原文:阿里巴巴首次揭秘电商知识图谱AliCoCo!淘宝搜索原来这样玩! - 2020.03.31
出处:阿里机器智能 - 微信公众号
团队:搜索推荐事业部认知图谱团队 Xusheng Luo, Luxin Liu, Yonghua Yang, Le Bo, Yuanpeng Cao, Jinhang Wu, Qiang Li, Keping Yang and Kenny Q. Zhu
电商技术进入认知智能时代,将给亿万用户带来更加智能的购物体验. 经过两年的探索与实践,阿里巴巴的电商认知图谱 AliCoCo 已成体系规模,并在搜索推荐等电商核心业务场景上取得佳绩,关于 AliCoCo 的文章《AliCoCo: Alibaba E-commerce Cognitive Concept Net》也已被国际顶会 SIGMOD 接收,这是阿里巴巴首次正式揭秘领域知识图谱.
本文将通过介绍 AliCoCo 的背景、定义、底层设计、构建过程中的一些算法问题,以及在电商搜索和推荐上的广泛应用,分享 AliCoCo 从诞生到成为阿里巴巴核心电商引擎的基石这一路走来的思考.
1. 背景
近年来电商搜索、推荐算法已经取得了长足的进步,但面对用户多样化的需求,目前的电商体验依然还称不上“智能”. 多年来,我们的搜索引擎在引导用户如何输入关键字才能更快地找到需要的商品,而这种基于关键字的搜索,适用于对明确清楚具体商品的用户. 但很多时候,用户面临的往往是一些问题或场景,如“举办一场户外烧烤”需要哪些工具?在淘宝上购买什么商品能有效“预防家里的老人走失”?他们需要更多的“知识”来帮助他们决策. 而在商品推荐中,重复推荐、买过了又推荐、推荐缺少新意等问题也是经常为人诟病. 当前的推荐系统更多的是从用户历史行为出发,通过 i2i 等手段来召回商品,而不是真正从建模用户需求出发.
深究这些问题背后的原因,其根源在于电商技术所依赖的底层数据,缺少对于用户需求的刻画. 具体来讲,目前淘宝用于管理商品的体系,是一套基于类目-属性-属性值(CPV,Category-Property-Value)的体系,它缺乏必要的知识广度和深度,去描述和理解各类用户需求,从而导致基于此的搜索、推荐算法在认知真实的用户需求时产生了语义的隔阂,从而限制了用户体验的进一步提升.
为了打破这个隔阂,让电商搜索、推荐算法更好地认知用户需求,我们提出建设一种新的电商知识图谱,将用户需求显式地表达成图中的节点,构建一个以用户需求节点为中心的概念图谱,链接用户需求、知识、常识、商品和内容的大规模语义网络:阿里巴巴电商认知图谱(Alibaba E-commerce Cognitive Concept Net),简称 AliCoCo. 我们希望 AliCoCo 能为电商领域的用户理解、知识理解、商品和内容理解提供统一的数据基础. 经过两年的努力,我们已经完成了整体的结构设计和核心数据的建设,并在电商搜索、推荐等多个具体的业务场景落地,取得了不错的效果,提升了用户体验.
2. AliCoCo
如下图所示,AliCoCo 是一个概念图谱,主要由四部分构成:
- 电商概念层(E-commerce Concepts)
- 原子概念层(Primitive Concepts)
- 分类体系(Taxonomy)
- 商品层 (Items)
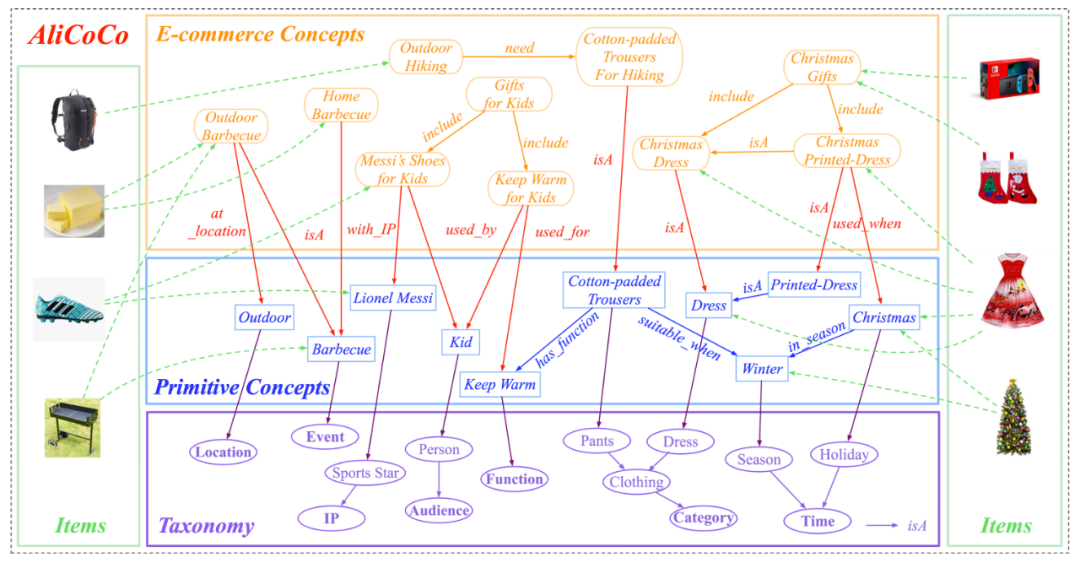
在电商概念层(E-commerce Concepts),作为 AliCoCo 最大的创新点,我们将用户需求显式地用一个符合人话的短语表示为图中的节点,如“户外烧烤(outdoor barbecue)”、“儿童保暖(keep warm for kids)”等,并称之为“电商概念”. 用户需求虽然一直被提及,但在电商领域,还未被正式地定义过. 在很多下游应用(如推荐系统)的工作中,常常用类目或品类节点(商品的分类)作为用户需求的表达. 但用户需求是远不止于这些的,很多场合下,用户面临的是一个“场景”或者“问题”,他们并不知道具体什么商品可以帮助解决,因此我们将用户需求的定义进一步泛化为电商概念,具体详见下文章节. 所有用于表示用户需求的电商概念组成了这一层.
