原文:时尚电商新赛道—FashionAI 技术揭秘 - 2019.06.17
出处:淘宝技术 - 微信公众号
作者:贾梦雷(雷音) - 阿里巴巴研究员、淘系技术部 FashionAI 负责人
1. 从推荐技术说起
1.1. 用户行为
从推荐技术说起. 首先是基于用户行为的推荐,包括使用用户的点击行为、浏览行为、购买行为.
推荐技术提升了用户找商品的效率,也带来了公司收益的增长. 当推荐的效率提高到一定程度的时候,会出现瓶颈,比如说你买了一件上衣还给你推上衣,这是近些年被诟病得很厉害的地方. 如果只是基于用户行为的话就会朝着这个方向发展.
1.2. 用户画像
第二个我们提到用户画像.
经常有人说对用户有洞察,可以做精准的画像. 我始终怀疑这件事情. 比如说买衣服,你拿的可能都是用户的行为数据,浏览啊点击啊购买啊;可是如果你能知道用户肤色的色号,以及他的身高、体重、三围,你说这个用户画像比前一个能精准多少呢?所以说所谓的用户洞察、用户画像,今天来看其实还是非常粗糙的.
1.3. 知识图谱
第三个我们还可以做知识图谱,来帮助做关联推荐的,比如说你买鱼竿,我给你推荐其他的渔具,你买了车灯给你推其他的汽车配件. 但是到今天为止效果还不够好,还有很多困难.
以上是推荐技术通常考虑的事.
那么我们在服饰推荐领域看一下,还有什么其他的可能. 一个服装的线下店,我们对一个导购员核心考量的指标是什么?是关联购买:如果顾客买了一件衣服这个是不计入你导购员的贡献的,通过你让用户买了另外一件这个是计入你的绩效. 所以重要的是关联购买,关联购买里面的重要逻辑是搭配. 可以看出当我们把推荐做到具体一个领域的时候,我们可以有了专属于这个领域的一些推荐逻辑,这就是在日常里面在发生的逻辑.
2. 为什么要做行业知识重建
我们看看怎么才能做搭配. 大部分普通用户都还搭不好,因为穿搭需要相当多的知识和经验. 我们要想做搭配,衣服的属性、或者说是设计元素,是抓手,它的准确率和丰富性一定要足够,如果不足够做不出可靠的搭配来.
我们做技术的都听说过的有知识图谱,它典型情况就是通过人的经验或用户数据去把很多的知识点关联起来. 知识图谱里的知识点的生成更多是通过常识的方式,比如说我是一个人,我的朋友是谁,我上级是谁. “我”这个知识点是通过常识产生的.
还有一类方法叫专家系统,比如说我们也有很多红人,把他理解成专家,他所沉淀下的专业经验,每个领域都会有一些专家,比如医疗系统里就是医生,专家系统大概是在知识图谱兴起之前人工智能普遍采用的方式.
这两类方法再往下还有一层东西是知识点,更基础的东西,如果知识点本身有问题的话,在这上面构建出来的知识关系都会有问题. 那在这个基础上去做AI算法,效果就不够好,这可能是人工智能难以落地的原因之一. 要有勇气去重新构建这个知识点体系.
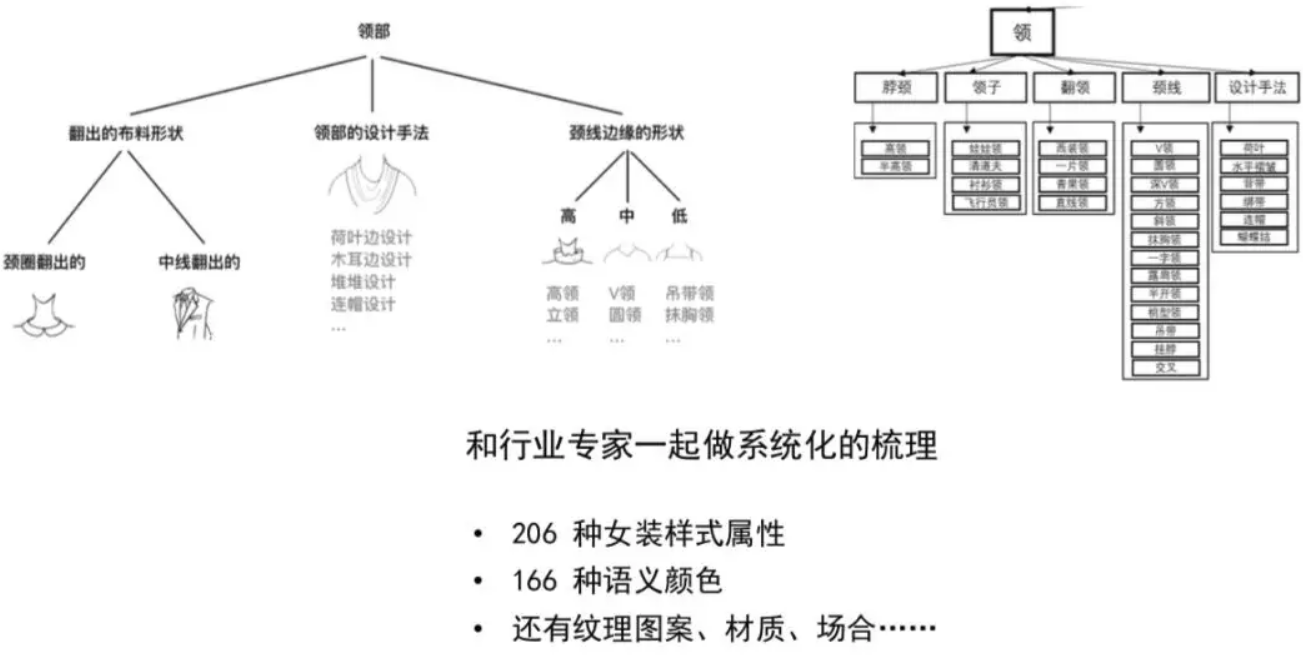
