题目: ResNeXt - Aggregated Residual Transformations for Deep Neural Networks - CVPR2017
作者: Saining Xie, Ross Girshick, Piotr Dollar, Zhuowen Tu, Kaiming He
团队: UC San Diego, Facebook AI Research
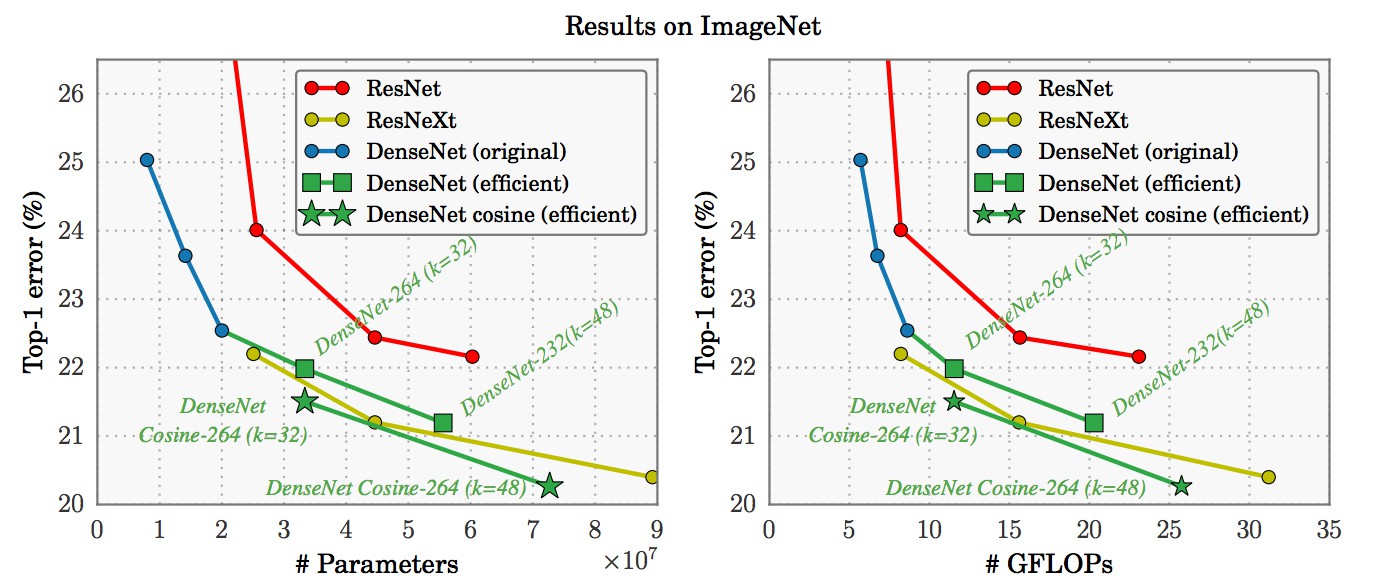
高度模块化的网络结构,用于图像分类;
堆叠 build block 来构建网络,每个 build block 聚合了具有相同拓扑结构的变换集;
ResNeXt中,同类、multi-branch 结构的设计具有更少的参数. 引入了新的维度,即 Cardinality(涉及的变换集的尺寸),作为网络 depth 和 width 维度之外的一种必要因子.特点:
- 基于 ImageNet-1K 数据集,实验结果表明,在严格保证计算复杂度时,增加 Cardinality 能够提高图像分类精度;且,增加 Cardinality 比加深或者加宽网络结构更有效.
- 与 ResNet 相比,相同的精度, ResNeXt 计算量更少,参数更少. ResNeXt-50 接近 ResNet-101 的准确度.
- ResNeXt 网络模块化设计更合理,结构更简单,超参数量更少.
VGG-nets/ResNets: 堆叠相同形状的网络 building blocks;—— 网络 depth
Inceptions:split-transform-merge,将输入采用(1×1 Conv)分裂为几个低维 embedding,再经过一系列特定 filters (如3×3,5×5)的变换,最后连接在一起.
ResNeXt:采用 VGGs/ResNets 的网络的 depth 加深方式,同时利用 split-transform-merge 策略.