在原子概念层(Primitive Concepts),我们为了更好地理解上面讲到的电商概念(即用户需求),我们将这些短语进行拆解细化到词粒度,用这些细粒度的词来更系统地描述用户需求,这些细粒度的词称为“原子概念”. 如对于电商概念“户外烧烤”而言,它可以被表示成“动作:烧烤 & 地点:户外 & 天气:晴”,这里的“烧烤”、“户外”和“晴”都是原子概念. 所有原子概念组成了这一层.
在分类体系(Taxonomy)中,为了更好地管理上述的原子概念,我们构建了一个描述大千世界基本概念的分类体系,它不局限于电商领域,但目前是为电商领域的概念理解所服务. 在这一层中,我们定义了诸如“时间”、“地点”、“动作”、“功能”、“品类”、“IP”等一级分类(class),并在每个分类下继续细分出子分类,形成一颗树形结构. 在每个分类中,包含了分类的实例(instance),即原子概念,如上述的“烧烤”、“户外”和“晴”就分属于“动作 - 消耗性动作”、“地点 - 公共空间”和“时间 - 天气”. 同时,不同分类之间有不同的关系(relation),如“品类 - 服饰 - 服装 - 裤子”和“时间 - 季节”之间定义了一个“适用于(季节)”的关系. 因此,相应的会有一条三元组实例:<棉裤,适用于,冬季>.
如果将上述的分类体系和原子概念层合起来,实际上可以看做一个相对完整的本体(Ontology),它和 Freebase、DBpedia 等大家熟知的开放领域的知识图谱非常相似,唯一的区别是我们的实例不仅有实体(entity),还包括了大量的概念(concept). 而相比 Probase,ConceptNet 等概念图谱,我们又定义了一套完整的类型系统(type system).
在商品(内容)层,阿里巴巴平台上数十亿的商品和内容,将会和电商概念、原子概念层进行关联. 如和“户外烧烤”相关联的商品可能会包括烧烤架、炭火、食材等等. 但这里要注意的一点是,有些商品可以关联到“户外烧烤”这个电商概念,但不一定可以和相应的原子概念“户外”直接关联. 对于商品来说,电商概念像是这个商品会被用于的某个场景,而原子概念更像是细粒度的属性,用于刻画商品的特性.
综上所述,在 AliCoCo 的体系中,用户需求被表达成短语级别的电商概念. 在这之下,有一套定义完备的分类体系和原子概念实例去描述所有的电商概念. 最后,电商平台上的所有商品都会和电商概念或是原子概念相关联. 下面,我们详细介绍每一层的细节以及在构建过程中所遇到的算法问题.
