论文: Identity Mappings in Deep Residual Networks
作者: Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun
团队: Microsoft Research
对深度惨差网络理论分析.
[1] - 残差构建模块中,采用恒等映射(identity mapping)作为 skip connetions 和 after-addition activation时, forward 和 backward 可以从一个 block,直接传递到任何其他 blocks.
[2] - 阐述恒等映射的重要性.
1. 残差单元和跳跃链接 Skip Connections
深度惨差网络ResNets 是由许多堆积的残差单元 Residual Units 组成.
如 Fig (a). 每个残差单元可以表示为:
$$ \pmb{y}_l = h(\pmb{x_l}) + {F}(\pmb{x}_l, \pmb{W}_l) $$
$$ \pmb{x}_{l+1} = f(\pmb{y}_l) $$
其中,$\pmb{x}_l$ 和 $\pmb{x}_{l+1}$ 为第 $l$ 个残差单元的输入和输出,${F}$ 为残差函数(如,堆积的两个 $3 × 3$ 的卷积层).
$h(\pmb{x}_l) = \pmb{x}_l$ 为恒等映射.
$f$ 为 ReLU 函数,element-wise相加后的操作.
${W}_l = \{W_{l,k} | 1 \leq k \leq K \}$ 为第 $l$ 个残差单元的权重集. $K$ 是残差单元的层数($K=2 或 K=3$).
ResNets 的关键是,拟合关于 $h(\pmb{x}_l)$ 的残差函数 ${F}$ (${F} = \pmb{y} - h(\pmb{x})$)时,最佳选择是 $h(\pmb{x}) = \pmb{x}$. 即:通过单位跳跃链接(identity skip connection,shortcut)来实现.
本文所分析的是,创建信息传递的直接路径的深度残差网络,不仅仅是一个残差单元,还包括整个网络.
得出的结论是,如果 $h(\pmb{x})$ 和 $f(\pmb{y}_l)$ 都是恒等映射(identity mappings),信号在前向和后向传递时都可以从一个神经元和其它任何神经元直接传递.
