原文 - What is wrong with Convolutional neural networks ?
CNN 的两个弊端
自从Alex Krizhevsky 等论文 ImageNet Classification with Deep Convolutional Networks 在 NIPS2012 发表开始,CNN 已经成为很多领域十分重要的工具,深度学习已很普遍. 基于 CNN 的方法已经在计算机视觉的诸多任务中取得了卓越的成绩. 但,CNN 是完美的吗?是能选择的最佳方案吗?当然不是.
2014年12月4日, Geoffrey Hinton 在 MIT 进行了关于他的胶囊网络(Capsule Networks) 的演讲. 期间,他对 CNN 存在的问题进行了讨论,包括对 pooling 层糟糕表现的原因. 实际上,pooling 层表现是可以用灾难性来形容的.
if you are familiar with CNN’s you can skip to what's wrong?
这里对 CNN 的两个弊端分析说明.
1. 卷积层
卷积层通过一组矩阵与前一层网络神经元的输出矩阵相乘,即卷积计算,来得到某些特征. 如基本特征(如 边缘edge, 颜色color grade, 或模式pattern);或者复杂特征(如形状shape, 鼻子nose, 或嘴mouse)等等,这组矩阵称为过滤器(filters)或核(kernel).
1.1 卷积 Convolution
数学上,以图像为例,2D 数据的离散卷积,${ f }$ 和一个 2D kernel ${ g }$ ,有:
${ (f * g)(x, y) = \sum_{v=y-h}^{y+h} \sum_{u=x-w}^{x+w} f(u, v) g(x-u, y-v) }$
其中,${ 2w+1 }$ 为 kernel 的宽(width),${ 2h+1 }$ 为 kernel 的高(height).
以 kernel 3×3 和 stride 1 为例,如图:
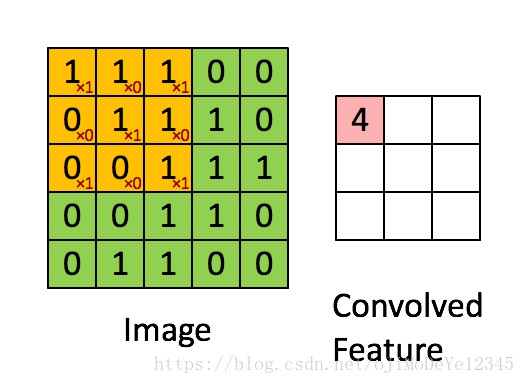
1.2 参数减少 Reduced Parameters
卷积层,每一个输出值(Convolved Feature)是不需要与前一层的每个神经单元(Image)相连的. 相连的区域称为接受野(receptive fields),即卷积 kernel 当前的操作. 卷积层的这种特点称为局部连接(Local Connectivity) ,可以有效的减少参数量.
卷积 kernel 的当前权重是固定的,且卷积中权重相同,直到下次参数更新,权重值才会发生变化. 卷积层的这种特点成为 参数共享(Parameter Sharing),其也有利于减少参数量.
如果想要应用更多的权重集,只需增加 kernels 数量即可.
1.3 平移不变 Shift Invariant
由于 卷积层的参数共享及 pooling 层的局部效应,可以发现 CNNs 的另一个重要特征是,平移不变(Shift Invariant).
平移不变意味着,输入的平移发生平移,输出也发生平移,但结果不变. 具体来讲,如果训练时在某些位置的特征是有用的,那么在测试时,这些特征在所有位置的检测结果都应是可用的. 如:

如果检测器(或 filter) 学习到 CAT 的特征,那么在测试时,不管 CAT 在图像的任何位置,检测器都能够捕捉到 CAT.
2. Pooling 层
池化(Pooling) 层有很多类型,如 Max Pooling,Avg Pooling 等. Max Pooling 是最常用的.
Max Pooling 能够给出一定的平移不变性,足够应对某些任务. 而且,能够以很小的代价减少网络维度(不需要新的参数学习). 即,减少了传递到下一层特征提取的输入数量.
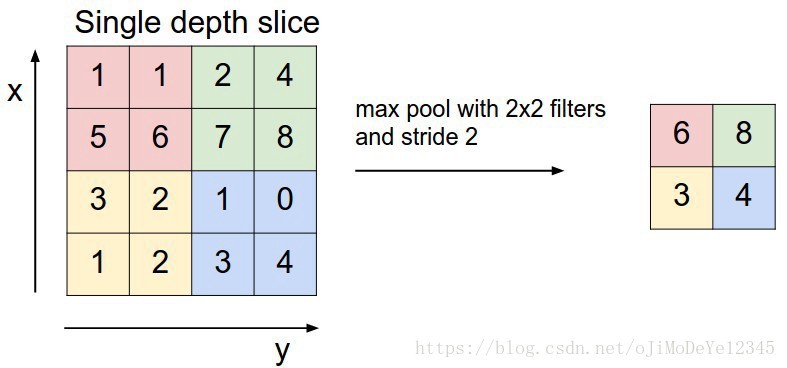
Max Pooling 层是很简单的,只需预定义一个 filter (一个窗口window) ,并在输入上滑动该窗口,取窗口内区域的最大值,即可得到输出.
如,filter 为 $2×2$ 的 Max Pooling:
3. 弊端所在
3.1 卷积层弊端
- 反向传播 Backpropagation, BP
反向传播算法是一种寻找在处理完一批数据后每个权重对 error 的贡献的方法.
很多好的优化算法(如SGD,ADAM等) 利用 BP 算法来计算梯度.
虽然,BP 已经取得了很好的效果,但其不是一种十分高效的学习方法,因为BP 算法需要大规模数据集的支持. - 平移不变性 Translation invariance
当提到平移不变时,往往意味着,同一 object 发生轻微朝向或位置变化时,可能并不会激活那些识别该 object 的神经元.
正如 1.3 中的图示,如果假设只有一个神经元来识别 cats,那么其值会随着 cat 的朝向和位置的变化而发生改变. 虽然数据增广能够部分解决该问题,但仍不能彻底根除.
3.2 Pooling 层弊端
Pooling 层会丢失大量的有价值信息,以及忽略局部与整体之间的关联性.
例如,如果描述一个面部检测,需要结合某些特征,如嘴巴mouth,2只眼睛eyes,脸轮廓face oval 和鼻子 nose,才能说其是人脸. 但只要这 5 种特征出现,CNN 就很可能会判断为是人脸. 如:

这两张图片的 CNN 输出可能很相似,但却是很不好的.
经过多个 pooling 层之后,将丢失 object 的准确位置信息. 对于某些识别任务,如需要 high-level 局部的精确位置信息,是影响很大的.
3. 总结
CNN 是很好很有效果的,但其仍有 2 个非常糟糕的弊端——平移不变(translation invariance) 和 pooling 层. 幸运的是,可以通过数据增广等方法来避免风险. 有些即将来临的技术,如胶囊网络,需要做好准备,并接受改变.