2.1. 分类体系(Taxonomy)
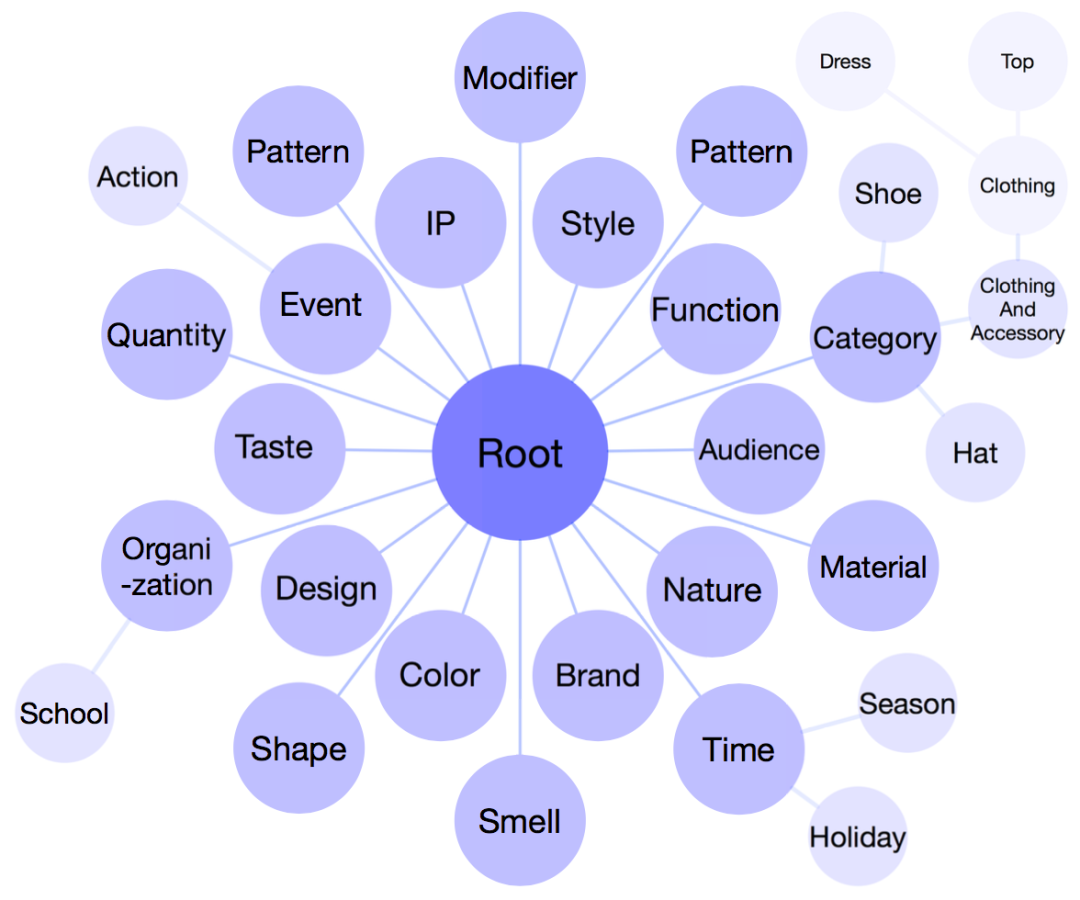
AliCoCo 的分类体系是一个巨大的树形结构,包含了百万级别的原子概念实例. 由于分类体系的构建,对专家知识的要求非常高,并且这部分的设计对于整个知识体系都至关重要,因此我们人工定义了约 20 个一级分类(下图),其中专为电商领域所设计的有:“品类”、“图案”、“功能”、“材质”、“花色”、“形状”、“气味”、“口味”. 每个一级分类还会继续细分为二级、三级,直至叶子分类,其中对于电商领域最为重要的“品类”包含了约800个叶子分类. 诸如“时间”、“地点”、“受众”、“IP”等分类和开放领域的知识图谱可以交融,如“IP”中包含了大量的明星、运动员、电影、音乐等.
2.2. 原子概念层 (Primitive Concepts)
在原子概念层,我们希望这些细粒度的词能够去完整地描述所有的用户需求,这是用于组成电商概念的基础,在这一层,我们主要讨论两个问题:
- 原子概念词汇的挖掘
- 原子概念之间的上下位关系构建
2.2.1. 词汇挖掘
在定义好分类体系之后,一般有两种方式快速扩充分类下的实例(词汇). 第一种是融合多种来源的结构化数据,这种方法采用的技术通常是本体对齐(ontology matching),在实践过程中,我们主要采用规则+人工映射的方式将不同来源的结构化数据对齐到我们的分类体系进行词汇的融合. 第二种是通过在大规模的语料上进行自动挖掘来补充分类下的词汇,这里我们将其定义为序列标注任务,并采用基于 BiLSTM+CRF [1] 的模型来挖掘发现分类下的新词. 由于叶子分类的数量过于庞大,我们使用一级分类作为label,先对词汇进行粗粒度的挖掘.

上图为 BiLSTM+CRF 模型的简单示意,BiLSTM(双向 LSTM)层用于捕捉句子上下位的语义特征,而 CRF(条件随机场)层则用于捕捉当前词的 label 和前后词 label 之间的相关性. 而在模型挖掘得到可能属于某个分类的新词之后,后续还会经由众包投放审核、外包质检等人工把关环节,最终才会入库成为真正的原子概念. 不同的原子概念可能拥有相同的名字,但分属不同的类别,代表了不同的语义,每个原子概念有一个 ID,这也是 AliCoCo 未来可以用概念消歧的基础.