给大家看一下淘宝一个例子. 这个图的上半部分是我们运营或者设计师的知识体系,这是个“领型”的例子,有各种的圆领、斜领、海军领,可以看出结构是平铺的、散乱的. 之前的知识是人和人之间传播的. 尤其是在比较小的圈子里,比如设计师群体,知识可以非常含混,我只要能沟通就行. 再比如医生写那个草书,医生之间可以看的懂,但是病人看了都说看不懂. 其实我们很多知识是用于人和人沟通,有大量的二义性、不完备性. 比如说服装风格,一个标签叫做“职场风”,另一个叫“中性风”. 职场风跟中性风从视觉上你分不开,如果人都难以区分,你要说机器识别准确率可以超过80%,那肯定哪里出错了.

还有一类,打标签的人本身理解可能就有问题. 举个极端的例子,淘宝的商家给衣服打标签,曾经有一段时间,有一半的女装上都被商家打上了韩版的标签,它根本不是韩版,韩版卖得好就说这是韩版的,这是说商家打的标签不足以相信,有必要通过图像直接得出判断.
3. 面向机器学习的知识重建
前几年我们找了淘宝、天猫的服饰运营,综合了几版的运营知识做了规整,不过还是不够好. 去年我们做 FashionAI 大赛,和港理工的服装系合作,后来和北京服装学院、浙理工都在合作. 其实直接由服饰专家们给出的知识体系是不行的,因为我们需要的是一个面向机器学习的知识体系,机器是要分0和1的,完备性、二义性问题、视觉不可分等这几个我们总结出来的原则,这些都要尽量满足.
我们把曾经散落的知识,按照划分逻辑去组织,比如说领部,我们会根据它布料怎么去分、设计手法怎么去分、颈线边缘怎么去分,来从几个维度总结散落的知识点. 之前是一盘散沙,最终会看到一个树形的样子. 我们把常用的女装属性整理出来,一共有206种,这还不包括“流行的设计手法”这样开放性的、不断扩充变化的属性. 这个“整理”比大家想象的复杂得多,花了3到4年时间,除了考虑知识本身,还要进一步考察知识点所对应的数据收集难度、必要性. 比如说女装的西装领还可以再细分9种,已经接近视觉不可分,这时候我要停留在女装西装领这个粒度就够了,就不再做细分.
有时很难事先判断一个属性是否能学出好的模型来,这时属性的定义还要做多轮的迭代. 我发现我的属性定义有问题,我倒回去重新定义,然后再重新收集数据、训练模型,直到模型可以达到要求. 做完知识重建,我们曾经的十几个属性识别的效果,准确率普遍提高了20%,这个提升是非常大的.
我们现在有206种女装样式,有166种语义颜色,还有材质、场景、温度等知识体系. 怎么定义这个颜色,比如说在时尚行业里,黄色几乎是没有意义的,讲“柠檬黄”是有意义的,去年女装就流行柠檬黄. 我们知道RGB颜色(256, 256, 256),在潘通色表里跟服饰相关的一共有2310种颜色,但这个色表里都是色号,消费者没法理解,我们在上面再建了一层560种有语义对应的颜色,这是跟北京服装学院一起定的,用来做按颜色给衣服聚类又显得过细,就又再建一个166种的,就是大家看到类似于“柠檬黄”、“芥末绿”这种语义颜色,到这个阶段消费者才能理解.
还有很多的技术细节,比如说怎么处理光照问题、色差问题等等,也有很多的难的地方,在这里我会主要讲面向机器学习的知识重建.
4. AI使知识重建的大工程变可行
接下来问题就来了,我有206种女装样式,收集数据训练模型的话,我怎么才能做得完呢,更何况还可能一个定义要多轮迭代修正?
