英文:[Building a visual search application with Amazon SageMaker and Amazon ES - 2020.06.29]()
中文:使用 Amazon SageMaker 与 Amazon ES 构建一款视觉搜索应用程序 - 2020.08.21
某些应用场景中,可能很难找到合适的词汇来描述需求,但正如俗语所言,“一图抵千言. ”一般来说,展示真实示例或者图像,对于目标的表达效果确实要比纯文字描述好上不少. 这一点,使用以图搜图搜索引擎查找所需内容显得尤其突出.
视觉搜索能够提高客户在零售业务与电子商务中的参与度,这种功能对于时尚及家庭装饰零售商而言尤其重要. 视觉搜索允许零售商向购物者推荐与主题或特定造型相关的商品,这是传统纯文本查询所无法做到的. 根据Gartner公司的报告,“到2021年,重新设计网站以支持视觉及语音搜索的早期采用者品牌,将推动数字商务收入增长30%. ”
1. 以图搜图示例
Amazon SageMaker是一项全托管服务,可为每位开发人员及数据科学家提供快速构建、训练以及部署机器学习(ML)模型的能力.
Amazon Elasticsearch Service (Amazon ES)同样为全托管服务,可帮助轻松以符合成本效益的方式大规模部署、保护并运行Elasticsearch. Amazon ES还提供k最近邻(KNN)搜索,能够在相似性用例中增强搜索能力,适用范围涵盖产品推荐、欺诈检测以及图像、视频与语义文档检索.
KNN使用轻量化且效率极高的非度量空间库(NMSLIB)构建而成,可在数千个维度上对数十亿个文档进行大规模、低延迟最近邻搜索,且实现难度与常规Elasticsearch查询完全一致.
下图所示,为这套视觉搜索架构的基本形式.
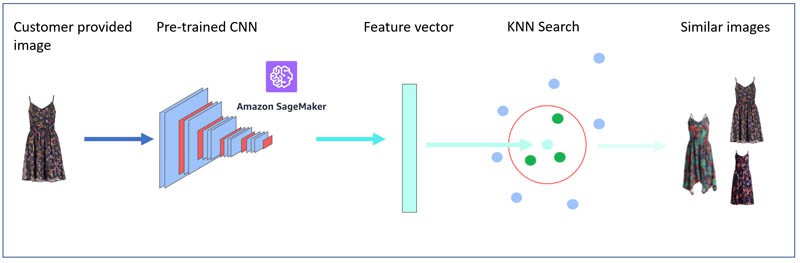
2. 以图搜图方案
视觉搜索架构的实现分为两个阶段:
- 通过示例图像数据集在Amazon ES上构建参考KNN索引.
- 向Amazon SageMaker端点提交一张新图像,并由 Amazon ES返回相似图像.
2.1. 创建KNN推理索引
创建KNN推理索引,托管在Amazon SageMaker当中、且经过预先训练的Resnet50模型,将从每幅图像中提取2048个特征向量. 每个向量都被存储在Amazon ES域的KNN索引当中.
例如,以 Zalando 提供的FEIDEGGER数据集,包含8732张高分辨率时尚图像.
如图所示,为KNN索引的创建工作流程.
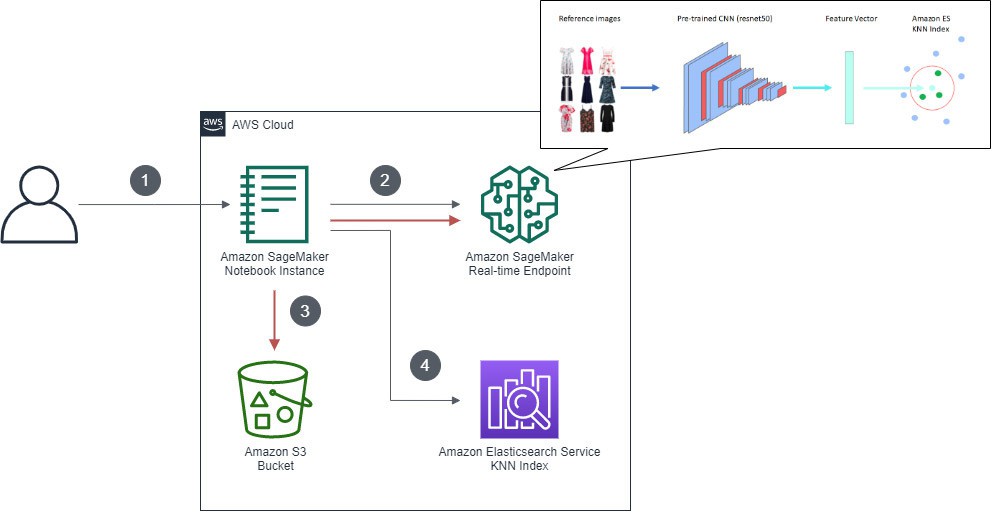
整个流程包含以下操作步骤:
[1] - 用户与Amazon SageMaker noteoobk实例上的Jupyter notebook进行交互.