2.2.2. 上下位关系构建
在某个一级分类下的词汇挖掘到一定量后,我们需要继续讲所有词汇分到不同层次的类别中去,这个过程可以抽象成为一个上下位关系发现(hypernym discovery)的过程:给定一个下位词,在词表中找到其可能的上位词. 我们采用基于 pattern 的无监督方法和基于 projection learning 的监督方法两种方式结合来完成上下位关系的构建.
Pattern based
基于 pattern 的方式 [2] 是最直观且准确率最高的方法,通过归纳和发现一些可用于判断上下位关系的 pattern,从文本句子中直接抽取上下位词对. 典型的 pattern 如“XX,一种XX”、“XX,包括XX”等. 但这种方式的缺点是默认上下位词对在句子中必须共现,会影响召回. 此外,利用中文的一些特点,我们可以用过“XX裤”一定是“裤子”等来自动构建起一批置信度较高的上下位关系.
Projection learning
Projection learning 的方式是给定一个下位词 embedding $\pmb{p}$ 和上位词 embedding $\pmb{h}$,有监督去学习一个映射函数 $f$,使得 $f(\pmb{p})$ 和 $\pmb{h}$ 尽可能地接近. 这方面有很多前人的工作 [3, 4],其中有一些工作会先将不同的词进行聚类,在每个类别上分别学习不同的映射,取得了较好的效果.
具体地,我们学习一个打分函数,用于表征一对候选词之间的上下位关系强弱,并使用多个 matrix 来模拟不同维度的特征(隐式的聚类),其中第 k个 score 计算如:
$$ s^k = \pmb{p}^T \pmb{T}^k \pmb{h} $$
最后将 k 个 score 过一层全连接得到最终的probability:
$$ y = \sigma(\pmb{W} \pmb{s} + \pmb{b}) $$
之后我们采用交叉熵损失函数进行训练. 模型中使用的预训练的词向量是在前面提到的电商语料上用 word2vec 进行训练的. 同时,我们针对部分品类词在语料中出现较为稀疏的问题,用 ALaCarte embedding [5] 进行了强化,其主要思想是学习一个映射关系矩阵 $\pmb{A}$,利用稀疏词 $x$ 周围的 context 的 embeddings 之和 $\pmb{u}_x$ 对其进行表征:
$$ \pmb{v}_x = \pmb{A} \pmb{u}_x = \pmb{A} (\frac{1}{|C_x|} \sum_{c} \sum_{w} \pmb{v} _w) $$
而 $\pmb{A}$ 可以通过利用语料中所有的词 $w$ 进行训练得到:
$$ \pmb{A} = arg \ min \sum ||\pmb{v}_w - \pmb{A} \pmb{u}_w||_2^2 $$
Active learning
模型产出候选和众外包审核是一个同时进行的过程,人工审核的数据可以不断反哺强化模型. 因此,我们在迭代的过程中,考虑用 active learning 来进一步提升效率,降低人工审核的成本. 我们采用了一种 uncertainty and high confidence (UCS) 的 sampling strategy,除了考虑模型难以判断正负的样例之外(预测值接近 0.5),我们还额外添加了一定比例的高置信度判正的样例一起送标,这是因为在上下位关系的判别中,很容易被诸如同义或者相关关系所干扰,尤其在前期样本数量少且质量不一,以及负采样不均衡的情况下,模型对于区分相关关系和上下位的表现不是太好. 而通过人工标注纠正这样的判断错误,可以及时惩罚这一类的误判. 实验表明这样的策略可以帮助我们减少 35% 的人力成本.
2.3. 电商概念层 (E-commerce Concepts)
在电商概念层,每一个节点代表了一种购物需求,这种购物需求可以用至少一个原子概念来描述. 我们首先介绍电商概念的定义,然后介绍电商概念是如何被挖掘和生成的,最后介绍电商概念和原子概念之间的链接.
2.3.1. 电商概念的定义
我们定义一个符合标准的电商概念,需要满足以下要求:
1)有消费需求
即一个电商概念必须可以让人很自然地联想到一系列商品,反例如“蓝色天空”、“母鸡下蛋”等就不是电商概念.
2)通顺
反例如“仔细妈咪肥皂”等就不是电商概念.
3)合理
即一个电商概念必须符合人类常识,反例如“欧式韩风窗帘”、“儿童性感连衣裙”等就不是电商概念,因为一个窗帘不可能即是欧式还是韩风的,而我们通常不会用性感去修饰一件儿童的连衣裙.
4)指向明确
即一个电商概念必须有明确的受众,反例如“儿童宝宝辅食”等就不是电商概念,因为儿童的辅食和宝宝的辅食差别较大,会造成用户的疑惑.
5)无错别字
反例如“印渡神油”等.
