论文:PointRend: Image Segmentation as Rendering - 2019
作者:Alexander Kirillov, Yuxin Wu, Kaiming He, Ross Girshick
团队:Facebook AI Research, FAIR
实现:Github - detectron2/projects/PointRend
摘要:
PointRend 提出一种新的有效高质量图像分割的方法. 主要通过模拟经典计算机图形学中关于像素级标注任务中所面临的过采样和欠采样问题的有效渲染(rendering),提出一种新的观点:将图像分割任务作为渲染问题进行处理. 即:PointRend - Point-based Rendering.
PointRend 网络模块是:基于迭代细分算法(iterative subdivision algorithm) 自适应地选择像素位置,以进行基于点的分割预测.
PointRend[Point-based Rendering] neural network module: a module that performs point-based segmentation predictions at adaptively selected locations based on an iterative subdivision algorithm.
PointRend 可以灵活地用于实例分割和语义分割任务中.
PointRend 能够提升在以往算法所过度平滑预测区域导致的边界问题.
1. Introduction
图像分割任务是将在规则网格(regular grid)所采样的像素,映射为相同网格内的 label map 或者 label maps 的集合.
语义分割任务中,label map 表示了每个像素的预测类别.
实例分割任务中,label map 表示了关于每个检测到的物体的前景vs背景的二值图.
图像分割中的CNNs,往往是在规则网格上进行操作的:输入图像是像素的规则网格;其隐藏表示为在规则网格上的特征向量;输出为在规则网格上的 label maps.
CNNs 网络预测输出的 label maps 应该是几乎平滑的,如,相邻像素往往具有相同类别标签,这是因为高频区域往往位于两个物体间的稀疏边界处(sparse boundaries between objects). 规则网格(regular grid)不仅不必要地过采样平滑区域,同时欠采样物体边界. 其会导致在平滑区域(smooth regions)进行了过度计算以及轮廓模糊(blurry contours). 如下图左上图.
图像分割往往是在低分辨率规则网格上进行的,比如,语义分割是输入图像尺寸的 1/8; 实例分割是 28x28.

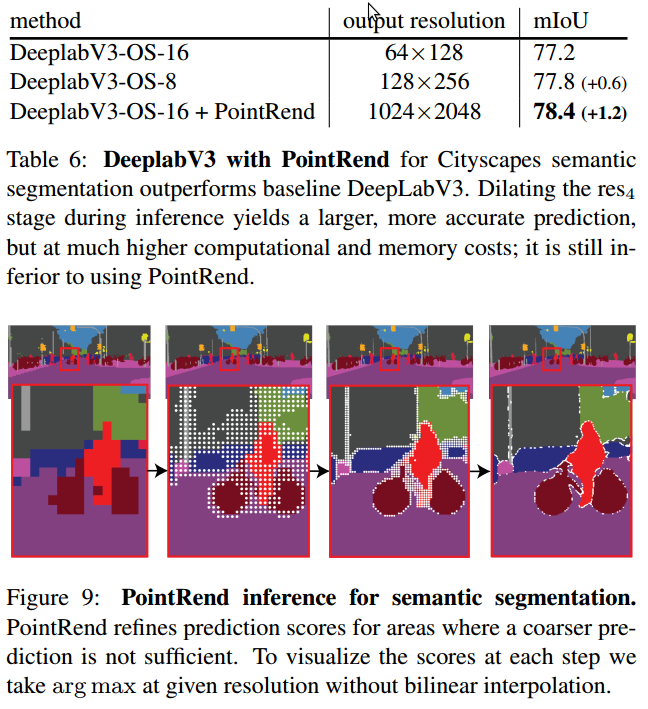
图1:PointRend 实例分割. PointRend 模块通过采用基于点的特征表示,自适应的采样点,以进行分割预测. 对比发现,PointRend 得到了更细节化的结果(右上). 在预测时,PointRend 迭代的计算预测. 每次迭代对平滑区域进行双线性上采样,通过自适应的采样少量更可能属于边界的点(黑丝额点)来得到更高分辨率的预测.
