原文:每天审核淘宝性感图的工程师,竟然还做了这个 - 2019.09.11
出处:淘系技术 - 微信公众号
作者:胡佳洁(佳婕) 、黄锦池(尘漠),曲烈(汤问)
出品:阿里巴巴新零售淘系技术部
论文:O2U-Net: A Simple Noisy Label Detection Approach for Deep Neural Networks - ICCV2019
导读:获取高置信标注的大规模数据集是有监督学习算法的一个难点问题,训练集中的噪声标签会严重降低模型的精度. 通过所提出的噪声标签自动识别算法,无需人工干涉就可获取高质量的干净数据集,可以充分发挥海量弱标签数据的潜力,并提升模型的精度.
本文相关工作收录于 ICCV2019(IEEE International Conference on Computer Vision,CV 领域三大顶会之首),详细介绍了淘系技术部算法团队提出的一种简单、高效的噪声标签识别算法,只需调节训练时的学习率,就可以让 90% 的噪声标签原形毕露.
1. 背景
训练数据的规模及其标注质量对有监督学习算法的性能影响重大. 互联网上虽然有海量的可爬取的数据,但这些按照标签语义收集来的数据往往带有大量噪声. 因此,要在这些弱标签数据上训练出高性能的深度神经网络模型,研究人员往往面临着从噪声中提取足够多有用信息的挑战. 本文将介绍一种简单高效的噪声标签自动识别算法 ,只需设置学习率的变更策略就能识别出 90% 的噪声样本,进一步提高训练模型的精度和收敛速度.
通常基于 human-supervision 的标签净化方法中,为保障训练数据的质量往往需要投入高昂的成本. 著名的图像数据集 ImageNet 有 120 万带标数据,标注过程中李飞飞实施多轮多人带验证题的复杂标注策略,才确保了数据集的质量.
但在实际业务中我们不可能投入如此巨大的成本,外包标注的数据往往是单次打标,许多因素会导致我们拿到的训练集存在不同程度的噪声,例如下图是外包对性感图任务打标结果的截图,对类似的图片标注结果完全相反,用这批带噪数据进行训练得到的模型精度无法达到上线要求. 因此,对高质量数据的需求与低效率的人工标注,构成了广大算法攻城狮们在模型开发的初级阶段所要解决的主要矛盾.

针对噪声问题,一味地调整模型和算法治标不治本. 我们在淘宝内容库类目分类识别的业务问题中发现,如果训练数据的精度不到 80% ,那么训练出来的模型精度是 72% 左右,无论模型怎么调整,精度只有 2%~3% 的提高,无法达到上线要求,因此还是需要从数据源头上解决问题. 依赖 human supervision 的方式净化数据集需要耗费大量的时间,让多个外包统一打标的边界也需要付出很大的沟通成本.
为提高业务效率,我们沉淀出一套简单高效易移植的噪声样本识别算法,自动找出可能是噪声的样本,并通过剔除可疑噪声数据在干净训练集上训练以提高模型精度. 在解决业务问题中,噪声样本识别算法给我们带来了以下两方面显著的好处:
[1] - 提高标注效率. 通过算法找出最可疑的样本,只需要对筛选出来的最可疑的样本进行二次审核,减少标注人员的工作量,也能大幅提高迭代速率.
[2] - 提高模型精度. 如果我们的噪声样本识别精度足够高,甚至识别精度达到95%以上,我们甚至不需要对可疑的噪声样本做人工复审,直接剔除掉训练模型以提高精度.
接下来,我们将详细介绍噪声样本标签识别算法,相关工作已被计算机视觉领域的顶会ICCV2019接收《O2U-Net: A Simple Noisy Label Detection Approach for Deep Neural Networks》.
2. 解决思路
我们调研了在噪声样本识别、抗噪模型等领域的前沿技术. 以下是针对 state-of-the-art paper 的调研分析.
[1] - 《Understanding Black-box Predictions via Influence Functions》
论文主要利用 influence function 识别出噪声样本. 算法计算每个训练样本对验证集 loss 变化影响,如果某个训练样本对于验证数据集的精度起到负影响,那么就可能是不好的样本,这些样本可能包含了比较多的噪声样本. 论文的创新点在于提出了计算每个训练样本对当前模型性能的影响大小的方法,即 influence function . 对于影响为负值的训练样本,且该绝对值很大时,那么该样本就不是好的样本.