2.3.2. 电商概念的生成
我们采用一个两阶段的方式来生成电商概念:首先我们用两种不同的方式生成大量的候选,然后用一个判别模型来过滤那些不满足我们的标准的候选.
候选生成
候选生成有两种方式,一种是从文本语料中去挖掘可能的短语,这里我们采用了 AutoPhrase [6] 在大规模的语料上进行挖掘,语料包括电商生态内的 query log,商品的标题、评论,还有很多达人商户写的购物攻略等. 另一种方式是用词粒度的原子概念进行组合生成短语粒度的电商概念. 我们挖掘并人工审核了一些 pattern 来赋值生成,部分 pattern 如下图所示:

我们可以通过“[事件]用的[功能] [品类]”这个 pattern 来生成“旅游用的保暖帽子”这样的电商概念. 而这些 pattern 可以和下面的判别过程结合,通过迭代的方式来进行不断地挖掘和补充.
2.3.3. 电商概念判别
判断一个候选短语是否满足电商概念的要求,最大的挑战是上文提到的第三点,即“合理”,要符合人的常识. 其他一些要求我们可以通过字级别或是词级别的语言模型就能过滤掉大部分的 badcase,但常识错误的识别对机器来说是非常困难的. 此外,电商概念判别任务中的候选短语又严重缺少上下文信息,进一步增加了判别的难度.
为了解决这个难题,我们设计了一种知识增强的判别模型(如下图所示),整体是一个 Wide&Deep [7] 的结构. 在 Deep 侧,我们利用字级别和词级别的 BiLSTM 来提取特征,同时对于词级别的输入,我们还加入了一些词性特征如 POS tag 和 NER label 等. 为了进行知识增强来辅助常识理解,我们将部分词链接到 Wikipedia 上,如“性感”就可以找到对应的页面. 然后将页面上的 gloss(通常是一段简单的介绍)用 Doc2vec [8] 的方式进行 encode 得到知识表达. 在经过 self-attention + max-pooling 之后将两者融合. 在 Wide 侧,我们主要计算了 concept 的一些统计特征,包括了 BERT [9] 语言模型产出的 ppl 值. 最后,通过一个全连接层我们得到最终衡量一个候选短语是否符合电商概念要求的分数.

我们希望模型能辅助我们过滤掉大量的 badcase,此后我们对模型判别正确的电商概念通过众包投放审核和外包多轮质检的方式来保证数据质量. 同时,审核入库的数据会继续迭代地帮助模型进一步提高准确率.
2.3.4. 和原子概念的链接