对于跳跃链接的作用的理解,这里对多种类型的 $h(\pmb{x}_l)$ 分析对比发现,Deep Residual Learning for Image Recognition 中的恒等映射 $h(\pmb{x}_l) = \pmb{x}_l$ 能够取得最快的误差减少速度和最低的训练 loss. 保持"干净"的信息传递,有助于网络优化.
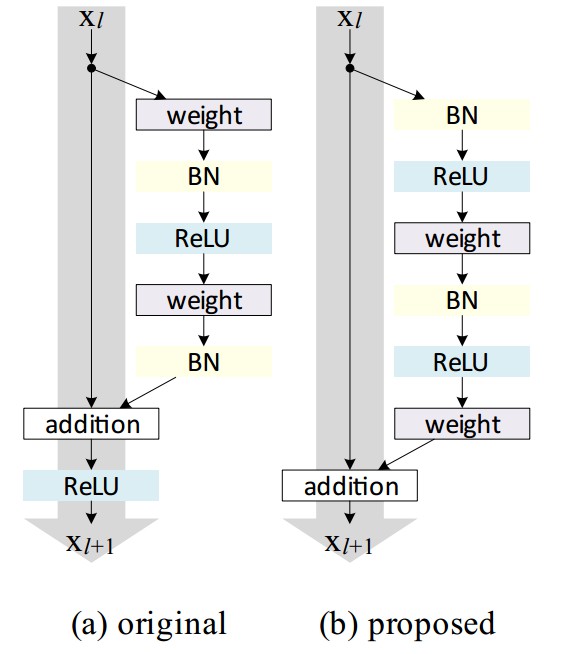
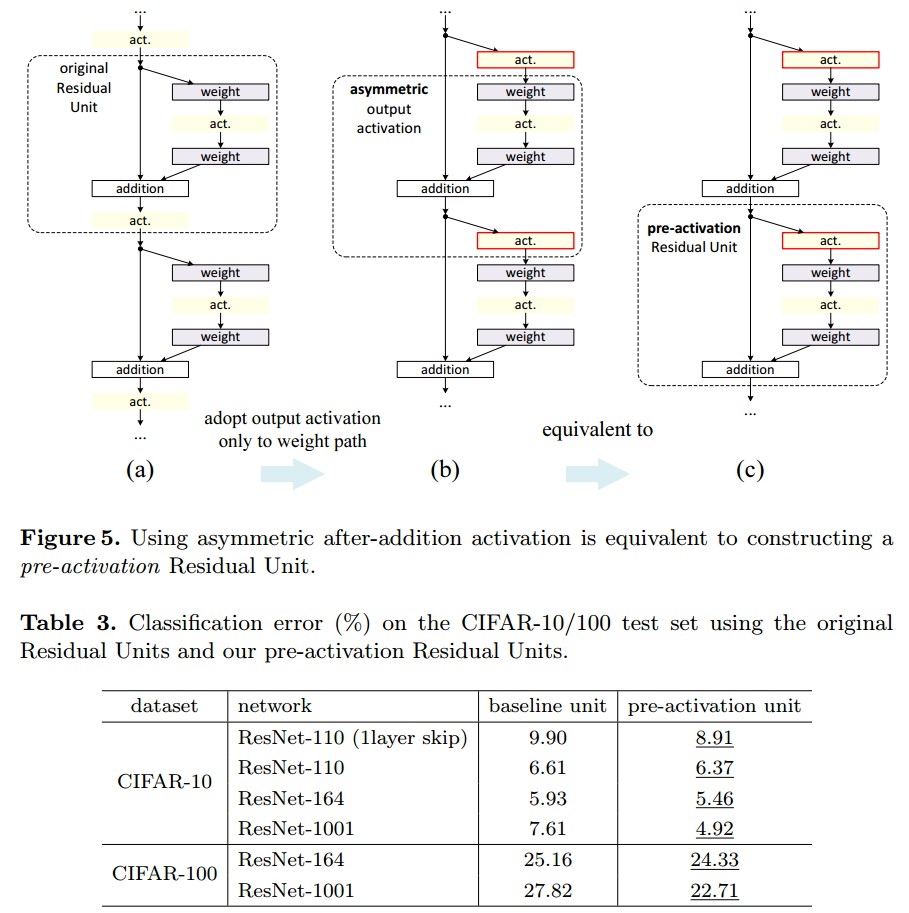
构建恒等映射 $f(\pmb{y}_l) = \pmb{y}_l$ 时,记权重层的激活函数(如,ReLU 和 BN) 为 pre-activation,记权重层的卷积层为 post-activation.如 Fig (b). 图中,灰色箭头表示信息传递的最简单路径. 基于此,构建了更容易训练和泛化的 ResNet-101 .
在公式 (2) 中,如果 $f$ 也是恒等映射:$\pmb{x}_{l+1} \equiv \pmb{y}_l$,则可以得到:
$$ \pmb{x}_{l+1} = \pmb{x}_l + {F}(\pmb{x}_l, {W}_l) $$
类似地,依次有:
$$ \pmb{x}_{l+2} = \pmb{x}_{l+1} + {F}(\pmb{x}_{l+1}, {W}_{l+1}) $$
$$ \pmb{x}_{l+2} = \pmb{x}_{l} + {F}(\pmb{x}_{l}, {W}_{l}) + {F}(\pmb{x}_{l+1}, {W}_{l+1}) $$
$$ \pmb{x}_{L} = \pmb{x}_l + \sum_{i=l}^{L-1} {F}(\pmb{x}_i, {W}_i) $$
公式表现的特点:
[1] - 任何深层(deeper)神经元 $L$ 的特征 $\pmb{x}_L$ 都可以表示为任何浅层(shallower)神经元 $l$ 的特征 $\pmb{x}_l$ 与残差函数 $\sum_{i=1}^{L-1} {F}$ 相加之和. 即:模型是任何神经元 $L$ 和 $l$ 间的残差形式.