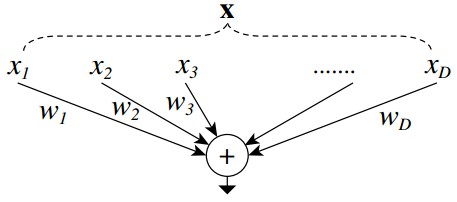
1. Simple Neurons
ANN 中最简单的 neurons 是 inner product(内积),其也可以看做是 aggregating transformation(聚合变换):
${ \sum _{i=1}^D w_i x_i }$
其中,${ \mathbf{x} = [x_1, x_2,...,x_D] }$,D-channel 输入向量; ${ w_i }$ 是第 i 个 channel 的 filter 权重.
内积计算Inner product 可以看作是 splitting-transforming-aggregating 的组合:(1) Splitting:输入向量 ${ \mathbf{x} }$ 被分为低维 embedding,即单维空间的 ${ x_i }$;(2) Transforming:变换得到低维表示,即:${ w_i x_i }$;(3) Aggregating: 通过相加将所有的 embeddings 变换聚合,即${ \sum_{i=1}^D }$.
2. Aggregated Transformations 聚合变换
根据上面的分析,可以将逐元素变换 ${ w_i x_i }$ 替换为函数或网络.
aggregated transformations 表示为:
${ \mathcal{F} (\mathbf{x}) = \sum _{i=1}^C \mathcal{T} (\mathbf{x}) }$
其中,${ \mathcal{T} (\mathbf{x}) }$ 可以是任意函数,其将 ${ \mathbf{x} }$ 投影到一个嵌入空间(一般是低维空间),并进行变换.
${ C }$ 是待聚合的变换集的大小,即 Cardinality. 类似于 ${ D }$.
Cardinality 的维度决定了更复杂变换的数目.