[2] - 从Keras处下载经过预先训练的Resnet50深层神经网络,删除最后一个分类器层,并对新的模型工件进行序列化,而后存储在Amazon Simple Storage Service(Amazon S3)当中. 该模型负责在Amazon SageMaker实时端点上启动TensorFlow Serving API.
[3] - 将时尚图像推送至端点,端点通过神经网络运行图像以提取其中的特征(或称嵌入).
[4] - Notebook代码将图像嵌入写入至Amazon ES域中的KNN索引.
2.2. 通过查询图像进行视觉搜索
来自于应用程序的查询图像,通过Amazon SageMaker托管模型进行传递,并在此期间提取2048维特征. 可以使用这些特征来查询Amazon ES中的KNN索引.
Amazon ES的KNN将在向量空间中搜索各点,并根据欧几里德距离或余弦相似度(默认值为欧几里德距离)找到这些点的“最近邻”.
在找到给定图像的最近邻向量(例如k=3最近邻)时,它会将与之关联的Amazon S3图像返回至应用程序.
如图所示,为视觉搜索全栈应用程序的基本架构.
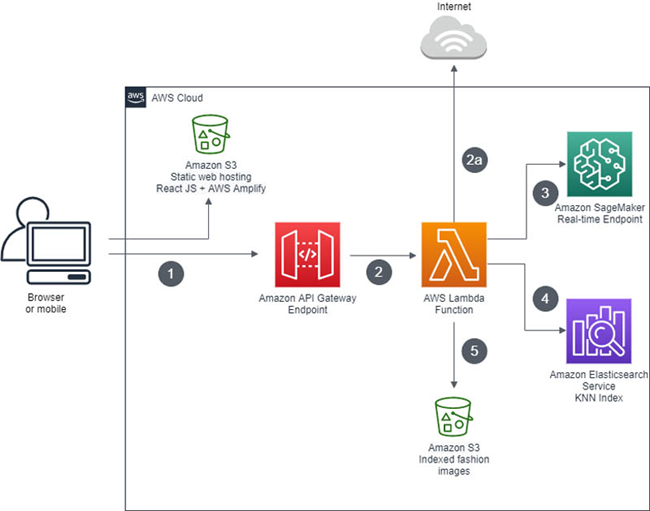
整个流程包含以下操作步骤:
[1] - 终端用户通过自己的浏览器或移动设备访问Web应用程序.
[2] - 用户上传的图像以 base64 编码字符串的形式被发送至 Amazon API Gateway 与 AWS Lambda,并在Lambda函数中重新编码为字节形式.(公开可读的图像URL以字符串形式传递,并可下载为字节形式.
[3] - 各字节作为载荷被发送至Amazon SageMaker实时端点,而后由模型返回图像嵌入的向量.
[4] - 该函数将搜索查询中的图像嵌入向量传递至Amazon ES域内索引中的k近邻,而后返回一份包含k相似图像及其对应Amazon S3 URI的列表.
[5] - 该函数生成经过预签名的Amazon S3 URL并返回至客户端Web应用程序,此URL用于在浏览器中显示相似图像.
2.3. 相关AWS服务
要构建这样一款端到端应用程序,需要使用以下AWS服务:
- AWS Amplify – AWS Amplify 是一套面向前端与移动开发人员的JavaScript库,用于构建云应用程序. 关于更多详细信息,请参阅GitHub repo.
- Amazon API Gateway – 一项全托管服务,用于以任意规模创建、发布、维护、监控以及保护API.
- AWS CloudFormation – AWS CloudFormation 为开发人员及企业提供一种简便易行的方法,借此创建各AWS与相关第三方资源的集合,并以有序且可预测的方式进行配置.
- Amazon ES – 一项托管服务,能够帮助用户以任意规模轻松部署、运营以及扩展Elasticsearch集群.
