题目: Fast R-CNN - Fast Regin-based Convolutional Network for Objection Detection - ICCV2015
作者: Ross Girshick
团队: Microsoft Research目标检测的经典论文之一.
Fast R-CNN slides
Code-Caffe
Code-Detectron
1. R-CNN
R-CNN 采用深度网络来对 object proposals 分类以进行目标检测,其缺点如下:
[1] - 训练是 multi-stage 的.
a). R-CNN 首先采用 log loss 对 object proposals 微调 ConvNet;
b). 然后将 ConvNet 特征送入 SVMs 分类器. 将 SVMs 作为目标检测器,取代微调的 softmax 分类器;
c). 学习 bounding-box 回归器.
[2] - 训练的空间和时间代价较高.
训练 SVM 和 bounding-box 回归器时,需要对每张图像的每个 object proposal 进行特征提取,并写入磁盘.
采用深度网络,比如 VGG16,对 VOC07 trainval 数据集的 5K 张图片,这个过程需要 2.5 GPU-days;且提取的特征需要大量的存储空间.
[3] - 目标检测速度慢.
测试时,对每张测试图片的每个 object proposal 进行特征提取.
基于 VGG16 的检测,单张 GPU 卡,每张图片需要 47s.

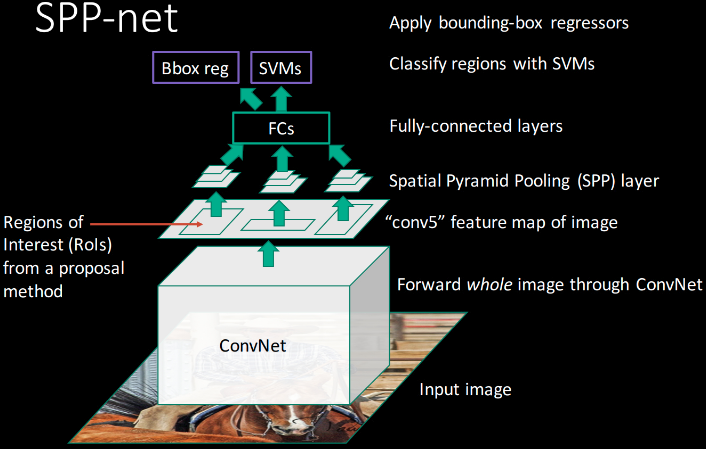
2. SPPNet
由于 R-CNN 需要对每个 object proposal 进行 ConvNet 前向计算,且没有共享计算,造成其速度较慢.
SPPNets,Spatial Pyramid Pooling Networks,通过共享计算来提高 R-CNN 的速度.
SPPNets 对整张输入图片计算一个卷积 feature map,采用从共享特征图(feature map)提取的特征向量来对每个 object proposal 进行分类.
每个 proposal 的特征提取,是采用 max-pooling 将 proposal 的特征图的一部分转换成固定尺寸的输出(fixed-size output, e.g. 6x6) 得到的. 多个输出尺寸采用 pool 操作,并连接为空间金字塔池化(spatial pyramid pooling).
SPPNet 的测试效率,是 R-CNN 的 10 - 100 倍. 由于较快的特征提取速度,训练时间也降低了 3 倍.
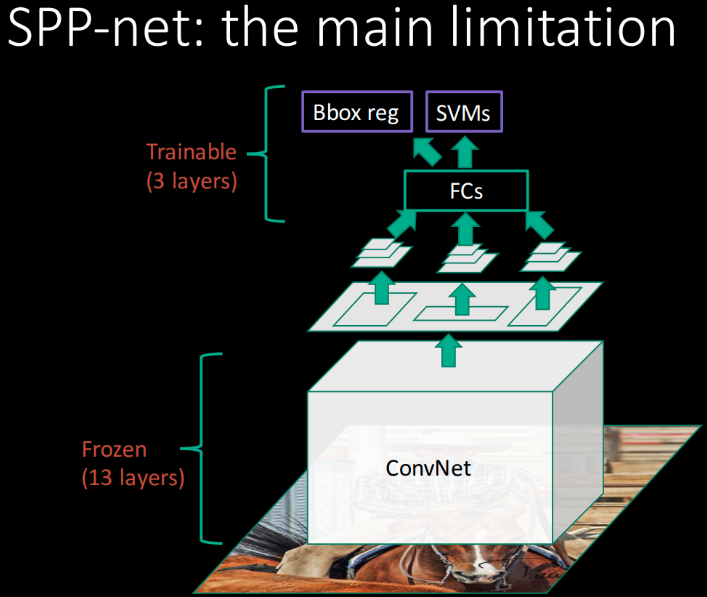
但,SPPNet 的明显缺点在于:
[1] - 类似于 R-CNN,其训练也是 multi-stage 的,包括,特征提取,利用 log loss 微调网络,训练 SVMs 分类器,以及拟合 bounding-box 回归器.