[2] - 任何深层神经元 $ L$ 特征 $\pmb{x}_{L} = \pmb{x}_0 + \sum_{i=0}^{L-1} {F}(\pmb{x}_i, {W}_i$,是所有残差函数的输出与 $\pmb{x}_0$ 的相加和. 对比于 “plain network”,特征 $\pmb{x}_{L}$ 是一序列矩阵向量的乘积,即:$\pmb{x}_{L} = \prod_{i=0}^{L-1} W_i \pmb{x}_0$ (忽略 BN 和 ReLU 层.)
公式 (6) 的反向传播,记 loss 函数为 $\varepsilon$,则:
$$ \frac{\partial \varepsilon}{\partial \pmb{x}_l} = \frac{\partial \varepsilon}{\partial \pmb{x}_L} \frac{\partial \pmb{x}_L}{\partial \pmb{x}_l} = \frac{\partial \varepsilon}{\partial \pmb{x}_L} (1 + \frac{\partial}{\partial \pmb{x}_l} \sum_{i=l}^{L-1} {F}(\pmb{x}_i, {W}_i) ) $$
梯度计算可以分为两部分:
[1] - $\frac{\partial \varepsilon}{\partial \pmb{x}_L} $ 项不需要关心任何权重层,直接传递信息. 直接把深层的梯度传递到任意浅层.
[2] - $ \frac{\partial \varepsilon}{\partial \pmb{x}_L} ( \frac{\partial}{\partial \pmb{x}_l} \sum_{i=l}^{L-1} {F})$ 项在权重层传递信息. $\frac{\partial \varepsilon}{\partial \pmb{x}_L} $确保信息能够直接传递回任何浅层单元 $l$.
损失函数公式还表明,mini-batch 的梯度 $\frac{\partial \varepsilon}{\partial \pmb{x}_l} $ 不可能消失为 0,因为 $ \frac{\partial}{\partial \pmb{x}_l} \sum_{i=l}^{L-1} {F} $ 项对所有样本,很难一直为 -1. 也就是说,即使权重任意小,网络也不会出现梯度消失.
公式(6)包含两个恒等映射:
- 恒等跳跃链接 $h(\pmb{x}_l) = \pmb{x}_l$;
- 恒等映射 $f$.
2. 恒等跳跃链接的重要性
这里简单修改,记 $h(\pmb{x}_l) = \lambda_l \pmb{x}_l$,则恒等 shortcut为:
$$ \pmb{x}_{l+1} = \lambda_{l} \pmb{x}_l + {F}(\pmb{x}_l, {W}_l) $$
其中,$\lambda_l$ 为标量因子.
类似于公式 (6),有:
$$ \pmb{x}_{L} =(\prod_{i=1}^{L-1} \lambda_{i}) \pmb{x}_l + \sum_{i=l}^{L-1} (\prod_{j=i+1}^{L-1} \lambda_{j}) {F}(\pmb{x}_i, {W}_i) $$
$$ \pmb{x}_{L} =(\prod_{i=1}^{L-1} \lambda_{i}) \pmb{x}_l + \sum_{i=l}^{L-1} \hat{ {F}} (\pmb{x}_i, {W}_i) $$
其中,$\hat{{F}}$ 为带标量缩放因子的残差函数.
类似地,其梯度计算:
$$ \frac{\partial \varepsilon}{\partial \pmb{x}_l} = \frac{\partial \varepsilon}{\partial \pmb{x}_L} ((\prod_{i=1}^{L-1} \lambda_{i}) + \frac{\partial}{\partial \pmb{x}_l} \sum_{i=l}^{L-1} \hat{{F}} (\pmb{x}_i, {W}_i) ) $$
可以看出,如果 $\lambda > 1$,容易出现指数爆炸;如果 $\lambda < 1$ 则容易出现弥散或消失,原本的shortcut就会被堵塞,经过更多权重层的反向传播,难以优化.
