类器基于人体区域来对各人体关节点,不需要考虑背景.
2.6.1 Data Augmentation
- crop the images with the target human centered at the images with roughly the same scale
- 输入图像尺寸 256×256
- randomly rotate (±30◦) and flip the images
- random rescaling (0.75 to 1.25) and color jittering
- Torch7,initial learning rate 2.5 × 10^{-4},RMSprop 优化.
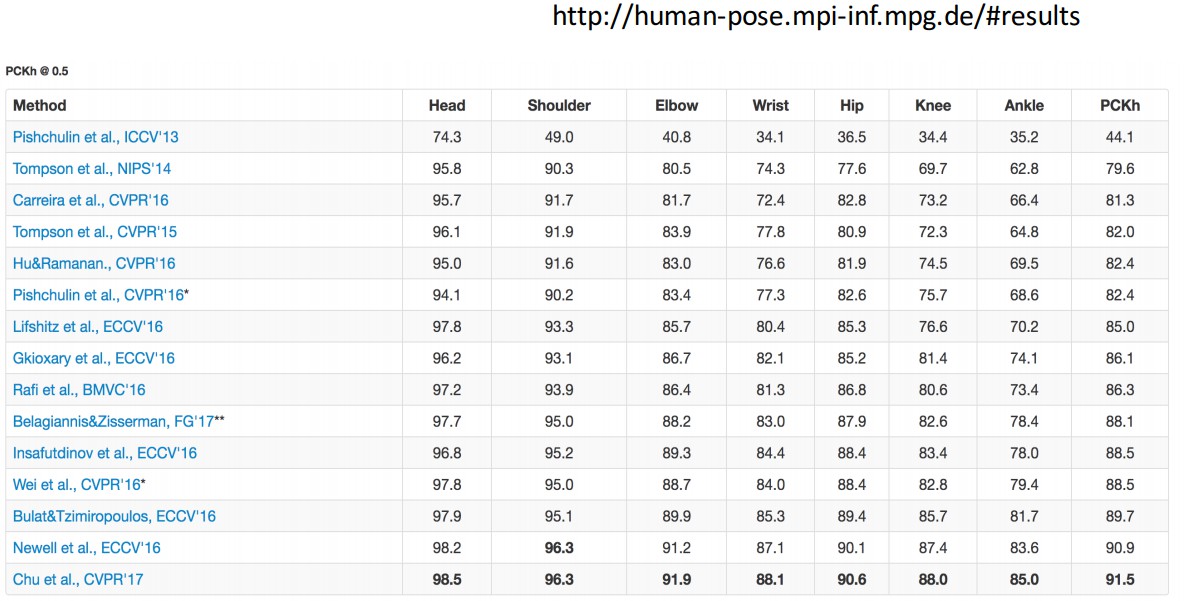
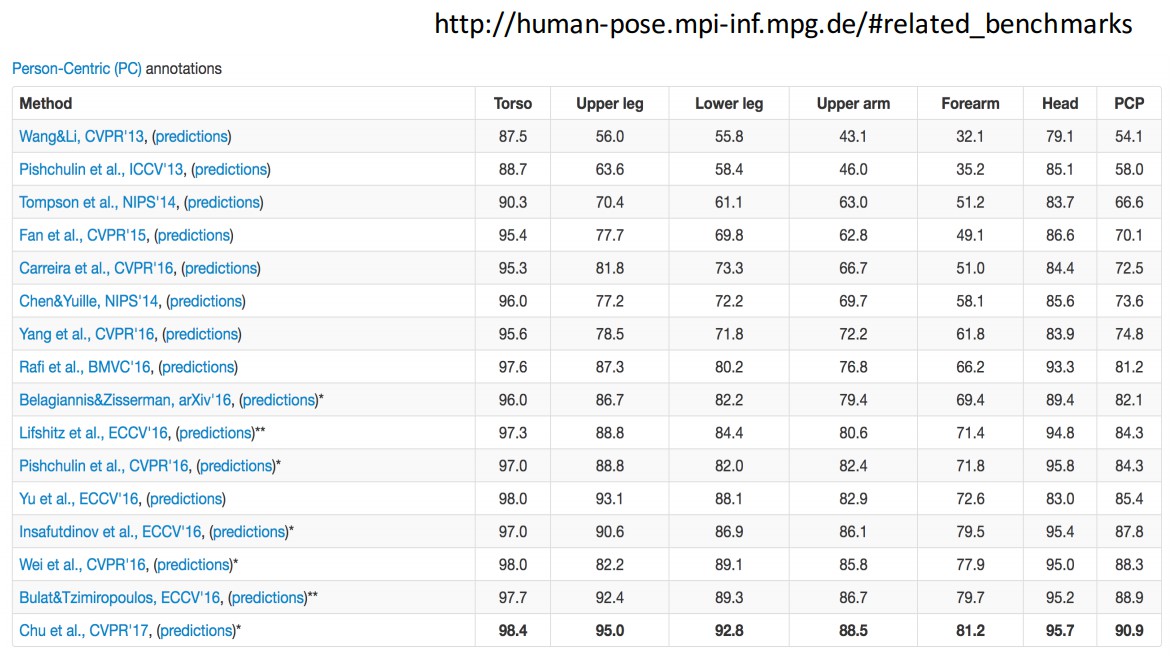
3. Results