对于那些通过从原子概念组合而得到的电商概念,它们天然地和原子概念关联了起来,但对于那些从文本中直接挖掘得到的短语概念,我们需要进一步将它们和原子概念层进行链接,以便更好地去理解和描述这些用户需求. 回顾前文提到的电商概念“户外烧烤”,我们需要预测“户外”是一个“地点”,“烧烤”是一个“动作”. 但“烧烤”在我们的体系中也有可能是一个“电影”,所以这里的难点在于如何进行消歧. 我们把这个任务定义为一个短文本的 NER 任务,由于电商概念普遍只有 2-3 个词组成,缺少上下文也让这个任务具有挑战.
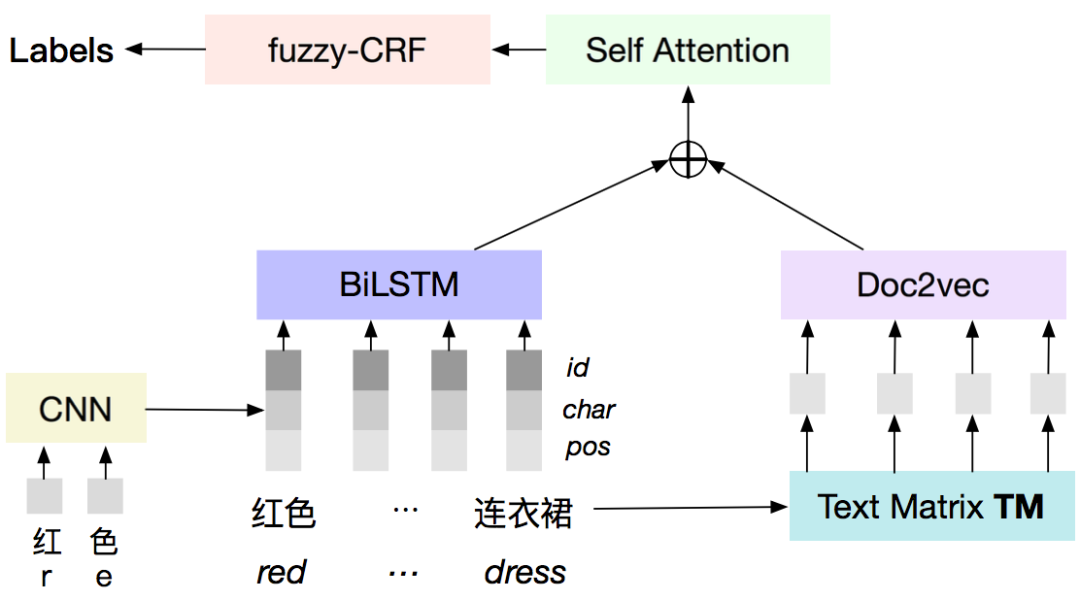
为了解决这个问题,我们设计了一种文本增强的方式,对短文本中待链接的词进行外部上下文的补充,用以为消歧带来额外的信息辅助. 模型如上图所示,左边部分是比较常规的特征抽取,右边是一个信息增强的模块. 我们将目标词映射到高质量的外部文本中,通过 doc2vec 将其周边的上下文信息 encode 成 embedding,最终最为额外的输入融合到最终的表达中. 此外,由于部分电商概念中的原子概念可以属于多个类型,如“乡村半身裙”中的“乡村”,既可以是“地点”,也可以是“风格”. 因此我们将 CRF 层改为 Fuzzy-CRF [10],用以建模多个正确的 label 序列:

2.4. 商品关联 (Item Association)
在构建完原子概念和电商概念层之后,最重要的是将电商平台上的所有商品进行关联. 前面提到原子概念更像是属性,因而我们更关注商品与电商概念的关联,因为后者表达的是一个用户需求,常常有着较为复杂的语义. 此外,电商概念与商品的关联不能直接从对应的原子概念到商品的关联组合得到,因为会出现“语义漂移”的问题. 例如“户外烧烤”所需要的商品,往往和属性“户外”没有任何关系. 我们将这个问题抽象为一个语义匹配(semantic match)[11, 12] 的问题,因为现阶段我们暂时只用到商品侧标题的信息(实际上商品是一个多模态的结构,有着非常丰富的文本、图像甚至越来越多的商品开始有了短视频的介绍). 这个任务最大的挑战依旧在于我们的电商概念非常简短,直接进行匹配,往往会遇到诸如某些不那么重要词对结果产生了巨大的影响等问题.
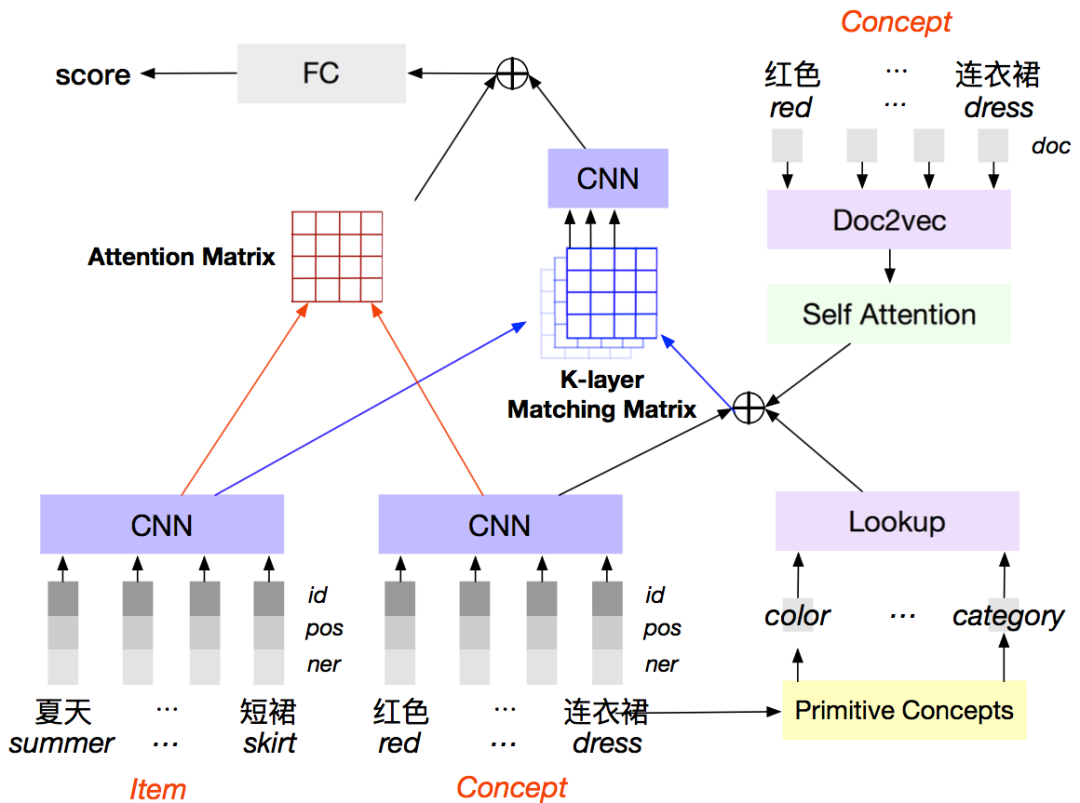
针对上述难点,我们在语义匹配模型上引入了一些必要的外部知识来提升性能. 具体模型如上图所示,除了常规的特征抽取,attention 注意力机制模块等建模商品和电商概念之间的关联外,我们主要做了两个地方的增强:
1)引入了电商概念对应的原子概念的特征表达,增加了类型等结构化信息.