[2] - 特征也需要写入磁盘.
[3] - 与 R-CNN 不同在于,SPPNets 的微调算法不能对 spatial pyramid pooling 的卷积层进行更新,这也就限制了其在深度网络中的精度.

3. Fast R-CNN
相对于 R-CNN 和 SPPNet, Fast R-CNN 解决了以上它们的不足,并提升了速度和精度. 其优势在于,
[1] - 较高的检测质量(mAP)
[2] - 训练是 single-stage 的,采用了 multi-task loss
[3] - 训练可以对整个网络层进行更新
[4] - 不需要磁盘空间来缓存特征.
Fast R-CNN 网络结构为: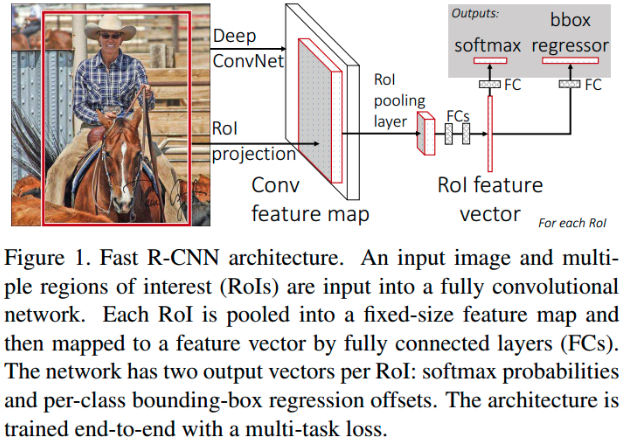
Figure 1. Fast R-CNN 结构. 一张输入图片和多个 RoIs 作为全卷积网络的输入,每个 RoI 被池化到一个固定尺寸的特征图,并采用全连接层映射为一个特征向量. 对于每个 RoI,网络有两个输出向量:softmax 概率和 per-class bounding-box 回归偏移值. 网络是采用 multi-task loss 进行 end-to-end 训练的.
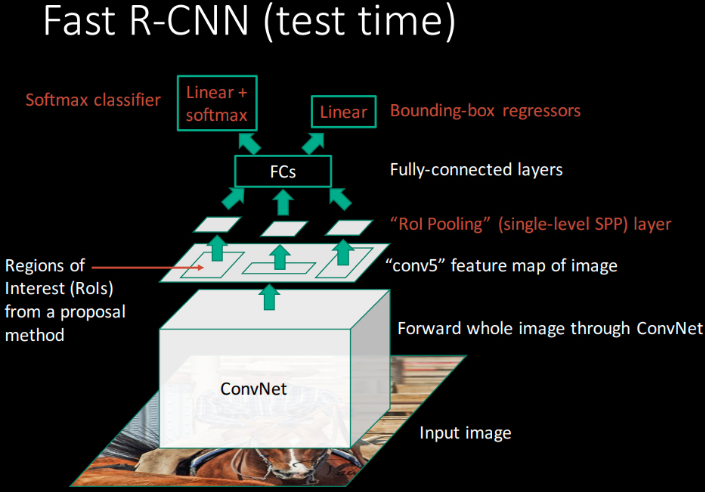
Fast R-CNN 采用整张图片和 object proposals 集作为网络输入.
网络首先几个卷积层和 max-pooling 层对整张图片处理,得到一个 conv feature map.
然后,对每一个 object proposal,采用 RoI pooling 层从 feature map 中提取一个固定长度的特征向量;
每个特征向量被送入一系列的全连接层,最终有两个分支:一个分支得到 softmax 概率值,共 K 个 object 类和一个 background 类;另一个分支针对 K 个 object 类输出四个实值,分别表示了每类 object 的 bounding-box 位置.
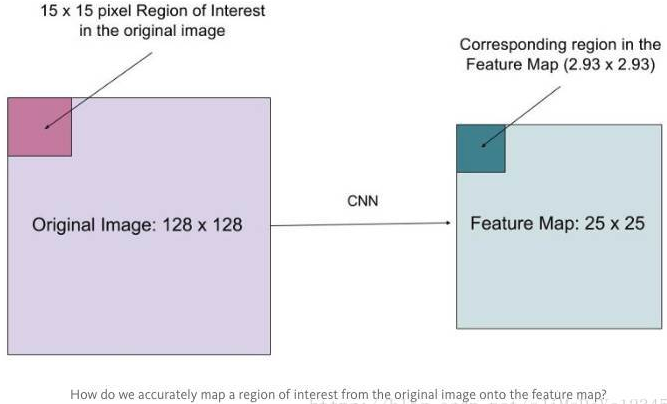
3.1. RoI Pooling 层
RoI pooling 层采用 max-pooling 来将任何有效的 RoI 内的 features 转化为一个小的 feature map,其是固定空间尺寸(HxW, e.g. 7x7)的. 其中 H 和 W 是独立于任何 RoI 超参数.