对于变换函数的设计,采用策略是:所有的 ${ \mathcal{T}_i }$ 拓扑结构相同.
基于 residual 函数的 aggregated transformation:
${ \mathbf{y} = \mathbf{x} + \sum_{i=1}^C \mathcal{T}_i (\mathbf{x}) }$
${ \mathbf{y} }$ 为输出.
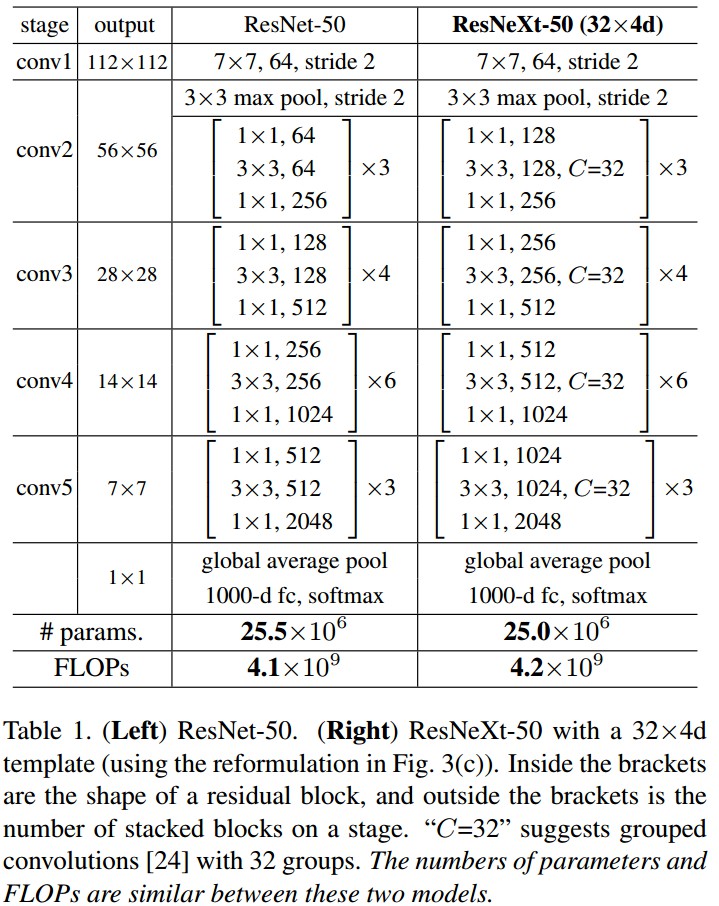
2.1 ResNet-50 && ResNeXt-50
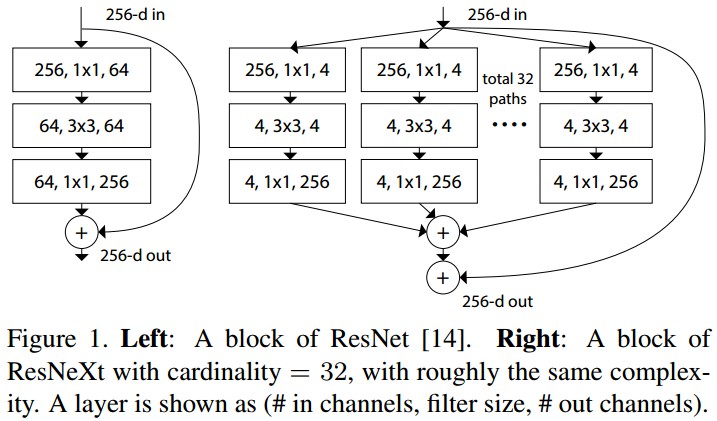
Figure 1. Left - ResNet 的一个 block;Right - ResNeXt 的一个块,Cardinality=32. 二者复杂度相同.(#in_channels, #filter_size,#out_channels).
- 如果 spatial maps 是相同尺寸,blocks 共享相同的参数(width 和 filter sizes)
- 每次当 spatial map 基于因子 2 进行下采样时,blocks 的 width 乘上因子 2.
ResNeXt 保留 ResNet 的堆叠 block,而是对单个 building block 改进.
2.2 ResNeXt && Inception-ResNet && Grouped Convolutions
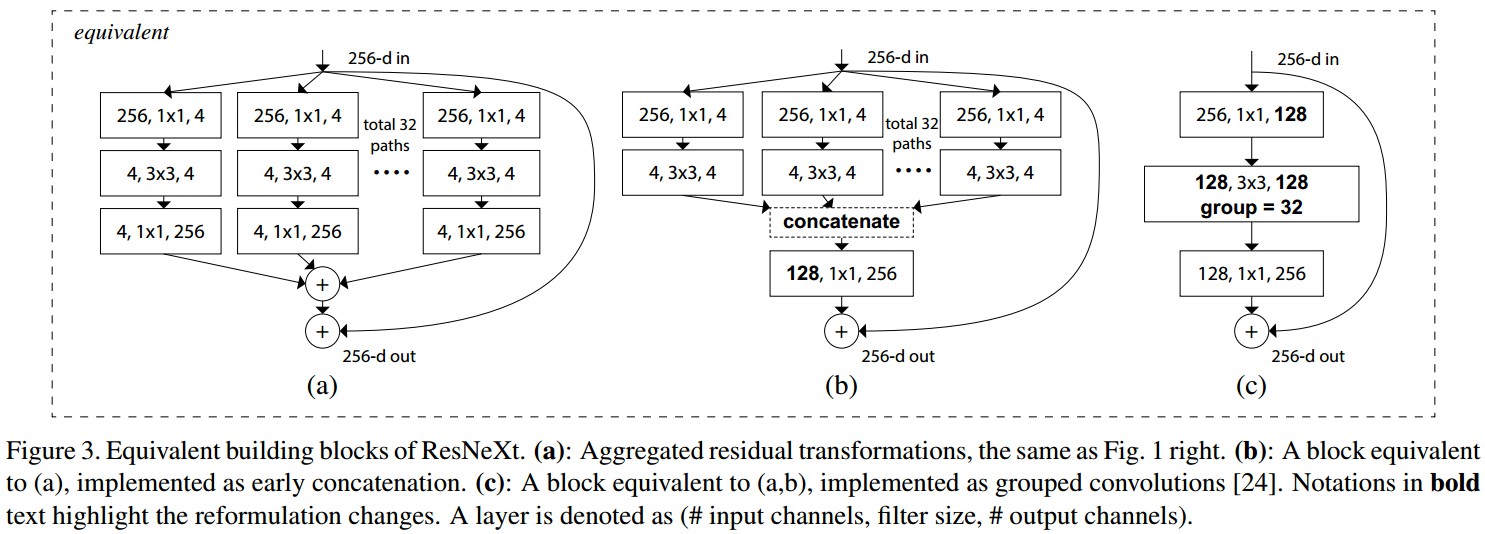
Figure 3. ResNeXt building blocks 的等价形式. (a) Figure 1 Right 的 Aggregated transformations;(b) 采用提前进行加法操作的等价形式;(c) 采用 grouped conv 的等价形式.