2)引入外部 Wikipedia gloss,对部分词进行知识增强,以更好地建立与商品之间的关联. 引入这些知识带来的典型的优点,例如在关联“中秋节送礼”时,可以把不包含中秋节字样的的月饼类商品给排上来.
3. 应用
目前,AliCoCo 已经基本完成了 1.0 版本的建设,共包含 2.8m 的原子概念,5.3m 的电商概念,超过千亿级别的关系. 淘宝天猫上超过 98% 的商品均已纳入到 AliCoCo 的体系之中,平均每个商品关联了 14 个原子概念和 135 个电商概念. 通过对用户需求的统计,相较于之前的商品管理体系,AliCoCo 对于搜索 query 中用户需求的覆盖从35%提升到了 75%.
AliCoCo 已经支持了阿里巴巴集团核心电商的多个业务应用,这里我们主要介绍在电商搜索和推荐上已经落地的、正在进行的,以及将要进行的一些应用.
3.1. 电商搜索
相关性是搜索引擎的核心问题,其最大的挑战在于用户输入的 query 和商品端之间存在语义隔阂. AliCoCo 中已经为大量的原子概念和电商概念关联了相应的商品,为商品理解提供了从用户视角出发的大量标签,同时 AliCoCo 包含了大量的同义和上下位关系,这些数据帮助了搜索相关性取得显著的提升,从而进一步改善了用户体验.
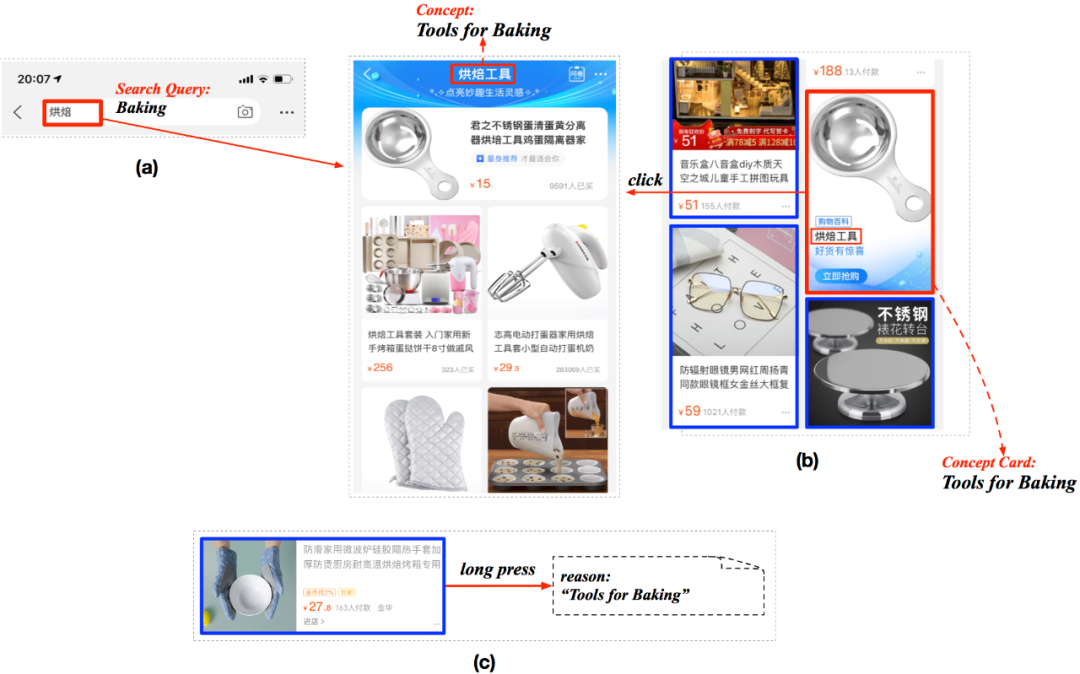
语义搜索和自动问答一直人们对于搜索引擎的梦想. 在电商的场景中,我们可以充分发挥 AliCoCo 的优势,当用户搜索命中电商概念的时候,通过一个知识卡片的形式透出该电商概念下多样化的商品,类似 Google 的知识图谱帮助搜索引擎在用户检索一些实体时透出知识卡片. 如上图(a)所示,当用户在淘宝搜索“烘焙”时,命中了相应的电商概念“烘焙工具”,于是会透出一个卡片,上面的商品按照不同品类来进行排序展示. 此外,我们还可以透出一些对于烘焙知识的文字解释用于辅助用户进行决策. 而电商场景中的自动问答,更多出现在语音交互的场景中,我们可以在家里问天猫精灵“周末要组织一场户外烧烤,我需要准备哪些东西?”,AliCoCo 可以为这样的场景提供底层知识的支持.
