原文:Understanding Tokenization in NLP - 2023.07.05
Tokenization 是将一连串的文字( a stream of text)分解为单词(workds)、短语(phrases)、符号(symbols) 、其他有意义的元素(meaningful elements)等被称为 tokens 的处理.
这些 tokens 能够被数值编码,并作为模型的输入.

将文本转换为 tokens,有很多不同的 Tokenization 方式:
- Character Tokenization
- Word Tokenization
- Subword Tokenization
- Entire Dataset Tokenization
Character Tokenization
最简单的方式是,将文本划分为独立的字母character tokens,然后再送入模型.
例如,
raw_text = "We love NLP!"
tokens = list(raw_text)
print(tokens)
#['W', 'e', ' ', 'l', 'o', 'v', 'e', ' ', 'N', 'L', 'P', '!']然后,模型需要将每个 token 转换为整数(integer).
# Numerical encoding of individual character
token2idx = {char: idx for idx, char in enumerate(sorted(set(tokens)))}
print(token2idx)
#{' ': 0, '!': 1, 'L': 2, 'N': 3, 'P': 4, 'W': 5, 'e': 6, 'l': 7, 'o': 8, 'v': 9}
# Using token2idx to map our tokenized text to integers
integer_tokens = [token2idx[token] for token in tokens]
print(integer_tokens)
#[5, 6, 0, 7, 8, 9, 6, 0, 3, 2, 4, 1]至此,每个 token 被映射为一个独立的整数. 接着,对每一个整数进行 one-hot encode.
# One-hot encoding the numbers
import torch
import torch.nn.functional as F
integer_tokens = torch.tensor(integer_tokens)
one_hot_encode_tokens = F.one_hot(integer_tokens, num_classes=len(token2idx))
print(f"Token = {tokens[0]}")
print(f"Integer Encoded Token = {integer_tokens[0]}")
print(f"One hot encoded Token = {one_hot_encode_tokens[0]}")
#Token = W
#Integer Encoded Token = 5
#One hot encoded Token = tensor([0, 0, 0, 0, 0, 1, 0, 0, 0, 0])尽管,character tokenization 被证明在处理拼写错误和罕见单词时,是一种有效的方法. 但,因为其只是一串字符,缺乏语义和一些语言中单词的结构信息.
Word Tokenization
正如其名,将文本划分为独立的单词 tokens,并将其映射为整数.
由于模型不需要对 characters 进行学习的开销,因此,其降低了学习复杂度.
Word Tokenization 最直接和简单的方式是,根据 whitespaces 将文本划分.
# Splitting raw text based on whitespaces
word_tokens = raw_text.split()
print(word_tokens)
#['We', 'love', 'NLP!']但,这种方式的问题在于没有考虑标点符号(punctuation),如 "NLP!" 被当做了一个 token.
如果还考虑词形变化(conjugations)、词尾变化(declination)、拼写错误(misspellings),并为每个词分配唯一的 token,那么,词汇量的大小可能会增长到百万级.
这就会导致一个问题,神经网络需要学习大量的参数.
一种处理方式是,丢弃罕见单词,并使用最常见的 100000 个单词,所有剩余的单词都被归类为未知单词,并共享一个共同的标记 UNK.
Subword Tokenization
鉴于 character 和 word tokenization 的优点和缺点,subword tokenization 尝试二者的结合.
Subword Tokenization 主要做了两件事:
- 将罕见单词划分为更小单元,以处理拼写错误和复杂单词
- 常用单词被保留,并分配一个唯一 token
以 WordPiece 为例,Google 提出的一种 subword tokenization 算法,用于预训练的 BERT.
HuggingFace 提供了一个 AutoTokenizer 类,以便于使用与预训练模型关联的 tokenizer.
# install the HuggingFace library
!pip install transformers
from transformers import AutoTokenizer
model_ckpt = 'distilbert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
from transformers import DistilBertTokenizer
distilbert_tokenizer = DistilBertTokenizer.from_pretrained(model_ckpt)
# Lets see the tokenizer in action now
encoded_text = tokenizer(raw_text)
print(encoded_text)
#{'input_ids': [101, 2057, 2293, 17953, 2361, 999, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1]}
tokens = tokenizer.convert_ids_to_tokens(encoded_text.input_ids)
print(tokens)
#['[CLS]', 'we', 'love', 'nl', '##p', '!', '[SEP]']可以看出,
- 特殊 tokens [CLS] 和 [SEP] 标记了文本序列的起始和结束.
- 每个 token 是小写.
- 感叹号 ! 被作为一个独立 token
- NLP 被分为了两个 token, 因为其不是一个常用单词.
p 前的 ##表示了前面的字符串不是空格,以##开头的token必须与之前的token合并.
Tokenising entire Dataset
以 tweet emotion dataset 为例,其包含 2000 个 (tweet, label) pairs 对.
