题目: Zero-shot Image Tagging by Hierarchical Semantic Embedding - SIGIR2015
作者: Xirong Li, Shuai Liao, Weiyu Lan, Xiaoyong Du, Gang Yang
团队: Renmin University of China
许多细粒度视觉类别的标签获取较为困难,zero-shot 图像标注(image tagging) 旨在采用训练样本中不存在的新标签来标注图像.
现在通常做法是,采用神经语言模型(neural language model) 训练得到语义空间,将图像和标签投影到该语义空间,然后计算跨媒体的相似性,以进行图像标注. 但对于出现频次相对较少的标签,得到的与图像即其它标签的相似性可能不可靠.
本文提出层次语义嵌入(Hierarchical Semantic Embedding, HierSE),采用 WordNet 层次来提高标签嵌入和图像嵌入效果. 另外,采用了两种好的技巧:采用 Flickr 标签来训练自然语言模型,而不是网络文档(web document);采用部分匹配(partial match)向量化的 WordNet 节点,而不是全匹配的方式(full match).
zero-shot learning 不是寻找图像和目标标签的直接映射关系,其关键在于在图像和标签之间引入中间层,使得新标签也可在这层进行表示,即使没有该标签的图像样本.
1. 问题描述
给定未标注图片,zero-shot 图像标注的目标是,利用没有可用训练样本的标签对图片进行自动标注. 主要是通过将图像和新标签嵌入到一个共同的语义空间,以便于通过计算语义空间中对应向量的距离来估计其相关性.
记 x 为图片, y 为标签,p(y|x) 为估计 标签 y 关于图片 x 相关性的分类器.
给定 ${ m_{0} }$ 个训练标签集 ${ Y_{0} }$,n 个训练样本 ${ D_{0} = \lbrace (x_i, y_i) \rbrace_{i=1}^n }$, ${ y_i \in Y_0 }$ . 相应地,记 ${ p_0(y|x) }$ 为从 ${ D_0 }$ 学习得到的 ${ m_0 }$-way 分类器.
记 ${ Y_1 }$ 为具有 ${ m_1 }$ 个测试标签的集合,其在 zero-shot 学习中没有对应的训练样本, 即 ${ Y_0 \bigcap Y_1 = O }$ .
基于 ${ D_0 }$ 和某些语义信息,zero-shot 旨在建立一个分类器 ${ p_1(y|x) }$ 能够对于 ${ Y_1 }$ 能够表现良好.
该方法是在 [1] 的语义嵌入模型的基础上进行的.
2. 语义嵌入模型[1]
每一个标签(label) ${ y \in Y_{0} \bigcup Y }$ 对应着一个语义嵌入向量 ${ s(y) \in S }$,其中 S 是 q 维坐标空间.
在语义空间中,当且仅两个标签对应向量相近时,两个标签才相似.
在论文[1]中,S 是采用 Wikipedia 文档训练 skip-gram 模型进行实例化的. 每个 s(y) 是通过匹配 skip-gram 模型中的词语表示的 label得到.
通过将图像投影到语义空间 S,即可计算跨媒体的相关性.
为了计算该相关性,该语义模型采用分类器 ${ p_0(y|x) }$, 并创建 x 语义嵌入向量为最相关训练标签的语义向量的凸化组合(convex combination)形式.
即:假设 y(x,t) 为 x 根据分类器 ${ p_{0}(y|x) }$ 得到的最相似的第 t 个训练标签,则 x 的语义嵌入向量,记为 ${ f(x) \in S }$,即可表示为:
${ f(x) := \frac{1}{Z} \sum_{t=1}^{T} p_{0}(y(x,t)|x) \cdot s(y(x,t)) }$
其中, T 为训练标签的最大数. ${ Z=\sum_{t=1}^{T} p_{0}(y(x,t)|x) }$ 是归一化因子.
对于新的标签集 ${ Y_{1} }$ 的分类器定义为:
${ p_{1}(y|x) := cos(f(x), s(y)) }$
其中,cos 为余弦距离.
3. 层次语义嵌入
本文方法是通过探索在 WordNet 中定义的层次结构,来构建标签嵌入和图像嵌入的.
假定每一个标签都在 WordNet 中对应一个节点. WordNet 层次结构使得可以从一个特定标签追踪到根节点,得到其所有的原型(ancestors),记为 supper(y).
在论文[1]中只使用了 y,这里同时利用 y 和 super(y).
直觉上,越与 y 接近的节点应该贡献更多.
综上,这里定义层次嵌入向量 ${ s_{hi}(y) }$ 为:
${ s_{hi}(y) = \frac{1}{Z_{hi}} \sum_{y^\prime \in {y} \bigcup super(y)}w(y^\prime|y) \cdot s(y^\prime) }$
其中,${ w(y^\prime |y) }$ 是权重,服从关于从 y 到 ${ y^\prime }$ 的最小路径长度的指数延迟(exponential delay). ${ Z_{hi} = \sum_{y^\prime \in {y} \bigcup super(y)}w(y^\prime|y) }$ 是归一化因子.