3.2. 电商推荐
目前电商推荐主要以商品推荐的形式为主,但为了满足用户丰富多样的购物需求,我们也需要为用户做一些主题式的推荐,让用户能够明显感知到推荐系统能更人性化地在满足其购物需求. AliCoCo 中的电商概念,正是为了表达用户需求,同时 2-3 个词的长度也非常适合直接推送给用户. 如上图(b)中所示,在手机淘宝首页信息流推荐中,我们在商品坑位之间插入了以电商概念为主题的知识卡片,当用户点击卡片时,就会跳到相应的页面,展示该电商概念下的商品. 这个应用目前已经稳定运行了超过一年,满足了用户多样化的推荐需求,进一步提升了用户的满意度.
此外,电商概念简短的文字也非常适合用作推荐理由展示在商品坑位中,进一步吸引用户,如上图(c)所示. AliCoCo 为可解释的推荐提供了数据基础.
4. 总结
为了支持电商技术从个性化时代全面迈入认知智能时代,我们投入了巨大的心血和努力探索并构建了全新一代的电商知识图谱 AliCoCo,目前 AliCoCo 已成为阿里巴巴电商核心引擎的底层基础,赋能搜索、推荐、广告等电商核心业务. 同时,通过海量的线上用户反馈,AliCoCo 也在不断地对其自身的结构和数据进行补充与完善,形成了一个良性生长的循环. 对于 AliCoCo 2.0 的方向,我们未来考虑:
1)继续补充大量电商常识性关系,如将电商概念与原子概念的链接,从短文本 NER 扩展成属性推理任务,我们需要为“男孩T恤”预测出“季节:夏天”,尽管“夏天”没有出现在文本之中,这样的购物常识对于进一步理解用户需求、改善购物体验是非常有帮助的.
2)将电商概念和商品之间的关系建模为概率分,根据分数来进一步将用户体感进行分层,让用户有更明显的感知.
3)AliCoCo 将响应集团国际化和本地化的战略,朝着多语言(multi-lingual)和餐饮等方向进行探索.
参考文献
[1] Zhiheng Huang, Wei Xu, and Kai Yu. 2015. Bidirectional LSTM-CRF models for sequence tagging. arXiv (2015).
[2] Marti A. Hearst. 1992. Automatic acquisition of hyponyms from large text corpora. In Proceedings of the 14th conference on Computational linguistics - Volume 2, volume 2, pages 539–545. Association for Computational Linguistics.
[3] Josuke Yamane, Tomoya Takatani, Hitoshi Yamada, Makoto Miwa, and Yutaka Sasaki. 2016. Distributional hypernym generation by jointly learning clus- ters and projections. In Proceedings of COLING 2016, the 26th International Conference on Compu- tational Linguistics: Technical Papers, pages 1871– 1879.
[4] Dmitry Ustalov, Nikolay Arefyev, Chris Biemann, and Alexander Panchenko. 2017. Negative sampling improves hypernymy extraction based on projection learning. In Proceedings of the 15th Conference of the European Chapter of the Association for Compu- tational Linguistics: Volume 2, Short Papers, pages 543–550, Valencia, Spain. Association for Compu- tational Linguistics.
[5] Khodak, Mikhail, et al. "A la carte embedding: Cheap but effective induction of semantic feature vectors." arXiv preprint arXiv:1805.05388 (2018).
[6] Jingbo Shang, Jialu Liu, Meng Jiang, Xiang Ren, Clare R Voss, and Jiawei Han. 2018. Automated phrase mining from massive text corpora. IEEE Transactions on Knowledge and Data Engineering 30, 10 (2018), 1825–1837.
[7] Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Rec- ommender Systems. ACM, 7–10.
[8] Quoc Le and Tomas Mikolov. 2014. Distributed representations of sen- tences and documents. In International conference on machine learning. 1188–1196.
[9] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
[10] Jingbo Shang, Liyuan Liu, Xiang Ren, Xiaotao Gu, Teng Ren, and Jiawei Han. 2018. Learning named entity tagger using domain-speci c dictionary. arXiv preprint arXiv:1809.03599 (2018).
[11] Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management. ACM, 2333–2338.
[12] Liang Pang, Yanyan Lan, Jiafeng Guo, Jun Xu, Shengxian Wan, and Xueqi Cheng. 2016. Text matching as image recognition. In Thirtieth AAAI Conference on Arti cial Intelligence.