原文: Efficient method for running Fully Convolutional Networks (FCNs) - 2019.08.27
FCNs,全卷积神经网络,被普遍应用于很多计算视觉任务,如语义分割、超分辨率等. 其最大的优势之一在于,适用于任意尺寸的输入,如不同尺寸的图片. 然而,当在大尺寸的输入运行全卷积网络时,如高分辨率的图片或视频,需要的 GPU 显存消耗也是很大的. 这里介绍一种能够缓解该问题的简单方法,提出的算法能够将 GPU 占用降低到只有 3%-30%.
1. 全卷积神经网络
FCN 是仅包含卷积层的网络. 这里以图片为例,但其也适用于视频或其它类型的数据.
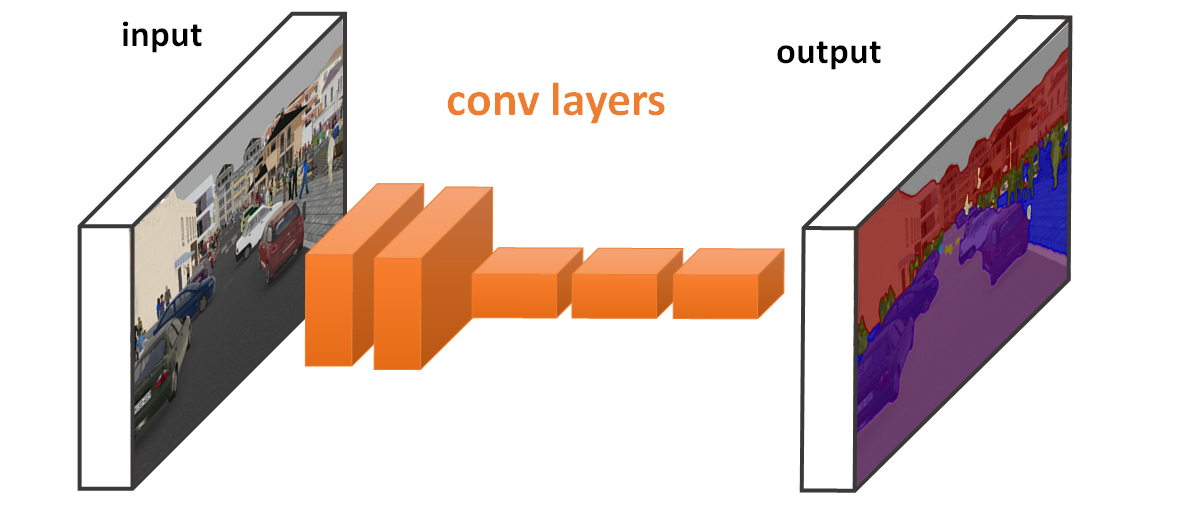
图1. 全卷积分割网络.
对于图像处理领域的许多任务,往往需要输入图像和输出图像保持相同尺寸,其可以通过带有适当补零(padding)操作的 FCNs 来实现(如,TensorFlow 的 same padding).
基于 FCNs 网络结构,输出图像的每个像素都是其输入图像中对应的图像块(patch) 的计算结果. 图像块(patch)的大小被称为网络的接受野(RF).
With this architecture, each pixel from the output image is a result of a calculation over a corresponding patch in the input image.
The size of this patch is called the receptive field (RF) of the network.
这里是一个关键点. 后面会介绍如何被使用到.
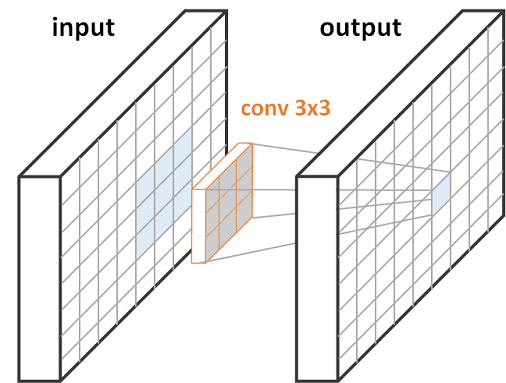
图2. FCN 的一个 3x3 卷积层. 每个输出像素对应于其输入图像的一个 3x3 patch.