- AWS IAM – AWS身份与访问管理(AWS Identity and Access Management,简称IAM) 帮助用户安全地管理指向各AWS服务与资源的访问操作.
- AWS Lambda – 一套事件驱动型、无服务器计算平台,可运行代码以响应事件,并自动管理代码所需的各项计算资源.
- Amazon SageMaker – 一套全托管端到端机器学习平台,用于以任意规模构建、训练、调优以及部署机器学习模型.
- AWS SAM– AWS Serverless Application Model (AWS SAM)是一套开源框架,用于构建无服务器应用程序.
- Amazon S3 – 一项对象存储服务,可提供具备极高持久性、可用性、成本极低且可无限扩展的数据存储基础设施.
3. 整体实现
https://github.com/aws-samples/amazon-sagemaker-visual-search/blob/master/visual-image-search.ipynb
依赖项:
- tqdm
- elasticsearch
- requests
- requests-aws4auth
实现过程如下:
Amazon 基础环境设置:
import boto3
import re
import sagemaker
from sagemaker import get_execution_role
role = get_execution_role()
s3_resource = boto3.resource("s3")
s3 = boto3.client('s3')
cfn = boto3.client('cloudformation')
def get_cfn_outputs(stackname):
outputs = {}
for output in cfn.describe_stacks(StackName=stackname)['Stacks'][0]['Outputs']:
outputs[output['OutputKey']] = output['OutputValue']
return outputs
## Setup variables to use for the rest of the demo
cloudformation_stack_name = "vis-search"
outputs = get_cfn_outputs(cloudformation_stack_name)
bucket = outputs['s3BucketTraining']
es_host = outputs['esHostName']3.1. Zalando 数据集下载
Zalando 数据集中共 8732 张高分辨率图像,每张图片都是白色背景的连衣裙.
数据集:https://github.com/zalandoresearch/feidegger
import os
import shutil
import json
import tqdm
import urllib.request
from tqdm import notebook
from multiprocessing import cpu_count
from tqdm.contrib.concurrent import process_map
images_path = 'data/feidegger/fashion'
filename = 'metadata.json'
my_bucket = s3_resource.Bucket(bucket)
if not os.path.isdir(images_path):
os.makedirs(images_path)
def download_metadata(url):
if not os.path.exists(filename):
urllib.request.urlretrieve(url, filename)
#download metadata.json to local notebook
download_metadata('https://raw.githubusercontent.com/zalandoresearch/feidegger/master/data/FEIDEGGER_release_1.1.json')
def generate_image_list(filename):
metadata = open(filename,'r')
data = json.load(metadata)
url_lst = []
for i in range(len(data)):
url_lst.append(data[i]['url'])
return url_lst
def download_image(url):
urllib.request.urlretrieve(url, images_path + '/' + url.split("/")[-1])
#generate image list
url_lst = generate_image_list(filename)
workers = 2 * cpu_count()
#downloading images to local disk
process_map(download_image, url_lst, max_workers=workers)3.2. Zalando 数据集上传至 Amazon S3
# Uploading dataset to S3
files_to_upload = []
dirName = 'data'
for path, subdirs, files in os.walk('./' + dirName):
path = path.replace("\\","/")
directory_name = path.replace('./',"")
for file in files:
files_to_upload.append({
"filename": os.path.join(path, file),
"key": directory_name+'/'+file
})
def upload_to_s3(file):
my_bucket.upload_file(file['filename'], file['key'])
#uploading images to s3
process_map(upload_to_s3, files_to_upload, max_workers=workers)3.3. TensorFlow 模型
采用 TensorFlow 模型来提取图像的特征向量.