[2] - 《CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images》
文章采用课程学习的思想:人类学习知识的过程是从简单到难,读书教学,我们的学习过程都是从简单的课程到复杂的课程. 分成四个阶段训练:
[a] - 初始学习,把所有的训练样本仍进去,得到初始网络模型 first_model ;
[b] - 根据初始网络模型,来判断每个训练样本学习的难易程度,把训练数据分成:容易学习样本集 A 、难学习样本集 B . 判断难易程度的方法,就是 paper 的创新点,主要思路是采用模型抽取出来的特征向量来聚类,来判断每个样本是否是离群,以此判断学习的难易程度.
[c] - 课程学习:把容易学习的样本集 A ,在 first_model 模型的基础上继续训练得到第二阶段的模型 second_model.
[d] - 把 A+B 混合在一起,在 second_model 的基础上继续训练,得到最终的模型.
之所以把 B 样本重新混到所有的样本里面重新训练,主要是因为B样本不全是噪声样本,干净的样本占了比例比较大,如果强行扔掉 B 数据集,那么对模型精度会比 first_model 得到的精度还低,主要原因是因为被误杀的干净样本,往往是很重要的,这些样本对于模型精度的提升有很大的贡献.
[3] - 《MentorNet: Regularizing Very Deep Neural Networks on Corrupted Labels》
文章提出了一种在数据维(data dimension)中正则化深度 CNN 的全新技术,文中称之为数据正则化(data regularization). 目标是通过正则化在有损标签上训练的 CNN 来提升其在清洁测试数据上的泛化表现. 具体来说,提出用于训练该分类网络(即 StudentNet)的每个样本学习随时间变化的权重,并引入了 MentorNet 来监督该 StudentNet 的训练. ,MentorNet 学习为每个训练样本分配一个权重. 通过学习不均衡的权重,MentorNet 鼓励某些样本学得更早,并且得到更多注意,由此对学习工作进行优先级排列. 对于 MentorNet 训练,文章首先预训练一个 MentorNet 来近似得到有标签数据中特定的一些预定义权重. 然后在具有清洁标签的第三个数据集上对它进行微调. 在测试的时候,StudentNet 独自进行预测,不使用 MentorNet.
3. 算法设计
3.1. 算法思路及测评指标
以上方法通过判断样本的难易程度,设计不同学习阶段进行网络训练. 受此启发,我们在ICCV2019的论文《O2U-Net: A Simple Noisy Label Detection Approach for Deep Neural Networks》中提出了噪声样本识别的算法.
我们知道,在一次训练中,随着迭代轮次增加,网络逐渐从欠拟合逐渐过渡到过拟合状态,在训练的初期,模型精度的提升是非常明显的,因为网络很快学会了那部分“简单的“样本,因此这类样本的 loss 比较小,与之相反,那些“困难的”样本通常在训练的后期才逐渐被学会.
有论文指出如果训练的轮次足够多,巨大参数量使得模型能记住几乎所有的样本,因此过拟合训练数据中的噪声常常会让模型的表现变差.
观察训练过程发现,噪声样本通常是在训练的后期才被学会,因而在训练的早期,噪声样本的平均 loss 是远大于干净样本的,而在训练的后期,因为网络逐渐学会了所有样本,两类样本的loss区别不大. 纵观整个训练过程,从欠拟合到过拟合,噪声样本loss的均值和方差都比干净样本要大.
实验发现,只统计一次训练过程中不同样本的 loss 分布得到的结论不够可信,易造成对正常难样本的误杀,为了提高算法的鲁棒性,我们通过循环学习率策略,使网络在欠拟合和过拟合之间多次切换,并追踪不同阶段不同训练参数的模型对样本的 loss ,通过在时间维度上捕获多样性足够丰富的模型(类似集成学习,对满足多样性和准确性的多个模型进行 ensemble ),统计各个样本 loss 的均值和方差,均值和方差越大,样本属于噪声样本的概率也就越大. 大量实验表明,加入这个 trick 后,此算法在噪声样本识别和抗噪学习方面均取得了 outperform 当前其他算法的性能. 该算法可分为三个阶段:
[1] - stage1: 训练得到收敛的模型. 超参数选择时,学习率设为固定值即可,训练可能会达到过拟合状态.
[2] - stage2: 循环学习率阶段. 学习率周期性衰减,学习率突然增大,使得网络跳出过拟合状态,欠拟合时噪声样本产生的 loss 较大,而干净样本易于学习,loss 值偏小,随着训练进行学习率减小,网络慢慢进入过拟合阶段,能正确拟合噪声样本和干净样本,此时两类样本带来的 loss 都比较小. 通过不连续周期循环学习率来训练模型,模型在过拟合和欠拟合之间反复切换,在这个过程中,噪声样本 loss 的均值和方差均比干净样本高,通过多轮切换,可以基于 loss 筛选出数据中的疑似噪声样本. 下图展示了我们的实验过程中,当学习率周期震荡时,噪声样本(绿色曲线)的loss也会出现周期性震荡,而干净样本(黄色曲线)的 loss 总是比较小,在论文《O2U-Net: A Simple Noisy Label Detection Approach for Deep Neural Networks》中有更详尽的实验结果分析.