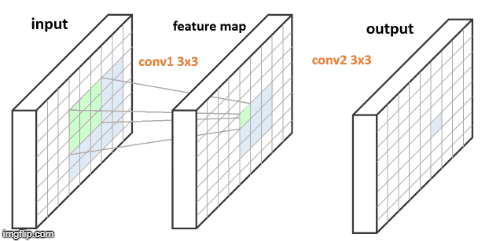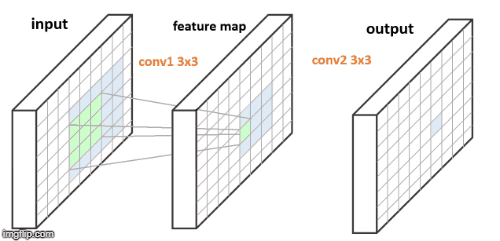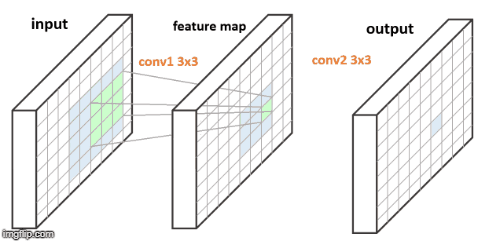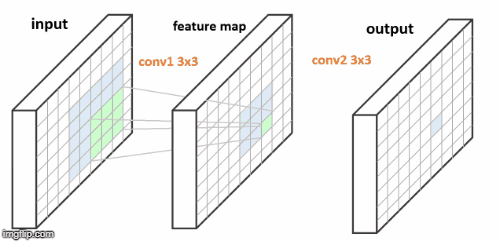
图3. FCN 的连续两个 3x3 卷积层. 每个输出像素对应于其输入图像的 5x5 patch.
以上两个 FCNs 的例示图中,图2中单个卷积层,右边蓝色的输出像素是由对应于左边蓝色输入 patch 的计算得到的. 图3中两个卷积层,在输入与输出之间存在 feature map,其每个绿色像素是由左边的输入 patch 计算得到,类似于图2;类似地,右边每个蓝色输出像素是由中间蓝色 3x3 feature map patch 的计算得到,其对应于左边蓝色的 5x5 输入 patch.
1.1. FCNs 问题
正如前文所提到的,理论上 FCNs 支持任意尺寸的输入. 但实际上,网络在前向计算过程中,需要将大量的 feature maps 保存在显存里,耗费大量 GPU 资源.
作者在进行视频和 3D 图像研究时就遇到了该限制, 在 NVIDIA V100 GPU 上甚至都不能运行网络. 这也是本文的起因.
2. FCNs 大尺寸输入的有效方式
传统 CNNs 网络的最后一层一般是全连接层. 因此,每个输出像素是对其全部输入的计算结果. 但 FCNs 不是这样的. 正如图2和图3所示,只有接受野大小的 patch 的输入会影响单个的输出. 因此,为了计算单个输出像素,并不需要将全部的 feature map 都保留在内存里.
换句话说,可以一次只计算输出值的一部分,只传递输入的必要像素. 这样可以大幅度降低 GPU 显存占用.
We can calculate small portions of the output values at a time, while passing only the necessary pixels from the input. This dramatically reduces the GPU’s memory usage!
2.1. 边界效应
例如:
假设输入是 28x28 的图片,由于内存限制,网络仅最大支持 12x12 的输入. 最直接的方法是,将原始输出分为多个 12x12 的输入块;然后采用 12x12 的输出块来重构 28x28 的输出图片.

图4. 每个输出像素是不同的输入块经过网络计算得到的结果. 例如,黄色像素是黄色 12x12 patch 输入的结果.
不过,这种方法并不能得到与整个 28x28 作为输入所一致的结果,其原因是 边界效应(boundary effects).
2.2. 边界效应的处理
为了理解边界效应,以下图红色像素为例. 红色周围的方形表示接受野,这里是 5x5 的,分别占据了蓝色和桔黄色的图像块. 为了准确的计算红色的输出像素,需要同时对蓝色和桔黄色像素进行计算. 因此,如果分别对蓝色和桔黄色图像块进行处理,则难以准确的计算红色像素值.
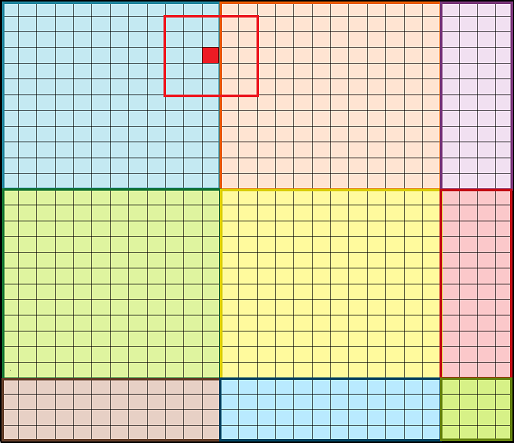
图 5. 红色像素-边界像素点及其周围的接受野.
如何更准确的计算红色像素值呢?可以滑窗重叠图像块,因此,每个 5x5 patch 都可以在网络输入的其中一个 12x12 patch 所计算在内. 重叠的数量应该比接受野尺寸小 1 像素(RF-1). 在示例中,接受野 RF=5,因此需要重叠 4 像素. 如下动图所示. 每个 12x12 输入图像块仅对输出中的少量像素其作用. 例如,蓝色方形黑框是比蓝色像素填充的面积更大的.