在上述公式中,super(y) 使得 y 能够映射到语义空间 S ,这种凸化组合使得稀少标签的相似性度量更加可靠.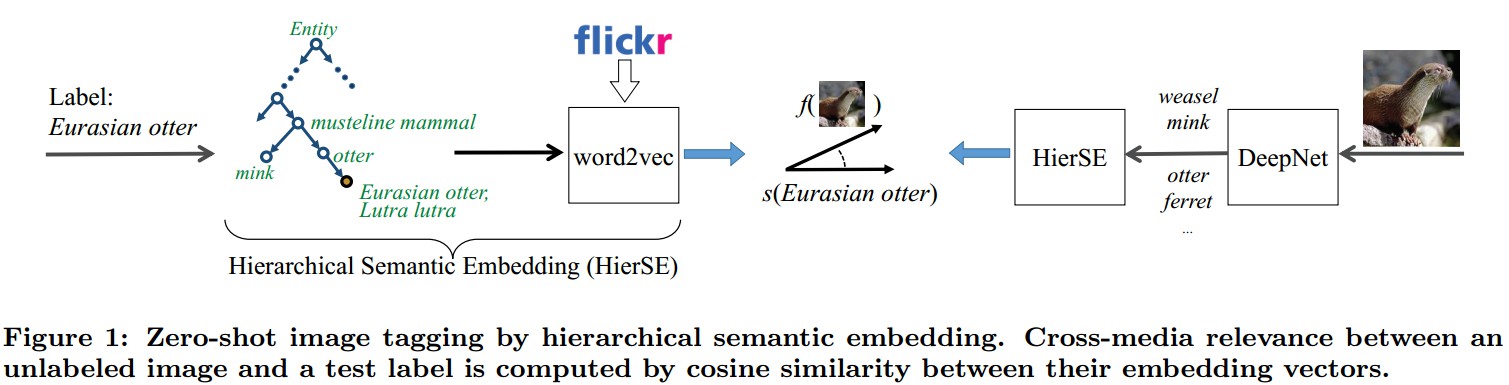
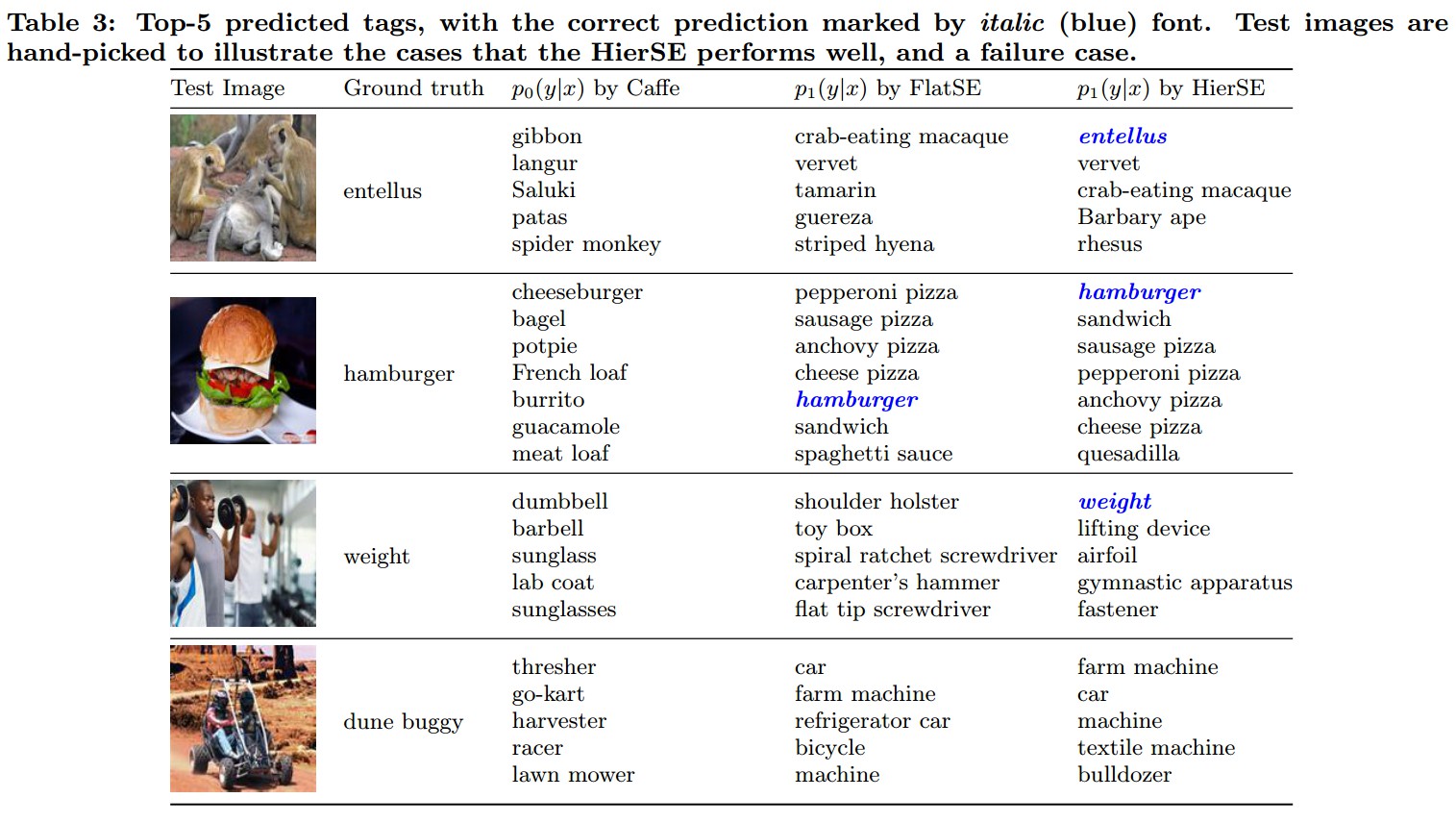
4. Results
参考文献
[1] - Zero-shot learning by convex combination of semantic embedding. In ICLR, 2014