在计算机图形学领域,面临类似的采样问题. 例如,渲染(render)将模型(如3D网格)映射到光栅化图像(rasterized image),如像素的规则网格. 虽然输出是在规则网格上,但计算并不是均匀的分布在每个网格上. 通用的图形学策略是,在图像平面上自适应的选择一些点,并在这些点的不规则子集上计算像素值(compute pixel values at an irregular subset of adaptively selected points in the image plane).
PointRend 的核心思想是,将图像分割问题看作是渲染问题,并采用计算机图形学中的经典思想,有效的渲染得到高质量的 label maps. 其采用了 subdivision 策略,自适应地选择非均匀点集上计算 labels (PointRend uses a subdivision strategy to adaptively select a non-uniform set of points at which to compute labels.) PointRend 是一个迭代上采样输出的过程.
2. PointRend
PointRend, Point-based Rendering.
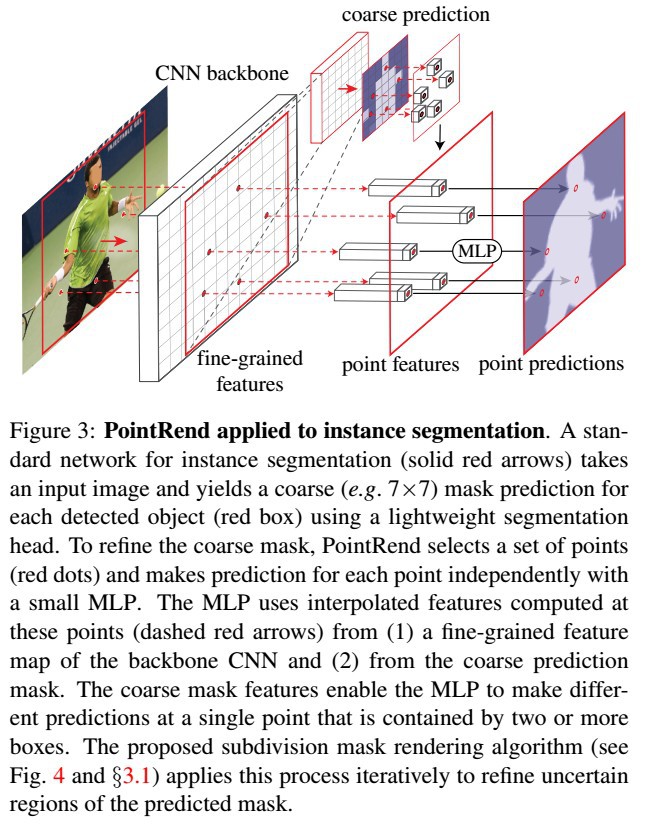
PointRend 模块,其输入为一个或多个典型的 CNN feature maps,$f \in R^{C \times H \times W}$. 每个 channel 分别表示一个规则网格(一般为输入图像的 4x 或 16x 粗粒度). 输出为 K 个类别标签的预测结果 $p \in R^{K \times H^{'} \times W^{'}}$.
PointRend 模块主要包含三部分:
[1] - 点选择策略(point selection strategy) 用于从 real-value 点集中选择少量的点,以进行预测,避免对高分辨率输出网格的所有像素过度计算.
[2] - 对于每个选择的点,提取 point-wise 特征表示(point-wise feature representation). real-value 点集的特征是通过对 $f$ 采用其规则网格上的 4 个最近邻的点双线性插值进行计算的. 所以,其能够利用 $f$ 中通道维度所编码的 sub-pixel 信息,以预测比 $f$ 更高分辨率的分割结果.
[3] - point head,小的网络结构,用于训练从提取的 point-wise feature representation 中预测 label,每个点都是独立的.
对于实例分割,PointRend 应用于每个 region.
对于语义分割,PointRend 以 coarse-to-fine 的方式在选择的点上预测 mask. 这里,整张图像可以被看作实例分割的单个区域.