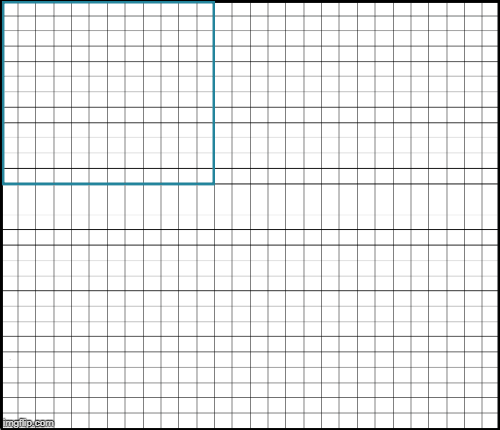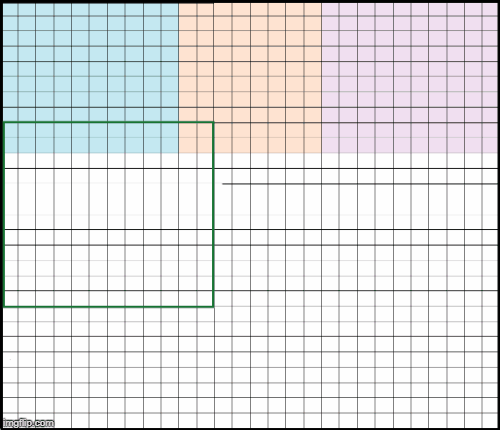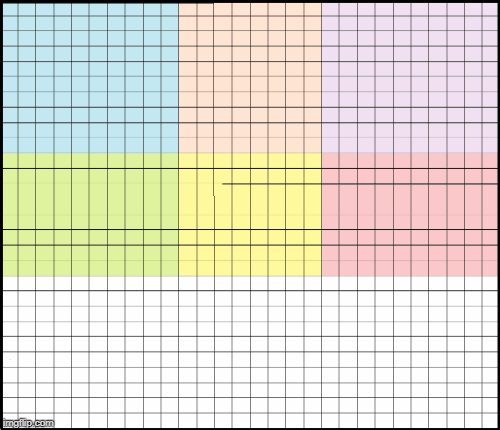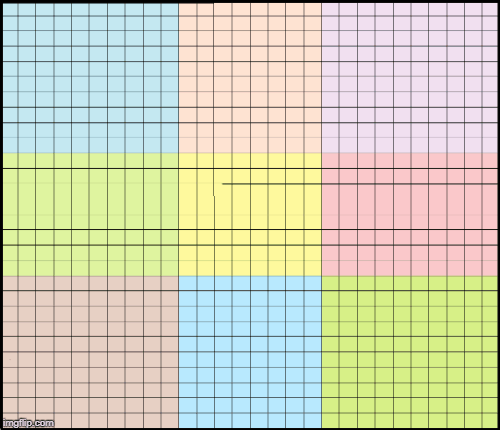
图6. 重叠输入块. 例如,桔黄色像素是桔黄色的 12x12 patch 的结果.
再回头看标记的红色像素. 如下图. 由于重叠的处理,可以精确的计算红色像素. 其周围 5x5 patch 被桔黄色 patch 所完全包含.
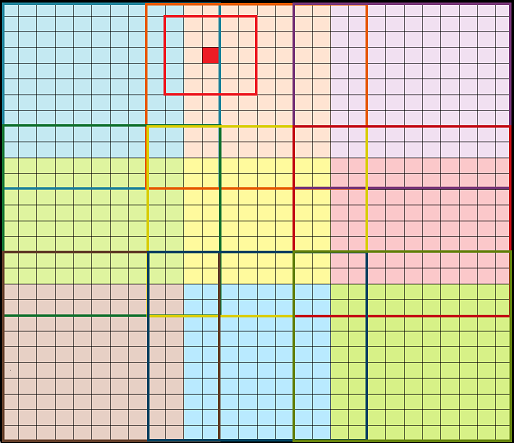
图7. 红色像素-边界像素及周围的接受野.
实际上,每个像素都有一个 12x12 patch 包含了其接受野尺寸的区域. 这种方式可以保证其结果与整个 28x28 图像作为输入得到的结果相一致.
In fact, each pixel has a 12x12 patch that contains its receptive field size surroundings.
This way we ensure equivalent results to running the entire 28x28 image together.
3. Results
下表给出了几个关于 GPU 显存占用和运行时间的结果. 可以看出,显存消耗大大减少.(实验基于NVIDIA Tesla K80 GPU.)

图 8. patch by patch 算法,相比于标准 direct 算法,GPU 显存占用减少了 67%-97%.
注:虽然图像前的处理运行时间比较慢,但采用该方法可以并行的处理多张图片,因此,仍节省了时间的. 例如第三行,采用本文方法可以同时运行 13 张图片,其时间消耗与 direct 方法仅能运行 6 张图片所消耗的时间相近.
2 条评论
这样也可以发论文?OωO
听说已经被申请专利了.