import os
import json
import time
import tensorflow as tf
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input
import sagemaker
from PIL import Image
from sagemaker.tensorflow import TensorFlow
# Set the channel first for better performance
from tensorflow.keras import backend
backend.set_image_data_format('channels_first')
print(backend.image_data_format())
#Import Resnet50 model
model = tf.keras.applications.ResNet50(weights='imagenet', include_top=False,input_shape=(3, 224, 224),pooling='avg')
print(model.summary())
#将模型另存为TensorFlow SavedModel格式
dirName = 'export/Servo/1'
if not os.path.exists(dirName):
os.makedirs(dirName)
print("Directory " , dirName , " Created ")
else:
print("Directory " , dirName , " already exists")
#
model.save('./export/Servo/1/', save_format='tf')检验 model 签名:
saved_model_cli show --dir ./export/Servo/1/ --tag_set serve --signature_def serving_default3.4. inference
inference.py
依赖项:
- pip>=20.0.2
- numpy
- pandas
- Pillow
- tensorflow==2.1.0
import io
import json
import base64
import numpy as np
import tensorflow as tf
from collections import namedtuple
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input
from PIL import Image
# restricting memory growth
physical_gpus = tf.config.experimental.list_physical_devices('GPU')
if physical_gpus:
try:
# Currently, memory growth needs to be the same across GPUs
for gpu in physical_gpus:
tf.config.experimental.set_memory_growth(gpu, True)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(physical_gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
# Memory growth must be set before GPUs have been initialized
print(e)
HEIGHT = 224
WIDTH = 224
Context = namedtuple('Context',
'model_name, model_version, method, rest_uri, grpc_uri, '
'custom_attributes, request_content_type, accept_header')
def input_handler(data, context):
""" Pre-process request input before it is sent to TensorFlow Serving REST API
Args:
data (obj): the request data, in format of dict or string
context (Context): an object containing request and configuration details
Returns:
(dict): a JSON-serializable dict that contains request body and headers
"""
if context.request_content_type == 'application/x-image':
# pass through json (assumes it's correctly formed)
#read image as bytes
image_as_bytes = io.BytesIO(data.read())
img = Image.open(image_as_bytes)
img = img.resize((WIDTH, HEIGHT))
# convert PIL image instance to numpy array
img_array = image.img_to_array(img, data_format = "channels_first")
# the image is now in an array of shape (3, 224, 224)
# need to expand it to (1, 3, 224, 224) as it's expecting a list
expanded_img_array = tf.expand_dims(img_array, axis=0)
#preprocessing the image array with channel first
preprocessed_img = preprocess_input(expanded_img_array, data_format = "channels_first")
#converting to numpy list
preprocessed_img_lst = preprocessed_img.numpy().tolist()
return json.dumps({"instances": preprocessed_img_lst})
else:
_return_error(415, 'Unsupported content type "{}"'.format(context.request_content_type or 'Unknown'))
def output_handler(data, context):
"""Post-process TensorFlow Serving output before it is returned to the client.
Args:
data (obj): the TensorFlow serving response
context (Context): an object containing request and configuration details
Returns:
(bytes, string): data to return to client, response content type
"""
if data.status_code != 200:
raise ValueError(data.content.decode('utf-8'))
response_content_type = context.accept_header
prediction = data.content
return prediction,response_content_type
def _return_error(code, message):
raise ValueError('Error: {}, {}'.format(str(code), message))3.5. Amazon SageMaker
import tarfile
#zip the model .gz format
model_version = '1'
export_dir = 'export/Servo/' + model_version
with tarfile.open('model.tar.gz', mode='w:gz') as archive:
archive.add('export', recursive=True)
#Upload the model to S3
sagemaker_session = sagemaker.Session()
inputs = sagemaker_session.upload_data(path='model.tar.gz', key_prefix='model')
#Deploy the model in Sagemaker Endpoint. This process will take ~10 min.
from sagemaker.tensorflow.serving import Model
sagemaker_model = Model(
entry_point='inference.py',
model_data = 's3://' + sagemaker_session.default_bucket() + '/model/model.tar.gz',
role = role, framework_version='2.1.0', source_dir='./src' )
#
predictor = sagemaker_model.deploy(initial_instance_count=3, instance_type='ml.m5.xlarge')
#
# get the features for a sample image
payload = s3.get_object(Bucket=bucket,Key='data/feidegger/fashion/0VB21C000-A11@12.1.jpg')['Body'].read()
predictor.content_type = 'application/x-image'
predictor.serializer = None
features = predictor.predict(payload)['predictions'][0]
print(features)3.6. 构建 ES 中的 KNN 索引
KNN 需要 Elasticsearch 版本在 7.1 以上.