如图:
2.1. Point Selection
PointRend 的核心思想是,灵活且自适应地选择图像平面中的点,以预测分割标签. 直观地,这些选择的点应该更密集地分布在高频区域,比如物体边界,类似于光线追踪问题中的抗锯齿问题.
2.1.1. 推断阶段 - Inference
推断阶段的 Point Selection 策略受计算机图形学中 adaptive subdivision 技术的启发.
Adaptive subdivision 技术通过仅对具有较高可能与其临近点的值明显不同的位置进行计算,对于其余位置的值均采用对 coarse grids 插值得到,以有效的渲染高分辨率的图像.
The technique is used to efficiently render high resolutions images (e.g., via ray-tracing) by computing only at locations where there is a high chance that the value is significantly different from its neighbors; for all other locations the values are obtained by interpolating already computed output values (starting from a coarse grid)
PointRend 对于每个区域,以 coarse-to-fine 的方式迭代地渲染输出 mask.
最 coarsest 的预测是在分割网络输出的 coarse 规则网格上的点进行的.
每次迭代,PointRend 均采用双线性插值算法对前一次迭代预测的分割图进行上采样;然后选择 N 个最不确定的点(uncertain points),如二值 mask 中概率接近于 0.5 的点.
接着,PointRend 对 N 个点的每个点分别计算 point-wise 特征表示,并预测其标签.
重复以上过程,直到分割结果被上采样到期望的分辨率. 示例如图:

假设期望输出的分辨率为 $M \times M$ 像素,起始分辨率为 $M_0 \times M_0$,PointRend 需要对不超过 $N log_2 \frac{M}{M_0}$ 个点进行预测. 远小于 $M \times M$,因此 PointRend 可以更有效的得到高分辨率预测输出.
例如,假设 $M_0 = 7$,期望分辨率为 $M=224$,则需要进行 5 次 subdivision. 如果每次迭代选择 $N = 28^2$ 个点,PointRend 仅对 $28^2 \cdot 4.25$ 个点进行预测,其是比 $224^2$ 小了 15 倍的. 此外,整个过程中选择的点是小于 $N log_2 \frac{M}{M_0}$ 的,因为在第一个 subdivison 处理时,仅有 $14^2$ 个点.
2.1.2. 训练阶段 - Training
网络训练阶段,PointRend 的 Point Selection 策略可以采用类似于 Inference 阶段的策略的.
但是,由于 subdivision 的序列化处理,对于神经网络的 BP 训练是不够友好的. 因此,训练阶段,PointRend 采用了随机采样的非迭代(non-iterative)策略.
PointRend 在训练阶段的采样策略是,在训练的 feature map 上选择 N 个点,其期望是,能够偏向于选择不确定的区域,同时保持某种程度的均匀覆盖. 基于三个基本原则:
[1] - 过量生成(Over generation): 从均匀分布中随机采样 $kN(k>1)$ 个候选点;
[2] - 重要性采样(Importance sampling): 通过在所有 $kN$ 个点插值 coarse 预测,以及计算任务相关的不确定性估计,以重点关注于不确定的 coarse 预测的点. 从 $kN$ 个候选点中选择最不确定的 $\beta N(\beta \in [0, 1])$ 个点.
[3] - 收敛性(Coverage): 剩余的 $(1-\beta)N$ 个点是从均匀分布采样得到的.
示例如图:

PointRend 在训练阶段,预测输出和损失函数仅对 N 个采样的点进行计算的,其比 subdivision 的BP更加简单有效.
2.2. Point-wise Represnetation
PointRend 对于所选择的点,通过组合 fine-gained 和 coarse prediction 两个类型的特征,构建 point-wise features.
2.2.1. Fine-gained Features
PointRend 为了渲染更精细的分割细节,从 CNN feature maps 提取每个采样点的特征向量.
由于每个点是一个 real-value 2D 坐标,PointRend 对 feature map 进行双线性插值操作以计算特征向量. 特征可以从单个 feature map 提取(如,ResNet 中的 res2);也可以从多个 feature maps 提取(如,res2-res5,或其 feature pyramid),再链接组合.