Grouped Convolutions:group conv 层中,输入和输出的 channels 被分为 ${ C }$ 个 groups,分别对每个 group 进行 conv.
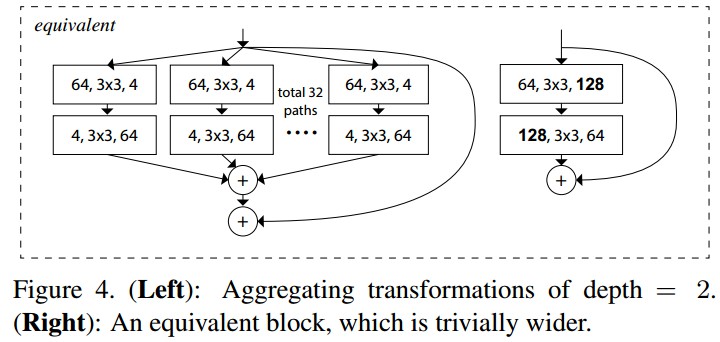
ResNeXt 只能在 block 的 depth>3时使用. 如果 block 的 depth=2,则会得到宽而密集的模块.
2.3 参数
Figure 1 Left 中的 ResNet block参数:${ 256 \cdot 64 + 3 \cdot 3 \cdot 64 \cdot 64 + 64 \cdot 256 \approx 70K }$.
Figure 1 Right 中 ResNeXt block 参数:${ C \cdot (256 \cdot d + 3 \cdot 3 \cdot d \cdot d + d \cdot 256) }$. 当 C = 32,d=4 时,参数约有 70K.