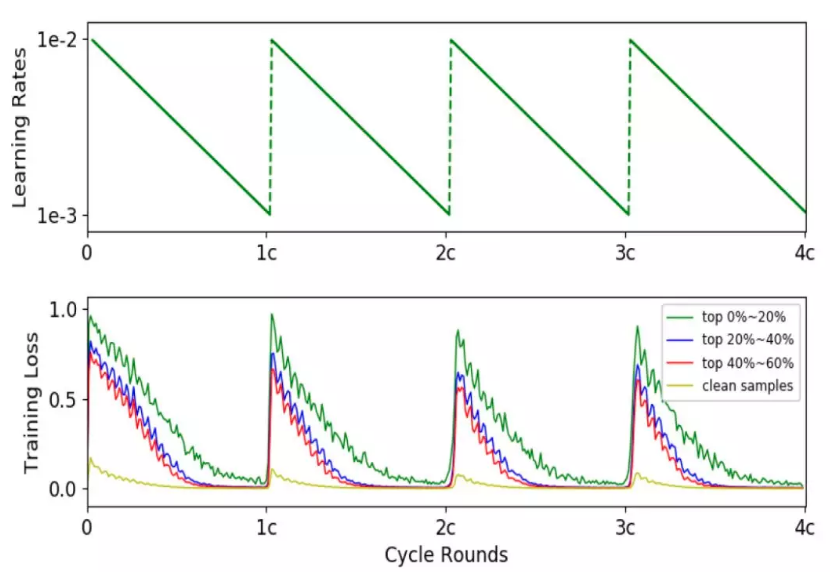
[3] - stage3: 在干净数据集训练. 剔除算法识别出的疑似噪声样本后,在干净数据集上重新训练模型.
我们使用以下两个指标评价算法的质量:
噪声识别精度指标
(1)PR 曲线:主要是通过对噪声样本,根据不同的阈值,可视化绘制 PR 曲线:精确度与召回率曲线
(2)根据固定的阈值,评估精确度:如果训练数据集噪声比例为 10% ,那么就召回 10% 最有可能为标错的样本,然后统计召回精度(精确度)
- 抗噪模型精度指标
把可疑的噪声样本剔除,对模型进行重新训练,在干净的测试集上,计算模型精度提高的百分点.
3.2. 算法性能
基于上文构造的噪声样本数据集,对比了所提算法和几种 state-of-the-art 算法的性能. 下表展示了不同抗噪模型精度指标:
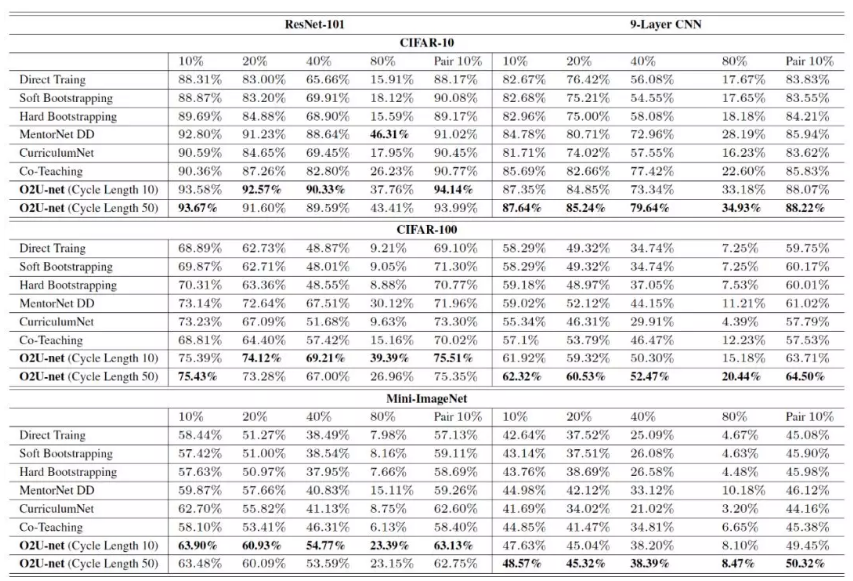
在基于 resnet101 和浅层的 9 层 CNN 模型中,我们所提算法的抗噪性能在不同数据集和不同的噪声比例上,都较以往的方法有了较大提升.