这里,一个 RoI 是在 conv feature map 的一个方框. 每个 RoI 是由四元组 (r, c, h, w) 定义,分别指定了 RoI 的左上角 (r, c) 和高度和宽度 (h,w).
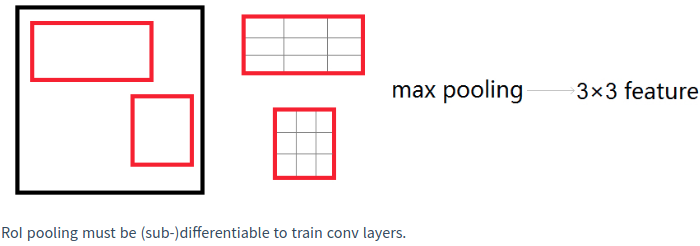
RoI max-pooling 层通过将 hxw 的 RoI windows 分割为 HxW 的 sub-windows 网格,共 (h/H) x (w/W), 并对每个 sub-windows 的值进行 max-pooling 处理,得到对应的输出网格单元. 对每个 feature map channel 分别 pooling 处理,类似于 标准 max-pooling.
RoI 层可以简单的看成 SPPNet 中的 spatial pyramid pooling 层的一种特例.
RoI 是从原图RoI区域映射到卷积区域,最后pooling到固定大小的功能,通过池化把该区域的尺寸归一化成卷积网络输入的尺寸.

3.2 Fast R-CNN 训练
基于在 ImageNet 预训练的网络来初始化 Fast R-CNN 网络.
Fast R-CNN 训练过程中,SGD 先采样 N 张图像,再对每张图片采样 R/N 个 RoIs,以分层采样 mini-batches.
相同图片的 RoIs 在前向和反向传播过程中,共享计算和内存.
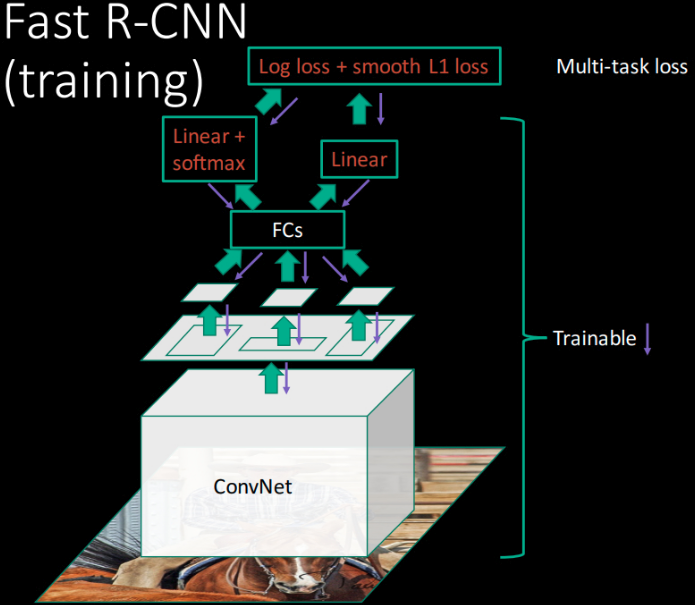
Fast R-CNN 联合训练 softmax 分类器和 bounding-box 回归起,而分别训练 softmax 分类器,SVMs,回归器.
3.2.1. Multi-task loss
Fast R-CNN 网络有两个输出层,一个输出每个 RoI 对 K+1 类object 的离散概率分布,${ p = (p_0,…,p_K) }$. 其中,p 是对全连接层的 K+1 个输出计算的 softmax 概率;
另一个输出 K 个 object 类的 bounding-box 回归偏移值,${ t^k = (t_x^k, t_y^k, t_w^k, t_h^k), k=1,…,K }$.
每个训练 RoI 的标签为 groundtruth class ${ u }$ 和 groundtruth bounding-box regression target ${ v }$.
对每个 labeled RoI,采用 multi-task loss ${ L }$ 联合训练分类和边界框回归:
${ L(p, u, t^u, v) = L_{cls}(p, u) + \lambda[u \geq 1]L_{loc}(t^u, v) }$
其中,
${ L_{cls}(p, u) =-log(p_u) }$ 是对真实 class ${ u }$ 的 log loss.
${ L_{loc}(t^u, v) = \sum_{i \in {x, y, w, h}} smooth_{L1}(t_i^u- v_i) }$
${ if \ |x| \leq 1, \ smooth_{L1}(x) = 0.5x^2, \ otherwise, \ smooth_{L1}(x) = |x|-0.5 }$
${ \lambda }$ 控制两个 task losses 的权重. 这里,${ \lambda = 1 }$.