比如图中这叫风铃袖,一个合格的数据集大概需要3000到4000张图片. 收集足够多的、高质量的图片是一个很大的挑战,在2016年为了做一个3000到4000张图片的高质量数据集,大概需要标注超过十万张图片,当时的标注留存率只有1.5%. 当时的方法就类似学术界做的,先用一个词去搜回很多图,然后找人标注. 更可能是始终找不到足够多的图片旁边写着风铃袖,它都没有标注你是搜不到的. 所以知识重建确实是一个巨大的挑战. 以前根本没有人有勇气去做,因为你根本做不了.
当年2016年我们完成一项属性识别是要200天,这个时间包括了定义迭代花的时间. 2017年我们用40天,2018年我们用2.5天,到现在,我们大概用15个小时,那到2019年底,我们计划是缩减到0.5天. 这是一个巨大的改变,我们提出“少样本学习”大概是在三年前,当时学术界还没很多人提这个问题,但是我们已经看到了,因为我们痛苦的就是这个,不得不开始上手解决它了.
学术界提到”few-short learing”、小数据学习,更多是偏重如何从少量样本直接得到一个好的模型,我们选的路不大一样,我们是从旁边绕路,今天这个场合,我还不能讲得很细,但是这个路我们已经走通了.

大家看这个,一个叫蝴蝶结领,一个是飞行员领,这是我们女装属性集里的东西. 我们今天把常用的96种女装属性已经完成了,就是利用我们的少样本学习工具SECT(Small、Enough、Comprehensive),从“少”到“足够多”到“足够好”,最重要的,SECT它不是只在我们在FashionAI业务里发生了作用,它可以做泛内容识别,讲得严谨一点,在“简单内容分类”这类任务上表现得不错.
在泛内容识别上,我们利用SECT系统已经完成70多个标签识别,例如:“插画、阳台、上脚”等标签,我们已经开始改变业务人员和算法人员的工作模式,大家知道在深度学习出来之前,那时候我们业务人员都不大敢提让算法人员给出个识别模型,因为开发周期太长了,为了去识别一个东西我要找算法人员跟他商量,然后算法人员手工去设计特征. 为了做一个能够上线的、工业界能用的一个模型,最少花上半年、一年的时间,这是以前的模式. 2013年深度学习开始流行之后,这个问题发生了转化. 算法人员会说今天有了深度学习,业务人员你收集足够多图片就行了,我给你设计个好模型出来. 如果这个模型不好的话,那是你收集的数据质量不行. 这时候运营想去收集5000张图片,发现还是成本很高.
我们今天还很难用SECT去解决机器视觉中的“检测”问题,或者说检测任务在我们的理解里不是一个“少样本”的问题,在检测任务下应该叫做“弱监督”问题,弱监督跟少样本也有所不同.

5. 对未来的展望
我理解大数据应该分两种,一种是说,你的商业洞察也好,模式分析也好,只有在大规模的数据上才能完成,这是真的大数据,还有一种是说今天的机器学习能力不行,必须有那么多的数据才能出来一个模型,这个叫做伪大数据,因为随着AI的能力越来越强,需要的样本肯定越来越少.
以前有公司标榜自己有特别多的数据,比如说人脸数据或什么的,把数据看成了资产. 这个说法一定会慢慢落下去,因为AI能力越来越强,我们需要的数据量越来越少. SECT再演变下去,会到什么程度,可能中层的跟浅层的算法人员不再需要了,业务人员直接上去提供十几张图、不会超过50张图,交给系统,然后很快模型返回来,你测一下看好用不,不行再迭代学习,直到模型好用. 它已经不是以前的,标注阶段、训练阶段、测试阶段,间隔得那么远. 今天整个迭代越来越快,如果说迭代可以减少到小时级、分钟级的话,这实际上已经变成了一个人机交互的学习系统,这是未来会带来巨大改变的东西.
淘宝内容平台的运营人员说,过去两个月产出了比之前三年还多的模型. 我们自己组的算法同学自己也用来解决属性识别之外的各类问题,比如说我来硅谷之前,组里同学想识别照片里的人是正身还是背身的,是站姿还是坐姿,是一个深色人种还是一个黄皮肤等等,我们需要很快时间里出6个判别模型. 今天我们可以一两周内让模型上线,准确率、召回率、泛化能力全都能达到要求. 以前我们想做这个事情没有一年半载是不可能的.
业界里有很多人总结深度学习的局限,比如需要大数据、缺乏可解释性,我觉得在未来几年,我们对于什么叫“样本”、什么叫“可解释性”,会有一个新的理解. 我们去年在朱松纯老师主编的《视觉探索》上发了一篇文章,叫《如何做一个实用的图像数据集》,今年我们有计划写个续篇,就是《如何做一个实用的图像数据集(二)》,会重点聊一聊我们在少样本学习上的体会和展望,大家也可以持续关注.