3. Experiments
3.1 Skip Connections
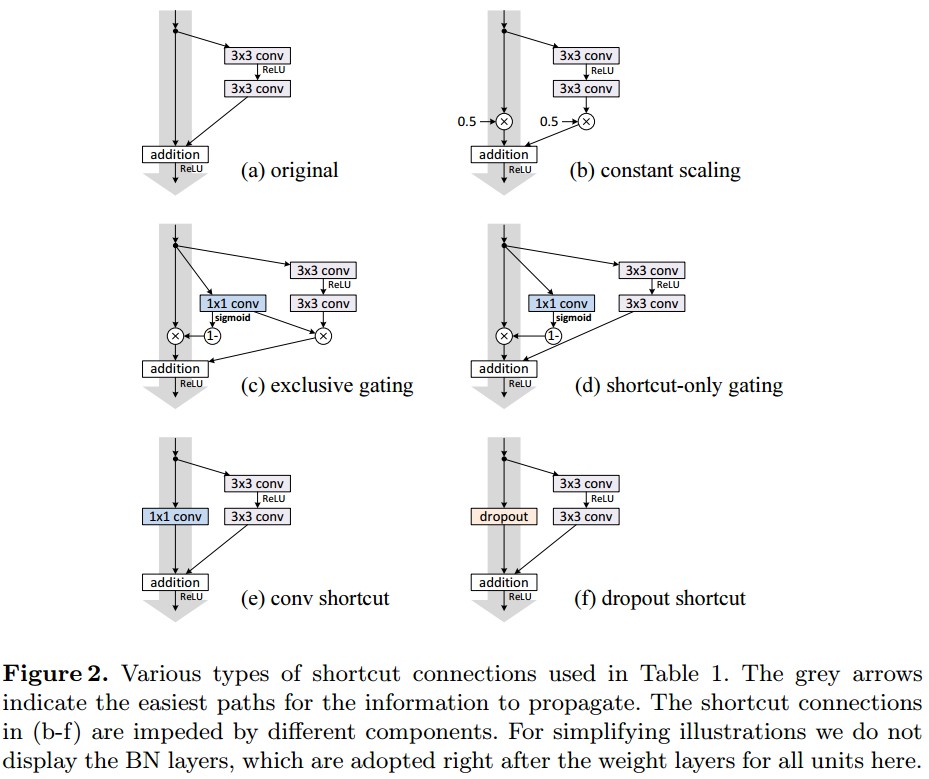
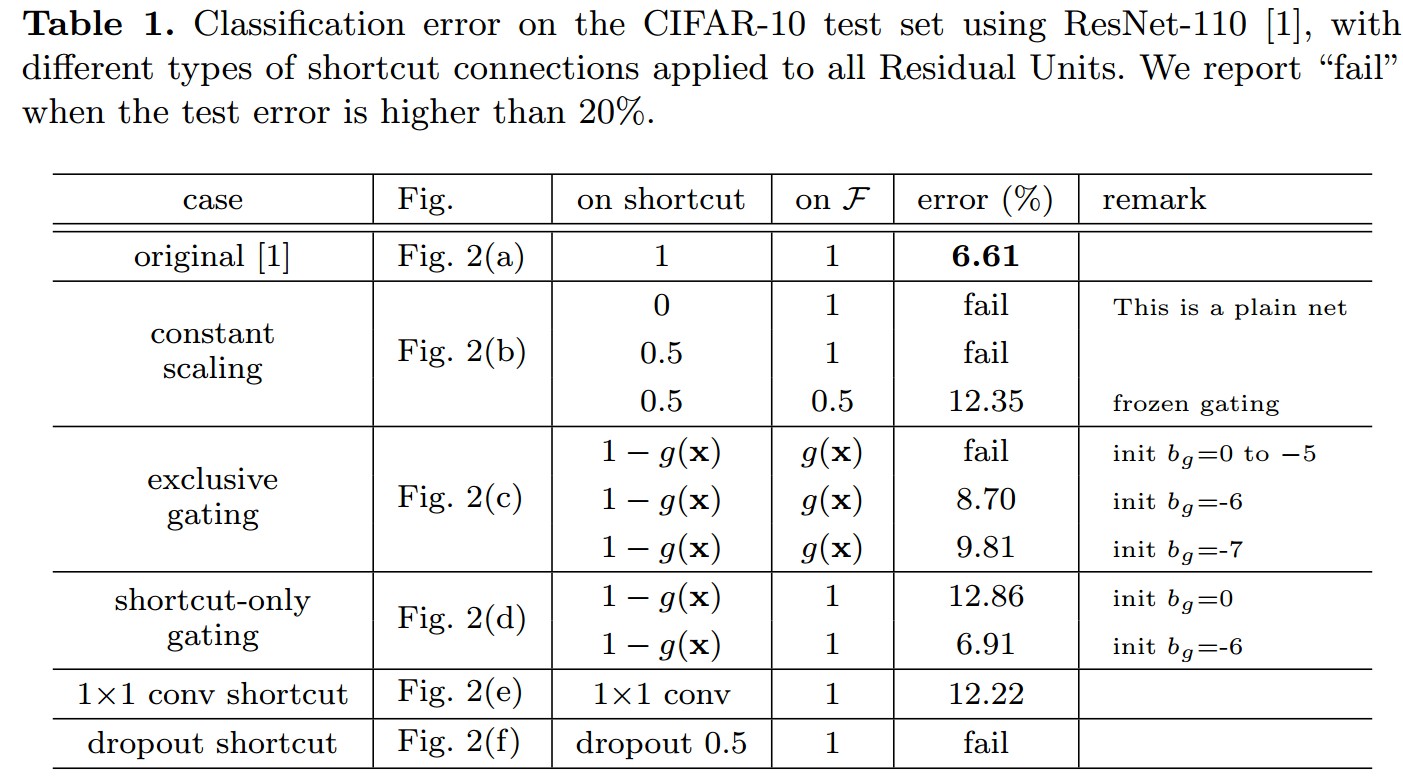