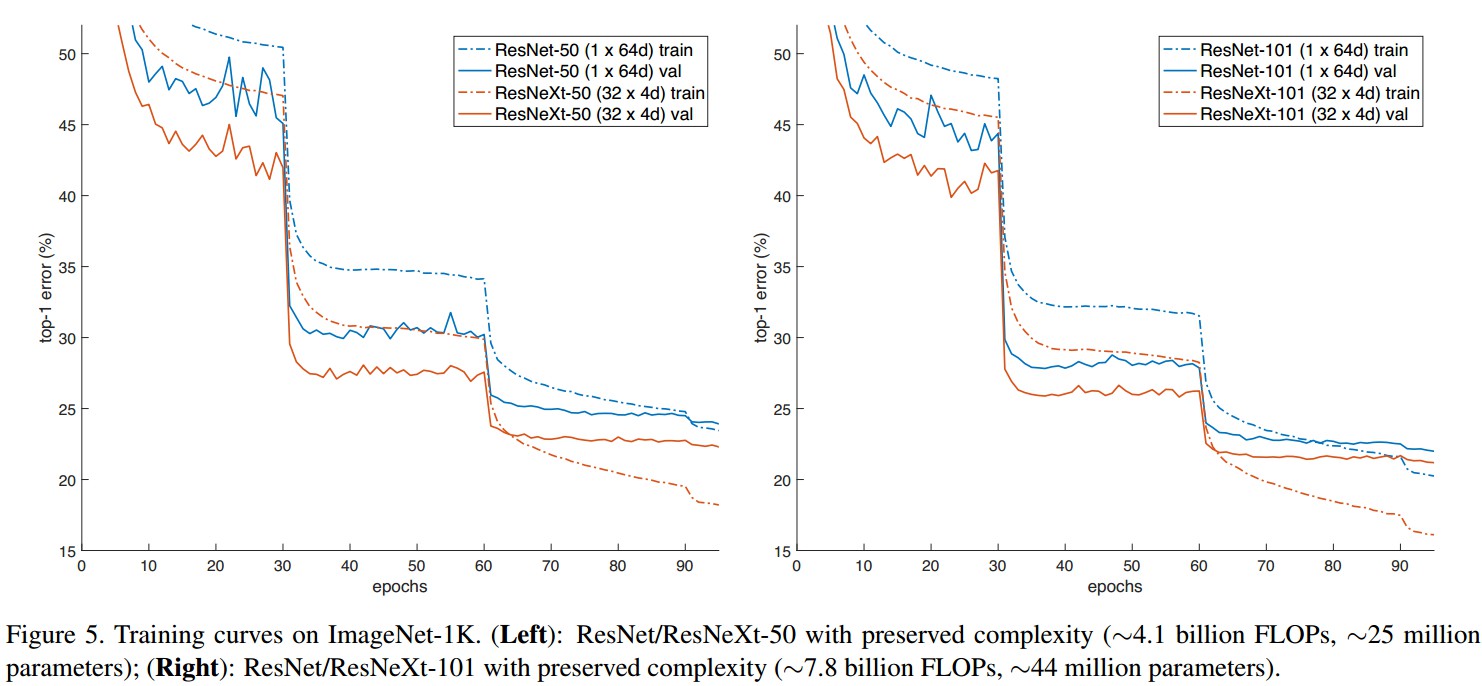
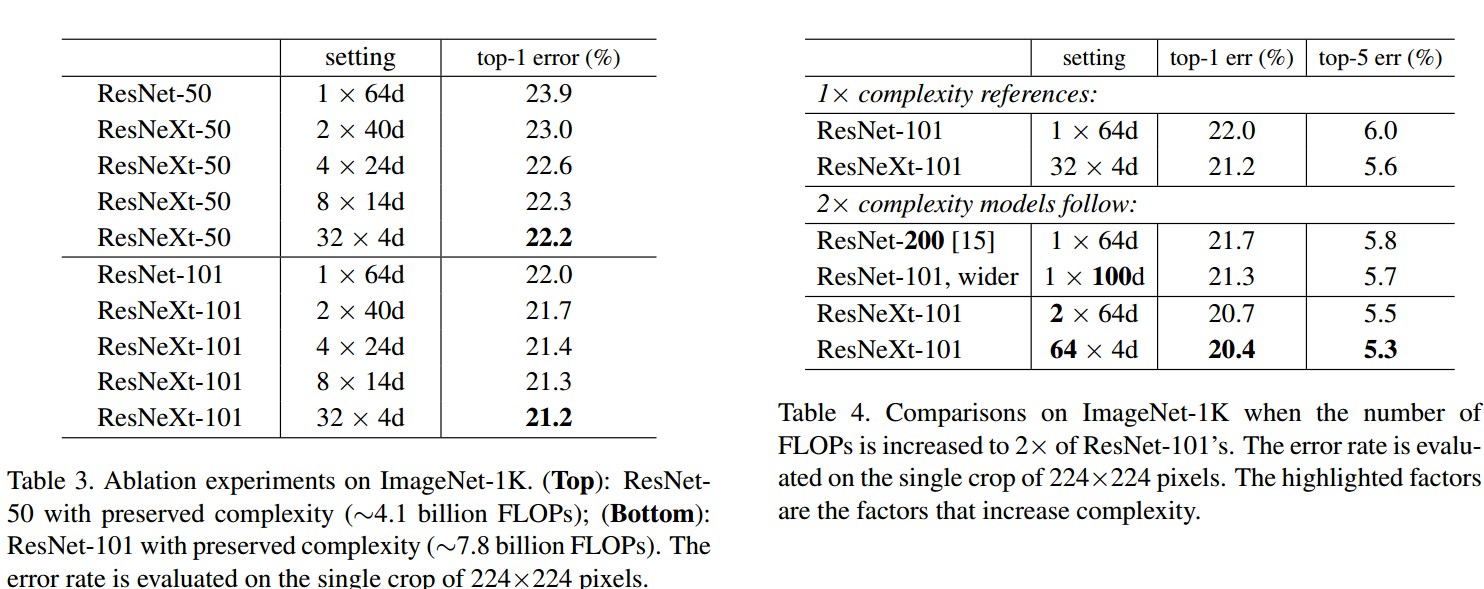
3. Results
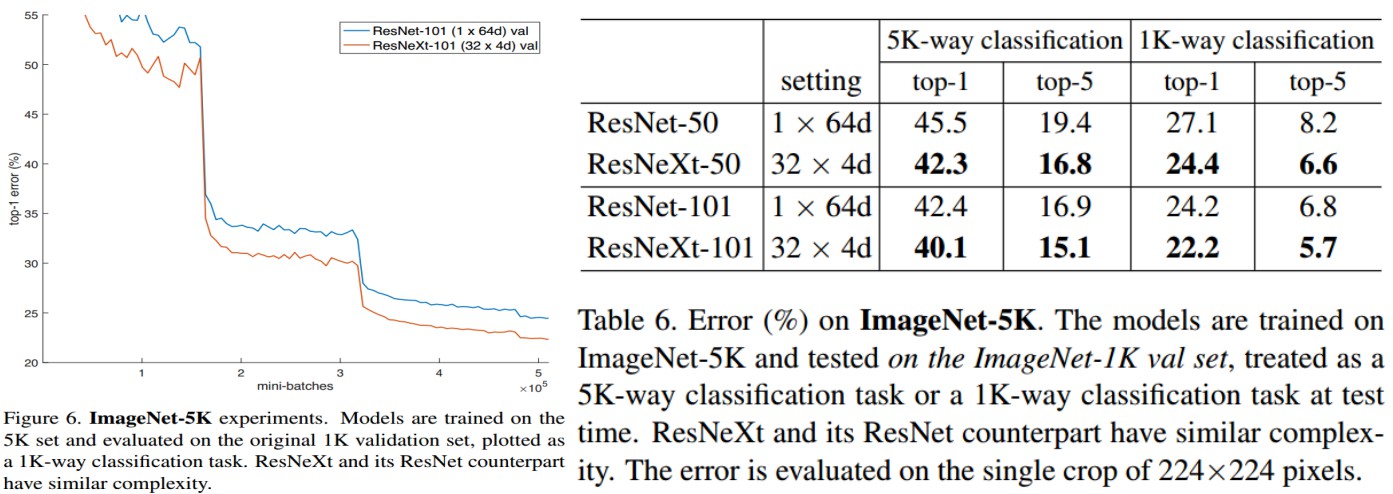
4. 基于 ResNeXt 的 Faster R-CNN 实现
- 采用 Faster R-CNN框架;
- 不共享 RPN 和 Fast R-CNN 的特征;
- RPN 阶段,在 8-GPUs 上训练,每个 GPU min-batch为 2 张图片,每张图片 256 个 anchors;
- RPN 训练阶段,前 120k mini-batches 的学习率为 learning_rate=0.02,后面 60K mini-batches 学习率为 learning_rate=0.002;
- Fast R-CNN 阶段,在 8-GPUs 上训练,每个 GPU 1张图片,每个 mini-batch 64 个regions;
- Fast R-CNN 训练阶段,前120k mini-batches 的学习率为 learning_rate=0.005,后面 60K mini-batches 学习率为 learning_rate=0.0005;
- weight_decay=0.0001,momentum=0.9.
- 其它实现类似于 Faster R-CNN.
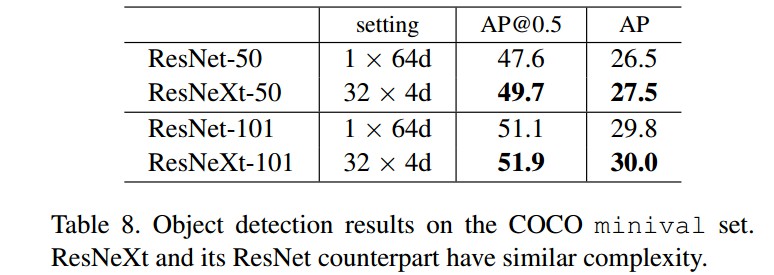
4.1 COCO 目标检测
5 Reference
[1] - ResNeXt算法详解
[2] - ResNext与Xception——对模型的新思考