Fine-graied 特征能够解析分割细节,但有两个局限:
[1] - 特征不包含 region-specific 信息,因此,两个实例边界框重叠处的点会具有相同的 fine-grained 特征. 但这些点仅可能是一个实例的前景. 因此,对于实例分割任务,不同区域对于相同的点就可能预测出不同的标签;因此需要额外的 region-specific 信息.
[2] - 由于依赖于 feature maps 来提取 fine-grained 特征,得到的特征可能仅包含相对 low-level 的信息. 此时,具有更多上下文信息和语义信息的特征源是有必要的. 其会影响实例分割和语义分割.
2.2.2. Coarse prediction Features
鉴于 Fine-gained 特征的局限性,PointRend 又提出了网络输出的 coarse 分割预测作为特征,如对于表示 K-class 预测的区域(region, box) 中的每个点,提取 K-dim 向量.
Coarse 分辨率提供了更多全局特征,同时通道(channels)覆盖了语义类别信息.
例如,实例分割任务中,coarse prediction 可以是 Mask R-CNN 的 mask head 网络的 7x7 分辨率输出. 语义分割任务中,coarse prediction 可以是 stride 16 的 feature map 的预测.
2.3. Point Head
给定每个选择的点的 point-wise feature representation,PointRend 采用一个简单的 MLP(multi-layer perceptron) 进行 point-wise 分割预测. MLP 对所有点(所有区域)共享权重,类似于 graph convolution 和 PointNet.
由于 MLP 对每个点预测分割标签,其可以采用标准的 task-specific 分割损失函数进行训练.
3. PointRend - 实例分割
COCO 和 Cityscapes 数据集.
网络结构: Mask-RCNN, basebone 网络为:ResNet-50 + FPN.
Mask-RCNN 默认的 mask head 网络为 region-wise FCN 网络,这里记为 4xconv (4 个 256 输出通道的 3x3 卷积层,其输入为 14x14 的 feature map. 2x2 kernel deconvolution 层输出 28x28. 最后一个 1x1 conv 层预测 mask.).
3.1. Coarse mask prediction head
为了计算 coarse prediction, 替换Mask RCNN 默认的 head 网络.
首先,对于每个边界框,PointRend 从 FPN 的 P2 层采用双线性插值提取得到 14x14 feature map. 其特征在边界框内部的规则网格上计算得到(这个操作可以看做为 RoIAligin 的简化版).
然后,PointRend 采用 stride-2,output-channels - 256 的 2x2 conv 层,后接 ReLU, 其将分辨率尺寸降低为 7x7.
最后,类似于 Mask RCNN 的 box head 网络,采用由两个 1024-wide 隐藏层组成的 MLP 来输出 K 个类别的 7x7 mask 预测结果. MLP隐藏层后接 ReLU层和 Sigmoid 激活函数.
3.2. PointRend
对于每个选择的点,采用双线性插值,从 coarse prediction head 的输出中提取 K-dim 特征向量.
PointRend 还从 FPN 的 P2 层插值得到 256-dim 特征向量. P2 层相对于输入图片是 4x 倍.
组合 coarse predicition 和 fine-grained 特征向量.
对于选择的点,采用 3 个 256 channel 的隐藏层组成的 MLP 进行 K-class 预测. 对于 MLP 的每一层,额外补充 K 个 coarse prediction features 的 256 channels 的输出,并作为下一层的输入向量. MLP内用 ReLU 层,输出接 Sigmoid 层.
3.3. Training
采用 Detectron2 中的标准 1x 训练方案和数据增强处理.
PointRend 采用 k=3 和 $\beta=0.75$ 的采样策略参数,采样得到 $14^2$ 个点.
PointRend 采用从 coarse prediction 中插值的 GT 类别的概率和 0.5 之间的距离作为 point-wise 不确定性度量.
对于 GT 类别为 c 的预测框,对第 c 个 MLP 关于 $14^2$ 个点的输出的二值交叉熵损失函数求和.