3.2.2 Mini-batch 采样
Fast R-CNN 微调过程中,每个 SGD 的 mini-batch 是随机选取的 N=2 张图片.
这里采用 R=128 的 mini-batches,每张图片采样 64 RoIs.
选取与 groundtruth bounding box 的 IoU(intersection over union) 大于 0.5 的 object proposals 的 25%. 这些 RoIs 由 标注了前景 object class 的 样本组成,${ u \geq 1 }$.
剩下的 RoIs 是从与 groundtruth 的最大 IoU 值在区间 [0.1, 0.5] 的 object proposals 中采样得到. 这些 RoIs 的样本标签是背景类,${ u=0 }$.
IoU 阈值小于 0.1 的样本作为 hard example mining.
网络训练时,图片随机水平翻转. 无其它数据增广处理.



3.2.3. RoI pooling 层的 BP 反向传播
假设每个 mini-batch 只有一张图片,N=1. 由于RoI 前向传播是将 mini-batch 内的多张图片单独处理,其反向传播,只需将 N>1 直接扩展即可.
记 RoI Pooling 层的第 ${ i }$ 个激活输入为 ${ x_i \in R }$,第 ${ r }$ 个 RoI 的第 ${ j }$ 个输出为 ${ y_{rj} }$.
RoI Pooling 层计算 ${ y_{rj} = x_{i*(r, j)} }$,其中 ${ i^\ast (r, j) = argmax_{i^{\
prime} \in R(r, j)} x_{i\prime} }$, ${ R(r, j) }$ 是 sub-window 内输入的索引集,在该 sub-window 内,采用 max pooling 对输出单元 ${ y_{rj} }$ 进行处理. 单个 ${ x_i }$ 可能有多个不同输出 ${ y_{rj} }$.
RoI pooling 层的 backwards 函数是计算 loss 函数分别关于每个输入 ${ x_i }$ 的偏微分:
${ \frac{\partial L}{\partial x_i} = \sum_r \sum_j [i = i^*(r, j)] \frac{\partial L}{ \partial y_{rj}} }$
对于每个 mini-batch 的 RoI ${ r }$ 和 每个 pooling 输出 ${ y_{rj} }$,偏微分 ${ \partial L / \partial y_{rj} }$ 是 max pooling 时所选取的 ${ i }$ 的累加.
在反向传播时,偏微分 ${ \partial L / \partial y_{rj} }$ 已经由 RoI pooling 层的输出层的 backwards 函数计算.
3.3. Fast R-CNN 检测
Fast R-CNN 模型训练后,假设 object proposals 已经计算得到,只需要一次 forward pass. 输入是一张图片和 一个包含 R 个 object proposals 的列表. 测试时,R 一般取值 2000.
对于每个测试 RoI r },网络输出一个类别后验概率分布 p 和所预测的一个相对于 r 的 bounding-box 偏移值,K 类 objects 分别得到对应的 bounding-box 预测值.
采用估计的概率 ${ Pr(class = k | r ) = p_k }$ 来设定每个 object 类 k 的检测置信度. 再对每一类分别采用 NMS 算法(non-maximum suppression) 进行处理.
3.3.1. 截断 SVD 加快检测速度
对于整张图片的分类,全连接层的耗时相对于卷积层来说是很少的. 但是对于检测问题,需要处理的 RoIs 的数量较多,几乎将近一半的 forward 时间都花在全连接层. 采用 truncated SVD 对全连接层进行压缩可以较容易的加快速度.
权重参数 W,u×v,利用SVD,其逼近分解形式为:
${ W \approx U \sum_t V^T }$
其中,U 是 u×t 的矩阵,由 W 的前 t 个左奇异向量组成;${ \sum_t }$ 是 t×t 对角矩阵, 其值是 W 的最大的 t 个奇异值;V 是 v×t 的矩阵,由 W 的前 t 个由奇异向量组成.
SVD 将参数数量由 ${ uv }$ 减少到 ${ t(u+v) }$.
为了压缩网络,单个全连接层 W 被替换为两个全连接层,二者之间不设非线性变换层. 第一个全连接层采用权重矩阵 ${ \sum_t V^T }$ (无 biases),第二个全连接层采用全中矩阵 U (与 W 相关的原始 biases).
当 RoIs 数量较多时,这种方法能够很好的加快检测速度.
如图:
3.4. 训练网络结构
models/coco/VGG16/fast_rcnn/train.prototxt

3.5. 测试网络结构
models/coco/VGG16/fast_rcnn/test.prototxt

Reference
[1] - 【目标检测】Fast RCNN算法详解
[2] - NMS-python
2 条评论
想问一下博主文中黑色背景的图片是在别处找的还是您自己用什么工具画的?OωO
在别处找的,PPT 中的.