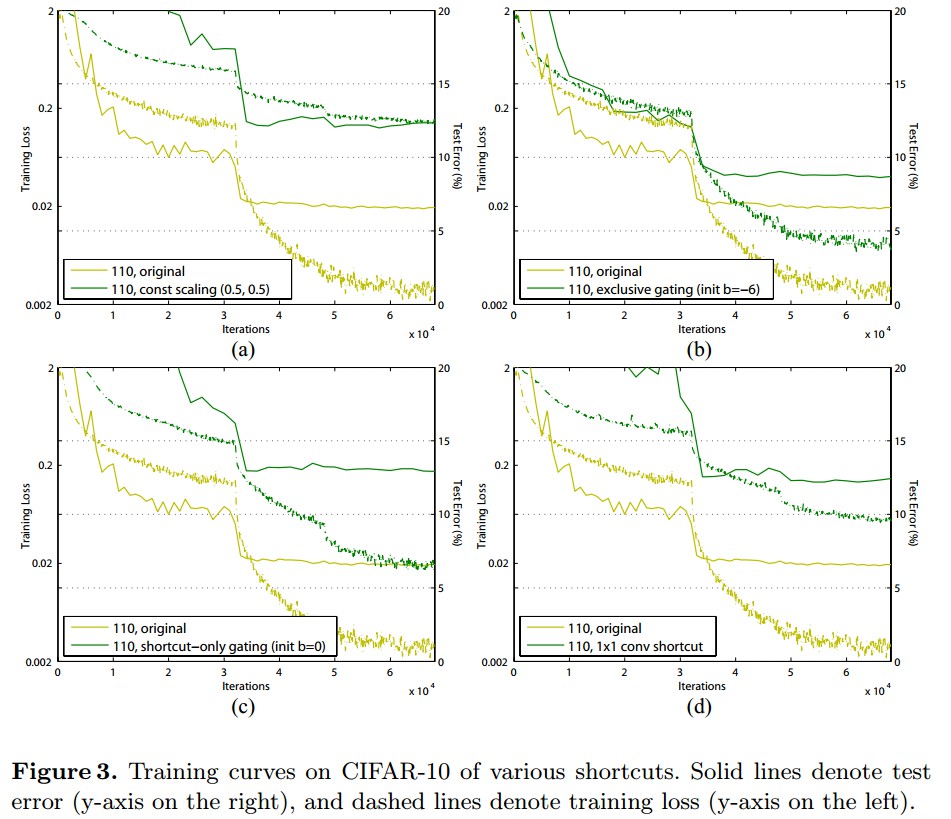
3.2 Activation Functions

Related
[1] - 论文阅读学习 - ResNet - Deep Residual Learning for Image Recognition