Coarse prediction head 采用类别 c 的预测mask 的平均交叉熵损失函数,与 Mask RCNN 的 4xconv 相同的损失函数.
将所有损失函数相加求和.
3.4. Inference
推断阶段,对于预测类别 c 的矩形框,除非特别说明,均采用 adaptive subdivision 来通过 5 steps 将 7x7 coarse 预测精细化到 224x224. 每一次迭代,选择并更新 $N = 28^2$ 个基于预测值和 0.5 之间的差异性距离得到最不确定的点
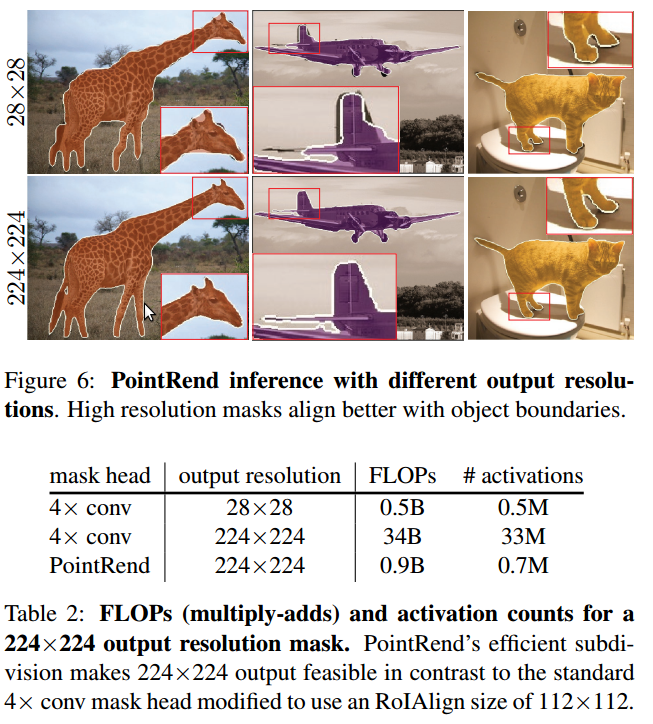
3.5. Reuslts


4. PointRend - 语义分割
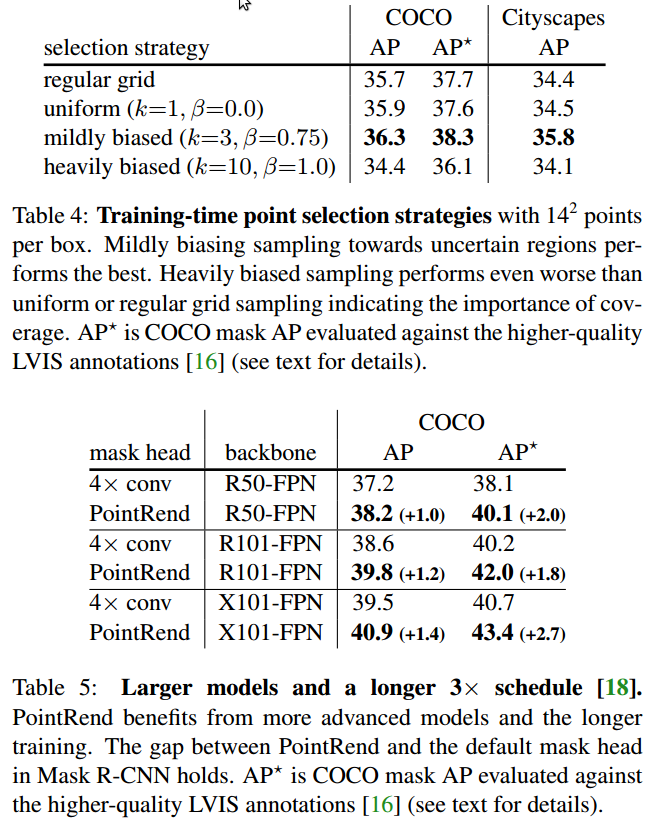
以 DeeplabV3 为例.