#辅助函数
#return all s3 keys
def get_all_s3_keys(bucket):
"""Get a list of all keys in an S3 bucket."""
keys = []
kwargs = {'Bucket': bucket}
while True:
resp = s3.list_objects_v2(**kwargs)
for obj in resp['Contents']:
keys.append('s3://' + bucket + '/' + obj['Key'])
try:
kwargs['ContinuationToken'] = resp['NextContinuationToken']
except KeyError:
break
return keys
#
# get all the zalando images keys from the bucket make a list
s3_uris = get_all_s3_keys(bucket)
# define a function to extract image features
from time import sleep
sm_client = boto3.client('sagemaker-runtime')
ENDPOINT_NAME = predictor.endpoint
def get_predictions(payload):
return sm_client.invoke_endpoint(EndpointName=ENDPOINT_NAME,
ContentType='application/x-image',
Body=payload)
def extract_features(s3_uri):
key = s3_uri.replace(f's3://{bucket}/', '')
payload = s3.get_object(Bucket=bucket,Key=key)['Body'].read()
try:
response = get_predictions(payload)
except:
sleep(0.1)
response = get_predictions(payload)
del payload
response_body = json.loads((response['Body'].read()))
feature_lst = response_body['predictions'][0]
return s3_uri, feature_lst
#
# This process will take approximately 24-25 minutes on a t3.medium notebook instance
# with 3 m5.xlarge SageMaker Hosted Endpoint instances
from multiprocessing import cpu_count
from tqdm.contrib.concurrent import process_map
workers = 2 * cpu_count()
result = process_map(extract_features, s3_uris, max_workers=workers)
#设置 Elasticsearch 连接.
# setting up the Elasticsearch connection
from elasticsearch import Elasticsearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
region = 'us-east-1' # e.g. us-east-1
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
#
es = Elasticsearch(
hosts = [{'host': es_host, 'port': 443}],
http_auth = awsauth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection
)
#定义 KNN 索引映射
#Define KNN Elasticsearch index maping
knn_index = {
"settings": {
"index.knn": True
},
"mappings": {
"properties": {
"zalando_img_vector": {
"type": "knn_vector",
"dimension": 2048
}
}
}
}
#Creating the Elasticsearch index
es.indices.create(index="idx_zalando",body=knn_index,ignore=400)
es.indices.get(index="idx_zalando")
#
# defining a function to import the feature vectors corrosponds to each S3 URI into Elasticsearch KNN index
# This process will take around ~3 min.
def es_import(i):
es.index(index='idx_zalando',
body={"zalando_img_vector": i[1], "image": i[0]}
)
#
process_map(es_import, result, max_workers=workers)3.7. 验证索引搜索结果
分别采用 SageMaker SDK 和 Boto3 SDK 来查询 ES,以检索最近邻.
#define display_image function
import matplotlib.pyplot as plt
def display_image(bucket, key):
response = s3.get_object(Bucket=bucket,Key=key)['Body']
img = Image.open(response)
plt.imshow(img)
plt.show()
return None
#
import requests
import random
from PIL import Image
import io
urls = []
# yellow pattern dess
urls.append('https://fastly.hautelookcdn.com/products/D7242MNR/large/13494318.jpg')
# T shirt kind dress
urls.append('https://fastly.hautelookcdn.com/products/M2241/large/15658772.jpg')
#Dotted pattern dress
urls.append('https://fastly.hautelookcdn.com/products/19463M/large/14537545.jpg')
img_bytes = requests.get(random.choice(urls)).content
query_img = Image.open(io.BytesIO(img_bytes))
print(query_img)
#SageMaker SDK approach
predictor.content_type = 'application/x-image'
predictor.serializer = None
features = predictor.predict(img_bytes)['predictions'][0]
#
import json
k = 5
idx_name = 'idx_zalando'
res = es.search(request_timeout=30, index=idx_name,
body={'size': k,
'query': {'knn': {'zalando_img_vector': {'vector': features, 'k': k}}}})
for i in range(k):
key = res['hits']['hits'][i]['_source']['image']
key = key.replace(f's3://{bucket}/','')
img = display_image(bucket,key)
#Boto3 SDK
client = boto3.client('sagemaker-runtime')
ENDPOINT_NAME = predictor.endpoint # our endpoint name
response = client.invoke_endpoint(EndpointName=ENDPOINT_NAME,
ContentType='application/x-image',
Body=img_bytes)
response_body = json.loads((response['Body'].read()))
features = response_body['predictions'][0]
#
import json
k = 5
idx_name = 'idx_zalando'
res = es.search(request_timeout=30, index=idx_name,
body={'size': k,
'query': {'knn': {'zalando_img_vector': {'vector': features, 'k': k}}}})
for i in range(k):
key = res['hits']['hits'][i]['_source']['image']
key = key.replace(f's3://{bucket}/','')
img = display_image (bucket,key)