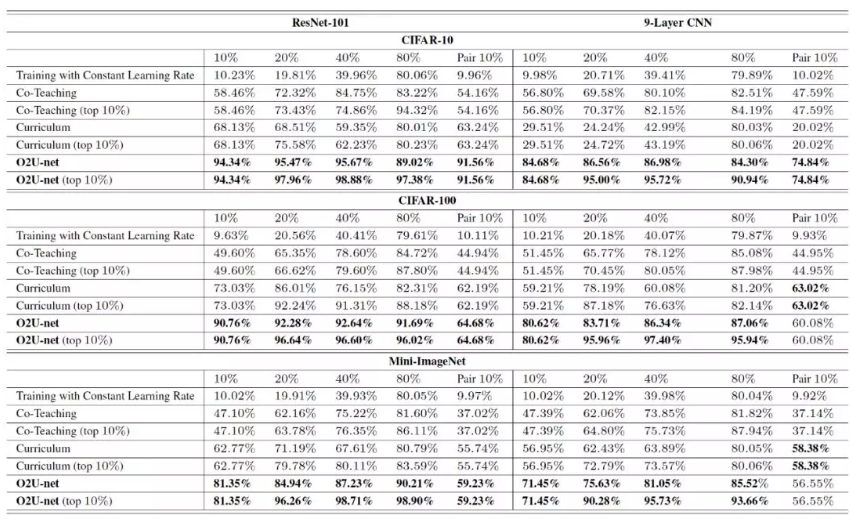
下表是几种不同算法对样本集中噪声标签的识别精度,在不同数据集和不同的噪声比例上,我们的方法都能更准确地识别出噪声,我们把这归功于,算法集成了同一网络结构在各种不同训练阶段、大量不同参数的情况下,对样本对 loss 的分布进行统计,因此能准确识别出疑似噪声样本. 并且算法不需要集成多个模型,仅仅是通过调整学习率来控制某一个模型的进入不同状态,因此在算法实现起来比较容易,针对各种模型的可迁移性也很强.
算法同学在解决业务问题时,总希望能获得高质量的训练样本,而从业务场景中拿到的数据大多需要重新进行标注,有时由于标注规则不清晰,即使是外包同学标注的数据往往也存在误标现象.
在训练流程之前,先使用噪声标签识别算法将疑似噪声样本挑选出来,直接剔除这些样本或对其进行二次打标,可以快速训练样本的质量. 例如,我们在解决图片里多主体的任务时,拿到的原始数据集噪声比例约为 15% ,通过算法我们找出了 5k 个单主体的样本集中,为噪声样本概率最大的 30 个样本. 从召回的噪声样本中可以看出, top30 全部都是多主体的样本,在 top 100 的噪声样本中,我们算法识别的精度约为 93% .
当正负样本的距离很接近时,例如在对商品图进行肢体检测时,对包含肢体的数据集进行噪声样本检测,在 top30 的疑似噪声样本中,也包含了一个正确的样本,这也是后续优化需要解决的问题.


4. 应用场景
人工标注带来的样本噪声问题不可避免,清洗样本获得干净的数据集,是许多算法同学需要解决的问题,自己多轮打标剔除噪声样本需要掌握分类规则,也需要耗费大量时间精力. 而我们提出的噪声样本自动识别算法,大大节约了我们的进行样本筛选的成本,有效帮助我们在解决在各种业务问题时提高效率. 除此之外,在验收外包同学的标注数据时,也可以通过噪声样本识别算法来判断标注精度是否达到一定标准.
噪声样本识别能力和相似样本召回能力,有力地帮助我们解决了许多图像质量相关的业务问题,并在业务过程中积累了大量的干净样本. 目前我们已具备的质量能力主要包含:牛皮癣、软色情、模糊图、白底图、纯色背景图、优质图识别、真实场景图、多主体、拼接图、是否包含肢体、插画素材图等多个维度的检测判断,也实现了数据和算法相互优化. 牛皮癣、软色情、清晰度、白底图、纯色背景图、多主体识别等,均已上线用于淘宝内容库封面图审核过滤,过滤精度均超过 90% .
5. 参考文献
1 - Classification in the Presence of Label Noise: A Survey
2 - Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy labels
3 - Mentor-Net: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels
4 - Understanding Black-box Predictions via Influence Functions
5 - Making Deep Neural Networks Robust to Label Noise: A Loss Correction Approach
6 - Learning from Massive Noisy Labeled Data for Image Classification
7 - A Closer Look at Memorization in Deep Networks
8 - Training Deep Neuralnetwork Using a Noise Adaptation Layer
9 - CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images
10 - CleanNet: Transfer Learning for Scalable Image Classifier Training With Label Noise