# install datasets library
!pip install datasets
from datasets import load_dataset
tweet_emotions = load_dataset("emotion")
print(tweet_emotions)
#________________________________________
# DatasetDict({
# train: Dataset({
# features: ['text', 'label'],
# num_rows: 16000
# })
# validation: Dataset({
# features: ['text', 'label'],
# num_rows: 2000
# })
# test: Dataset({
# features: ['text', 'label'],
# num_rows: 2000
# })
#})定义 tokenization 函数,并查看两个样本:
# function for tokenization
def tokenize(batch):
return tokenizer(batch["text"], padding=True, truncation=True)
print(tokenize(tweet_emotions["train"][:2]))
#{'input_ids': [[101, 1045, 2134, 2102, 2514, 26608, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1045, 2064, 2175, 2013, 3110, 2061, 20625, 2000, 2061, 9636, 17772, 2074, 2013, 2108, 2105, 2619, 2040, 14977, 1998, 2003, 8300, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}这里,tokenization 有两个重要的参数作为输入:
- padding - 补零操作,以匹配当前 batch 内最大长度的样本的长度.
- truncation - 截断样本,以匹配模型的最大输入长度.
此外,除了编码后的 tweets,tokenizer 还返回了 attention_mask.
- attention_mask - 有助于模型忽略输入中 pad 的部分,只从实际的内容中进行学习.
图示更清晰:
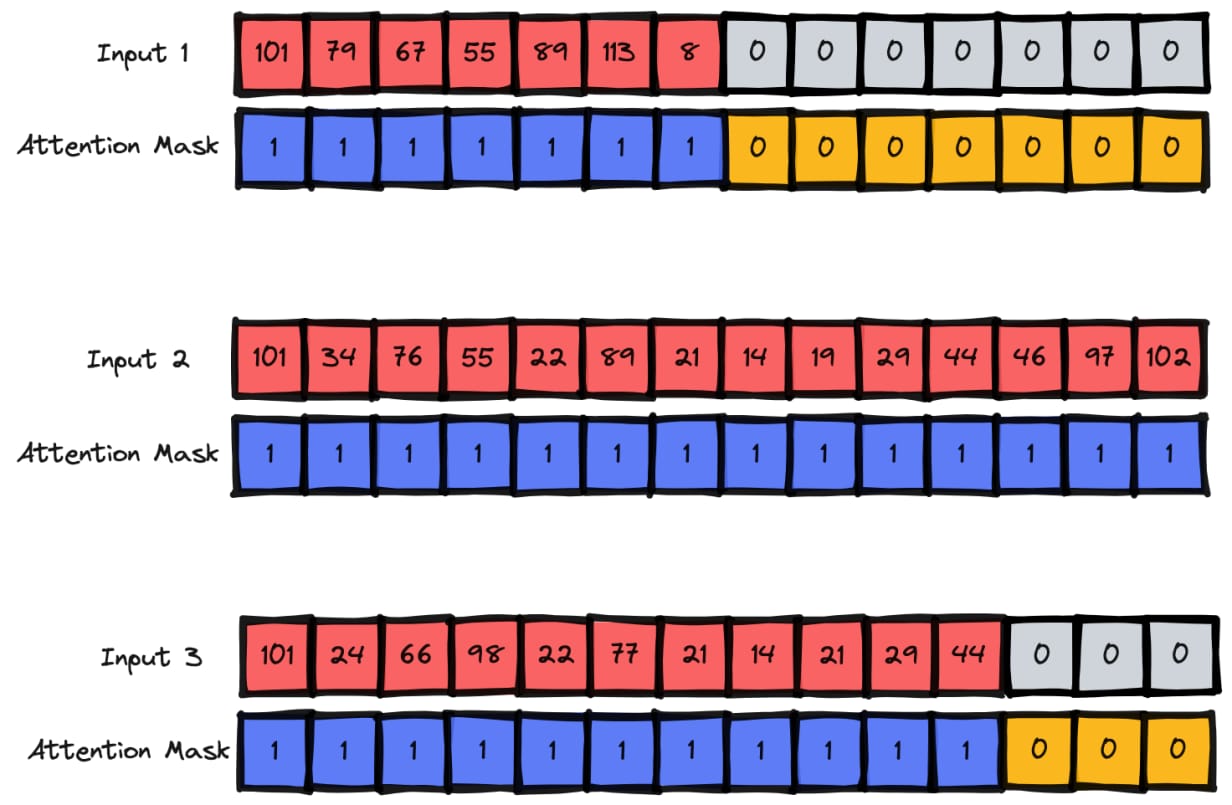
Tokenising entire Dataset ,如:
# Applying tokenization across entire data set
tweet_emotions_encoded = emotions.map(tokenize, batched=True, batch_size=None)
print(tweet_emotions_encoded['test'].column_names)
#['text', 'label', 'input_ids', 'attention_mask']